 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwenty Years of Personality Computing: Threats, Challenges and Future Directions
Mar 03, 2025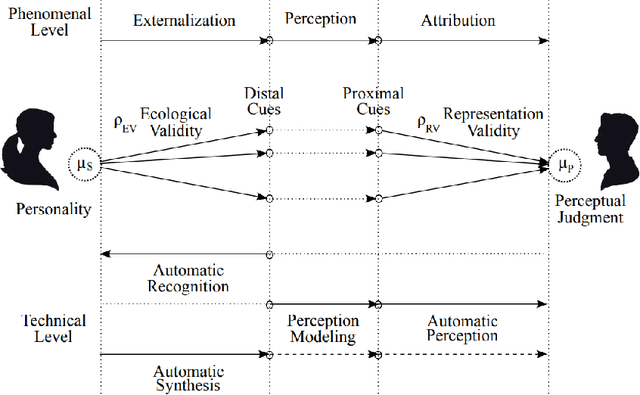
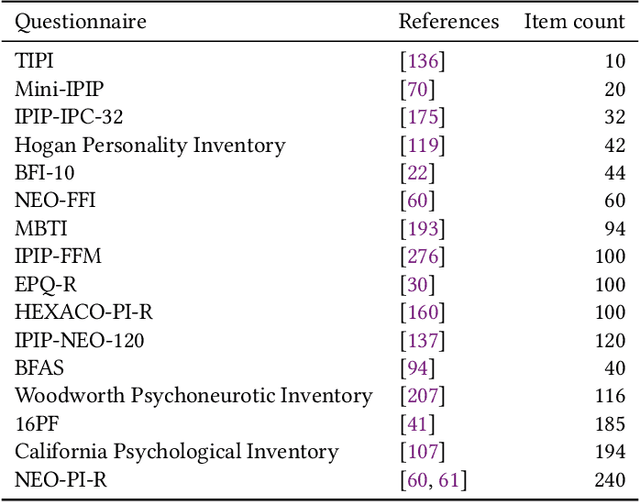
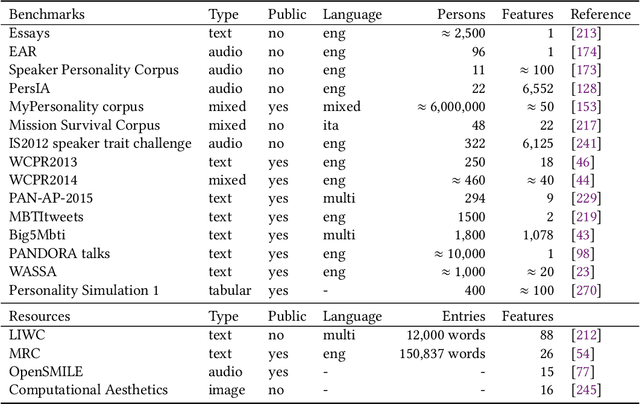
Personality Computing is a field at the intersection of Personality Psychology and Computer Science. Started in 2005, research in the field utilizes computational methods to understand and predict human personality traits. The expansion of the field has been very rapid and, by analyzing digital footprints (text, images, social media, etc.), it helped to develop systems that recognize and even replicate human personality. While offering promising applications in talent recruiting, marketing and healthcare, the ethical implications of Personality Computing are significant. Concerns include data privacy, algorithmic bias, and the potential for manipulation by personality-aware Artificial Intelligence. This paper provides an overview of the field, explores key methodologies, discusses the challenges and threats, and outlines potential future directions for responsible development and deployment of Personality Computing technologies.
Exploring 3D Human Pose Estimation and Forecasting from the Robot's Perspective: The HARPER Dataset
Mar 23, 2024



We introduce HARPER, a novel dataset for 3D body pose estimation and forecast in dyadic interactions between users and Spot, the quadruped robot manufactured by Boston Dynamics. The key-novelty is the focus on the robot's perspective, i.e., on the data captured by the robot's sensors. These make 3D body pose analysis challenging because being close to the ground captures humans only partially. The scenario underlying HARPER includes 15 actions, of which 10 involve physical contact between the robot and users. The Corpus contains not only the recordings of the built-in stereo cameras of Spot, but also those of a 6-camera OptiTrack system (all recordings are synchronized). This leads to ground-truth skeletal representations with a precision lower than a millimeter. In addition, the Corpus includes reproducible benchmarks on 3D Human Pose Estimation, Human Pose Forecasting, and Collision Prediction, all based on publicly available baseline approaches. This enables future HARPER users to rigorously compare their results with those we provide in this work.
