 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocal-RegionFace: Generating Fine-Grained Multi-attribute Descriptions for Arbitrarily Selected Face Focal Regions
Jan 01, 2026In this paper, we introduce an underexplored problem in facial analysis: generating and recognizing multi-attribute natural language descriptions, containing facial action units (AUs), emotional states, and age estimation, for arbitrarily selected face regions (termed FaceFocalDesc). We argue that the system's ability to focus on individual facial areas leads to better understanding and control. To achieve this capability, we construct a new multi-attribute description dataset for arbitrarily selected face regions, providing rich region-level annotations and natural language descriptions. Further, we propose a fine-tuned vision-language model based on Qwen2.5-VL, called Focal-RegionFace for facial state analysis, which incrementally refines its focus on localized facial features through multiple progressively fine-tuning stages, resulting in interpretable age estimation, FAU and emotion detection. Experimental results show that Focal-RegionFace achieves the best performance on the new benchmark in terms of traditional and widely used metrics, as well as new proposed metrics. This fully verifies its effectiveness and versatility in fine-grained multi-attribute face region-focal analysis scenarios.
HpEIS: Learning Hand Pose Embeddings for Multimedia Interactive Systems
Oct 11, 2024



We present a novel Hand-pose Embedding Interactive System (HpEIS) as a virtual sensor, which maps users' flexible hand poses to a two-dimensional visual space using a Variational Autoencoder (VAE) trained on a variety of hand poses. HpEIS enables visually interpretable and guidable support for user explorations in multimedia collections, using only a camera as an external hand pose acquisition device. We identify general usability issues associated with system stability and smoothing requirements through pilot experiments with expert and inexperienced users. We then design stability and smoothing improvements, including hand-pose data augmentation, an anti-jitter regularisation term added to loss function, stabilising post-processing for movement turning points and smoothing post-processing based on One Euro Filters. In target selection experiments (n=12), we evaluate HpEIS by measures of task completion time and the final distance to target points, with and without the gesture guidance window condition. Experimental responses indicate that HpEIS provides users with a learnable, flexible, stable and smooth mid-air hand movement interaction experience.
3SHNet: Boosting Image-Sentence Retrieval via Visual Semantic-Spatial Self-Highlighting
Apr 26, 2024



