 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidating Computational Markers of Depressive Behavior: Cross-Linguistic Speech-Based Depression Detection with Neurophysiological Validation
Apr 02, 2026Speech-based depression detection has shown promise as an objective diagnostic tool, yet the cross-linguistic robustness of acoustic markers and their neurobiological underpinnings remain underexplored. This study extends Cross-Data Multilevel Attention (CDMA) framework, initially validated on Italian, to investigate these dimensions using a Chinese Mandarin dataset with Electroencephalography (EEG) recordings. We systematically fuse read speech with spontaneous speech across different emotional valences (positive, neutral, negative) to investigate whether emotional arousal is a more critical factor than valence polarity in enhancing detection performance in speech. Additionally, we establish the first neurophysiological validation for a speech-based depression model by correlating its predictions with neural oscillatory patterns during emotional face processing. Our results demonstrate strong cross-linguistic generalizability of the CDMA framework, achieving state-of-the-art performance (F1-score up to 89.6%) on the Chinese dataset, which is comparable to the previous Italian validation. Critically, emotionally valenced speech (both positive and negative) significantly outperformed neutral speech. This comparable performance between positive and negative tasks supports the emotional arousal hypothesis. Most importantly, EEG analysis revealed significant correlations between the model's speech-derived depression estimates and neural oscillatory patterns (theta and alpha bands), demonstrating alignment with established neural markers of emotional dysregulation in depression. This alignment, combined with the model's cross-linguistic robustness, not only supports that the CDMA framework's approach is a universally applicable and neurobiologically validated strategy but also establishes a novel paradigm for the neurophysiological validation of computational mental health models.
CognoSpeak: an automatic, remote assessment of early cognitive decline in real-world conversational speech
Jan 10, 2025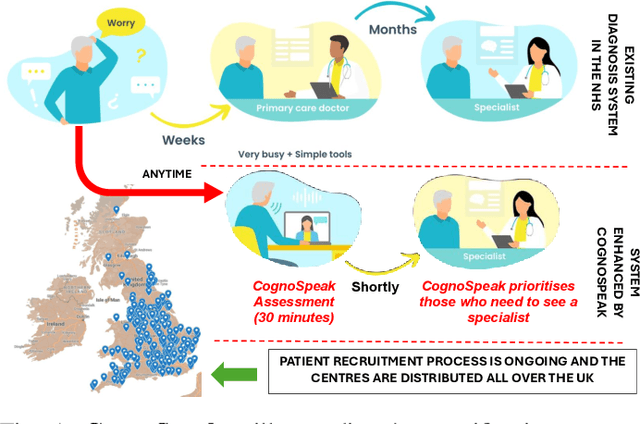
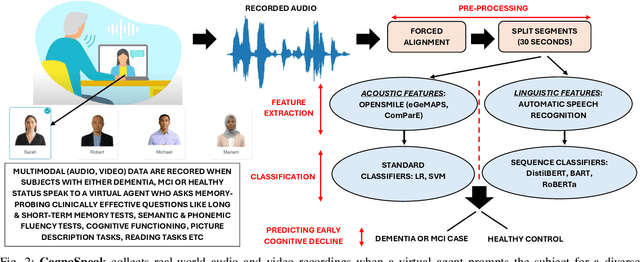
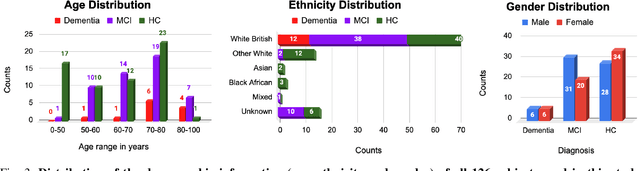
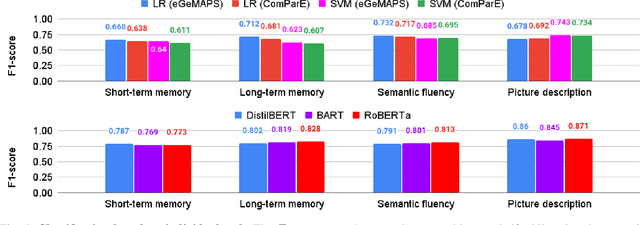
The early signs of cognitive decline are often noticeable in conversational speech, and identifying those signs is crucial in dealing with later and more serious stages of neurodegenerative diseases. Clinical detection is costly and time-consuming and although there has been recent progress in the automatic detection of speech-based cues, those systems are trained on relatively small databases, lacking detailed metadata and demographic information. This paper presents CognoSpeak and its associated data collection efforts. CognoSpeak asks memory-probing long and short-term questions and administers standard cognitive tasks such as verbal and semantic fluency and picture description using a virtual agent on a mobile or web platform. In addition, it collects multimodal data such as audio and video along with a rich set of metadata from primary and secondary care, memory clinics and remote settings like people's homes. Here, we present results from 126 subjects whose audio was manually transcribed. Several classic classifiers, as well as large language model-based classifiers, have been investigated and evaluated across the different types of prompts. We demonstrate a high level of performance; in particular, we achieved an F1-score of 0.873 using a DistilBERT model to discriminate people with cognitive impairment (dementia and people with mild cognitive impairment (MCI)) from healthy volunteers using the memory responses, fluency tasks and cookie theft picture description. CognoSpeak is an automatic, remote, low-cost, repeatable, non-invasive and less stressful alternative to existing clinical cognitive assessments.