The Relationship Between Speech Features Changes When You Get Depressed: Feature Correlations for Improving Speed and Performance of Depression Detection
Jul 07, 2023


This work shows that depression changes the correlation between features extracted from speech. Furthermore, it shows that using such an insight can improve the training speed and performance of depression detectors based on SVMs and LSTMs. The experiments were performed over the Androids Corpus, a publicly available dataset involving 112 speakers, including 58 people diagnosed with depression by professional psychiatrists. The results show that the models used in the experiments improve in terms of training speed and performance when fed with feature correlation matrices rather than with feature vectors. The relative reduction of the error rate ranges between 23.1% and 26.6% depending on the model. The probable explanation is that feature correlation matrices appear to be more variable in the case of depressed speakers. Correspondingly, such a phenomenon can be thought of as a depression marker.
Handwriting and Drawing for Depression Detection: A Preliminary Study
Feb 05, 2023The events of the past 2 years related to the pandemic have shown that it is increasingly important to find new tools to help mental health experts in diagnosing mood disorders. Leaving aside the longcovid cognitive (e.g., difficulty in concentration) and bodily (e.g., loss of smell) effects, the short-term covid effects on mental health were a significant increase in anxiety and depressive symptoms. The aim of this study is to use a new tool, the online handwriting and drawing analysis, to discriminate between healthy individuals and depressed patients. To this aim, patients with clinical depression (n = 14), individuals with high sub-clinical (diagnosed by a test rather than a doctor) depressive traits (n = 15) and healthy individuals (n = 20) were recruited and asked to perform four online drawing /handwriting tasks using a digitizing tablet and a special writing device. From the raw collected online data, seventeen drawing/writing features (categorized into five categories) were extracted, and compared among the three groups of the involved participants, through ANOVA repeated measures analyses. Results shows that Time features are more effective in discriminating between healthy and participants with sub-clinical depressive characteristics. On the other hand, Ductus and Pressure features are more effective in discriminating between clinical depressed and healthy participants.
Face-to-Face Co-Located Human-Human Social Interaction Analysis using Nonverbal Cues: A Survey
Jul 20, 2022