In this paper, we propose a novel visual Semantic-Spatial Self-Highlighting Network (termed 3SHNet) for high-precision, high-efficiency and high-generalization image-sentence retrieval. 3SHNet highlights the salient identification of prominent objects and their spatial locations within the visual modality, thus allowing the integration of visual semantics-spatial interactions and maintaining independence between two modalities. This integration effectively combines object regions with the corresponding semantic and position layouts derived from segmentation to enhance the visual representation. And the modality-independence guarantees efficiency and generalization. Additionally, 3SHNet utilizes the structured contextual visual scene information from segmentation to conduct the local (region-based) or global (grid-based) guidance and achieve accurate hybrid-level retrieval. Extensive experiments conducted on MS-COCO and Flickr30K benchmarks substantiate the superior performances, inference efficiency and generalization of the proposed 3SHNet when juxtaposed with contemporary state-of-the-art methodologies. Specifically, on the larger MS-COCO 5K test set, we achieve 16.3%, 24.8%, and 18.3% improvements in terms of rSum score, respectively, compared with the state-of-the-art methods using different image representations, while maintaining optimal retrieval efficiency. Moreover, our performance on cross-dataset generalization improves by 18.6%. Data and code are available at https://github.com/XuriGe1995/3SHNet.
* Accepted Information Processing and Management (IP&M), 10 pages, 9 figures and 8 tables
Cross-modal Semantic Enhanced Interaction for Image-Sentence Retrieval
Oct 17, 2022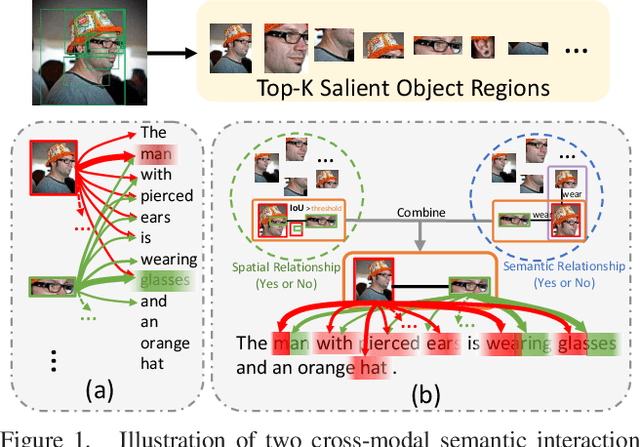
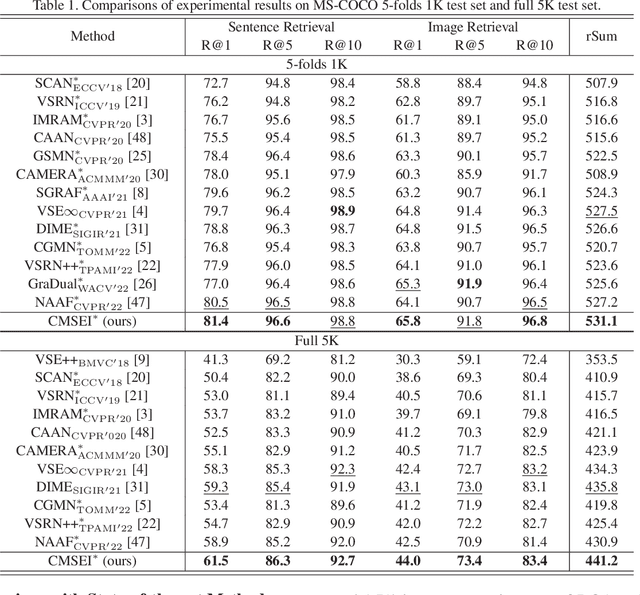
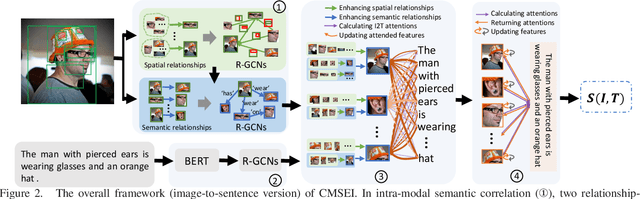
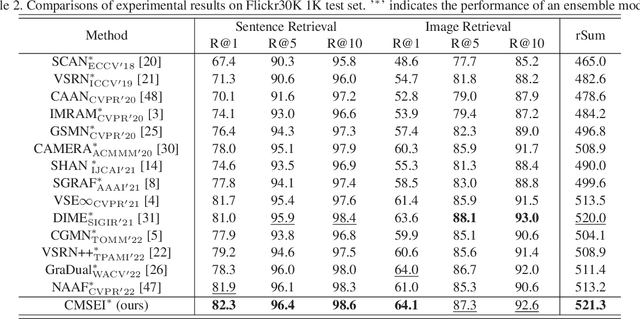
Image-sentence retrieval has attracted extensive research attention in multimedia and computer vision due to its promising application. The key issue lies in jointly learning the visual and textual representation to accurately estimate their similarity. To this end, the mainstream schema adopts an object-word based attention to calculate their relevance scores and refine their interactive representations with the attention features, which, however, neglects the context of the object representation on the inter-object relationship that matches the predicates in sentences. In this paper, we propose a Cross-modal Semantic Enhanced Interaction method, termed CMSEI for image-sentence retrieval, which correlates the intra- and inter-modal semantics between objects and words. In particular, we first design the intra-modal spatial and semantic graphs based reasoning to enhance the semantic representations of objects guided by the explicit relationships of the objects' spatial positions and their scene graph. Then the visual and textual semantic representations are refined jointly via the inter-modal interactive attention and the cross-modal alignment. To correlate the context of objects with the textual context, we further refine the visual semantic representation via the cross-level object-sentence and word-image based interactive attention. Experimental results on seven standard evaluation metrics show that the proposed CMSEI outperforms the state-of-the-art and the alternative approaches on MS-COCO and Flickr30K benchmarks.
MGRR-Net: Multi-level Graph Relational Reasoning Network for Facial Action Units Detection
Apr 08, 2022



The Facial Action Coding System (FACS) encodes the action units (AUs) in facial images, which has attracted extensive research attention due to its wide use in facial expression analysis. Many methods that perform well on automatic facial action unit (AU) detection primarily focus on modeling various types of AU relations between corresponding local muscle areas, or simply mining global attention-aware facial features, however, neglect the dynamic interactions among local-global features. We argue that encoding AU features just from one perspective may not capture the rich contextual information between regional and global face features, as well as the detailed variability across AUs, because of the diversity in expression and individual characteristics. In this paper, we propose a novel Multi-level Graph Relational Reasoning Network (termed MGRR-Net) for facial AU detection. Each layer of MGRR-Net performs a multi-level (i.e., region-level, pixel-wise and channel-wise level) feature learning. While the region-level feature learning from local face patches features via graph neural network can encode the correlation across different AUs, the pixel-wise and channel-wise feature learning via graph attention network can enhance the discrimination ability of AU features from global face features. The fused features from the three levels lead to improved AU discriminative ability. Extensive experiments on DISFA and BP4D AU datasets show that the proposed approach achieves superior performance than the state-of-the-art methods.