The Relationship Between Speech Features Changes When You Get Depressed: Feature Correlations for Improving Speed and Performance of Depression Detection
Jul 07, 2023


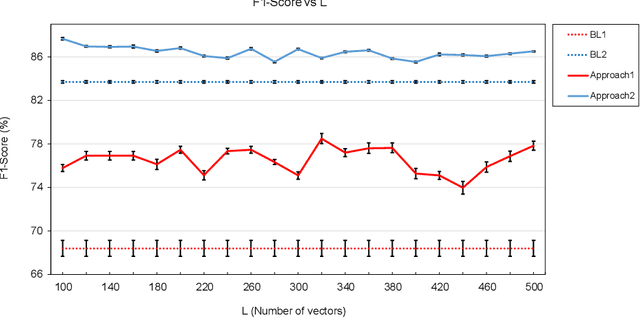
This work shows that depression changes the correlation between features extracted from speech. Furthermore, it shows that using such an insight can improve the training speed and performance of depression detectors based on SVMs and LSTMs. The experiments were performed over the Androids Corpus, a publicly available dataset involving 112 speakers, including 58 people diagnosed with depression by professional psychiatrists. The results show that the models used in the experiments improve in terms of training speed and performance when fed with feature correlation matrices rather than with feature vectors. The relative reduction of the error rate ranges between 23.1% and 26.6% depending on the model. The probable explanation is that feature correlation matrices appear to be more variable in the case of depressed speakers. Correspondingly, such a phenomenon can be thought of as a depression marker.
Cross-modal Semantic Enhanced Interaction for Image-Sentence Retrieval
Oct 17, 2022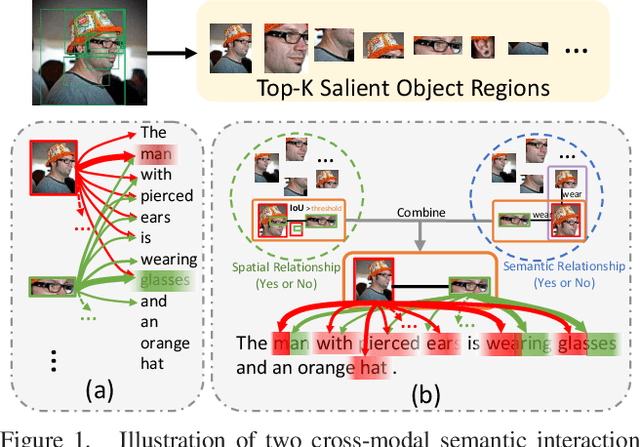
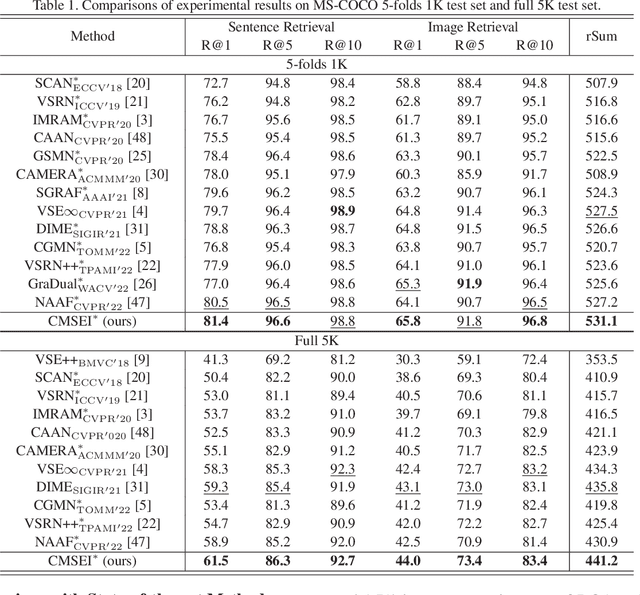
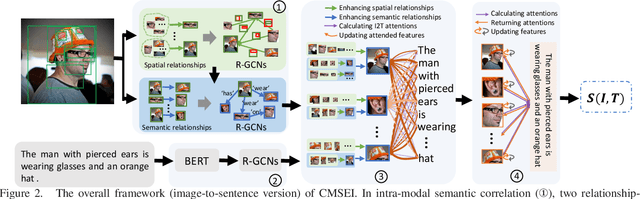
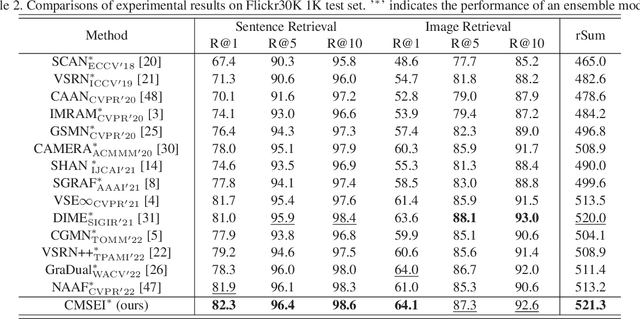
Image-sentence retrieval has attracted extensive research attention in multimedia and computer vision due to its promising application. The key issue lies in jointly learning the visual and textual representation to accurately estimate their similarity. To this end, the mainstream schema adopts an object-word based attention to calculate their relevance scores and refine their interactive representations with the attention features, which, however, neglects the context of the object representation on the inter-object relationship that matches the predicates in sentences. In this paper, we propose a Cross-modal Semantic Enhanced Interaction method, termed CMSEI for image-sentence retrieval, which correlates the intra- and inter-modal semantics between objects and words. In particular, we first design the intra-modal spatial and semantic graphs based reasoning to enhance the semantic representations of objects guided by the explicit relationships of the objects' spatial positions and their scene graph. Then the visual and textual semantic representations are refined jointly via the inter-modal interactive attention and the cross-modal alignment. To correlate the context of objects with the textual context, we further refine the visual semantic representation via the cross-level object-sentence and word-image based interactive attention. Experimental results on seven standard evaluation metrics show that the proposed CMSEI outperforms the state-of-the-art and the alternative approaches on MS-COCO and Flickr30K benchmarks.