This work presents a systematic review of recent efforts (since 2010) aimed at automatic analysis of nonverbal cues displayed in face-to-face co-located human-human social interactions. The main reason for focusing on nonverbal cues is that these are the physical, machine detectable traces of social and psychological phenomena. Therefore, detecting and understanding nonverbal cues means, at least to a certain extent, to detect and understand social and psychological phenomena. The covered topics are categorized into three as: a) modeling social traits, such as leadership, dominance, personality traits, b) social role recognition and social relations detection and c) interaction dynamics analysis in terms of group cohesion, empathy, rapport and so forth. We target the co-located interactions, in which the interactants are always humans. The survey covers a wide spectrum of settings and scenarios, including free-standing interactions, meetings, indoor and outdoor social exchanges, dyadic conversations, and crowd dynamics. For each of them, the survey considers the three main elements of nonverbal cues analysis, namely data, sensing approaches and computational methodologies. The goal is to highlight the main advances of the last decade, to point out existing limitations, and to outline future directions.
Infinite Feature Selection: A Graph-based Feature Filtering Approach
Jun 15, 2020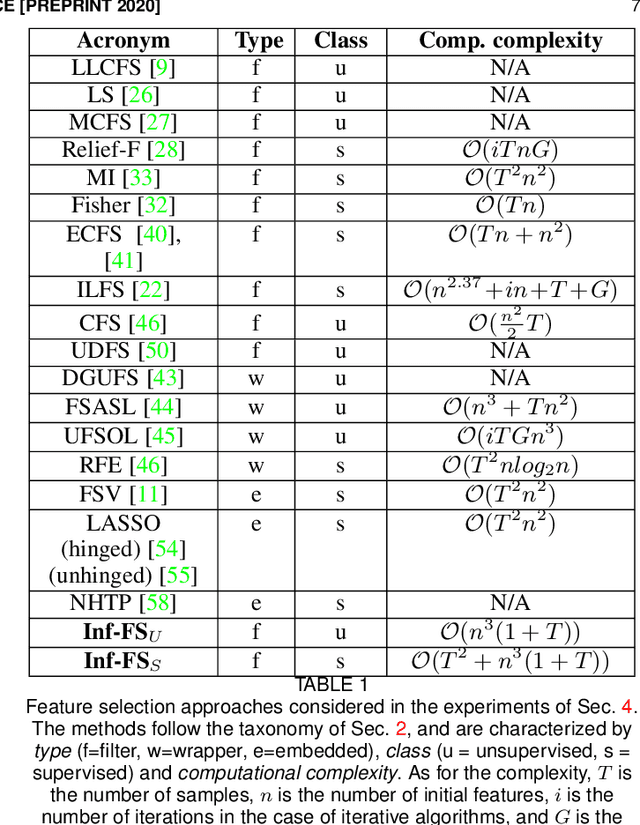
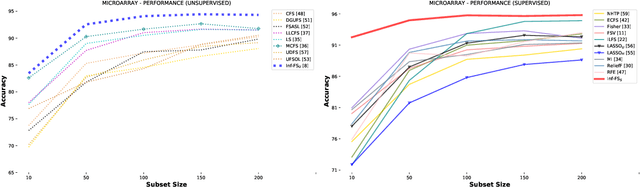
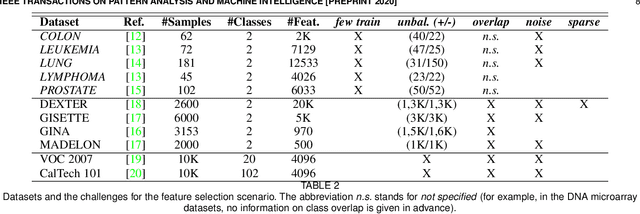
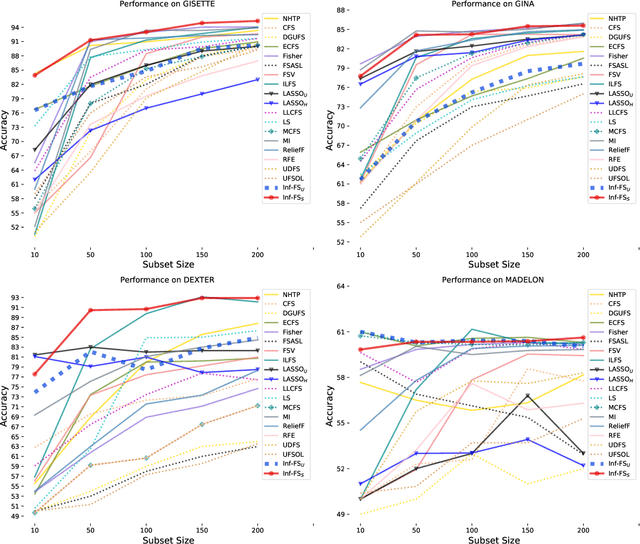
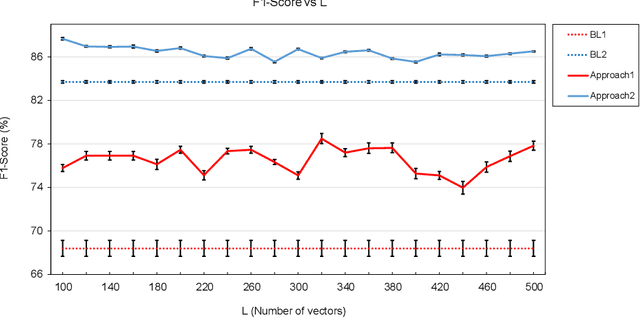
We propose a filtering feature selection framework that considers subsets of features as paths in a graph, where a node is a feature and an edge indicates pairwise (customizable) relations among features, dealing with relevance and redundancy principles. By two different interpretations (exploiting properties of power series of matrices and relying on Markov chains fundamentals) we can evaluate the values of paths (i.e., feature subsets) of arbitrary lengths, eventually go to infinite, from which we dub our framework Infinite Feature Selection (Inf-FS). Going to infinite allows to constrain the computational complexity of the selection process, and to rank the features in an elegant way, that is, considering the value of any path (subset) containing a particular feature. We also propose a simple unsupervised strategy to cut the ranking, so providing the subset of features to keep. In the experiments, we analyze diverse settings with heterogeneous features, for a total of 11 benchmarks, comparing against 18 widely-known comparative approaches. The results show that Inf-FS behaves better in almost any situation, that is, when the number of features to keep are fixed a priori, or when the decision of the subset cardinality is part of the process.
* TPAMI PREPRINT 2020
The Visual Social Distancing Problem
May 11, 2020
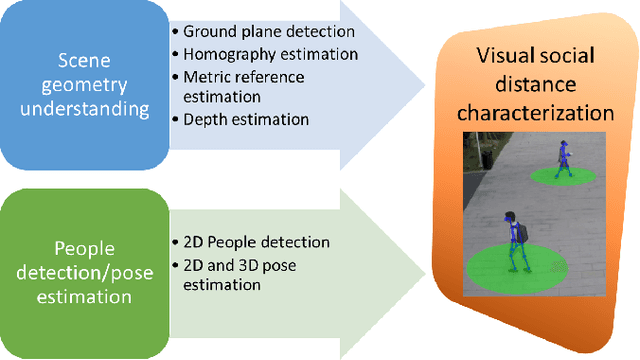
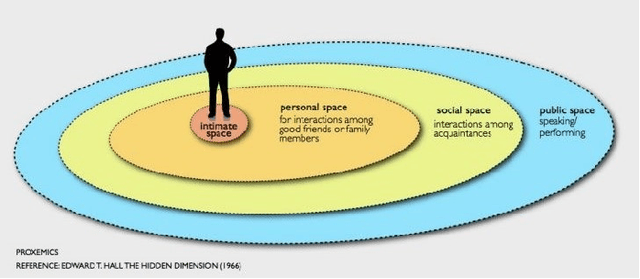
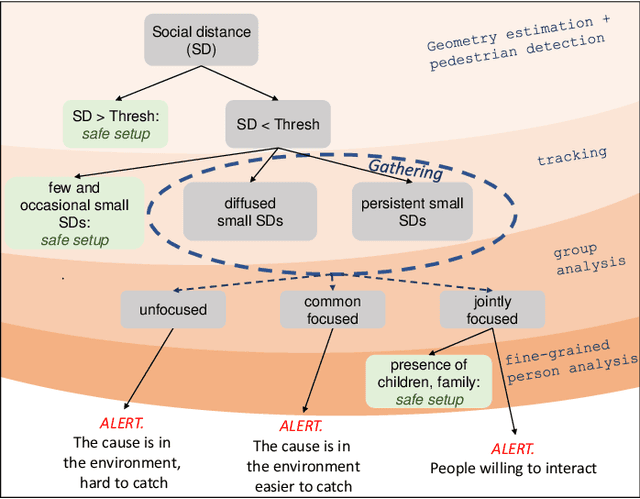
One of the main and most effective measures to contain the recent viral outbreak is the maintenance of the so-called Social Distancing (SD). To comply with this constraint, workplaces, public institutions, transports and schools will likely adopt restrictions over the minimum inter-personal distance between people. Given this actual scenario, it is crucial to massively measure the compliance to such physical constraint in our life, in order to figure out the reasons of the possible breaks of such distance limitations, and understand if this implies a possible threat given the scene context. All of this, complying with privacy policies and making the measurement acceptable. To this end, we introduce the Visual Social Distancing (VSD) problem, defined as the automatic estimation of the inter-personal distance from an image, and the characterization of the related people aggregations. VSD is pivotal for a non-invasive analysis to whether people comply with the SD restriction, and to provide statistics about the level of safety of specific areas whenever this constraint is violated. We then discuss how VSD relates with previous literature in Social Signal Processing and indicate which existing Computer Vision methods can be used to manage such problem. We conclude with future challenges related to the effectiveness of VSD systems, ethical implications and future application scenarios.
Infinite Latent Feature Selection: A Probabilistic Latent Graph-Based Ranking Approach
Jul 24, 2017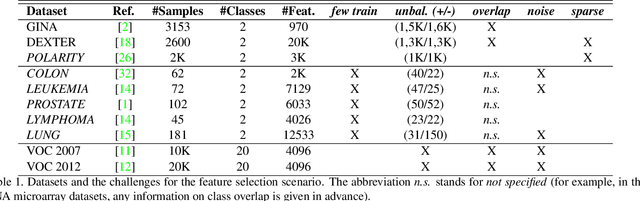
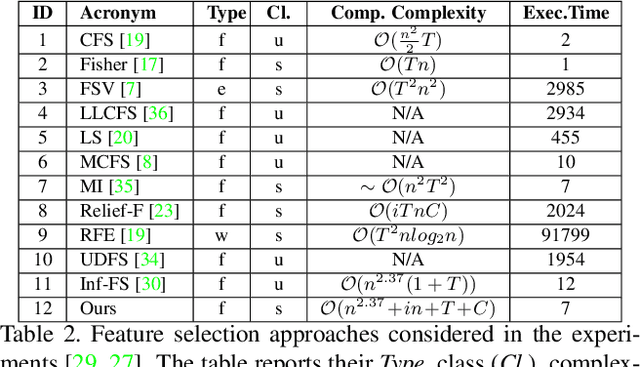
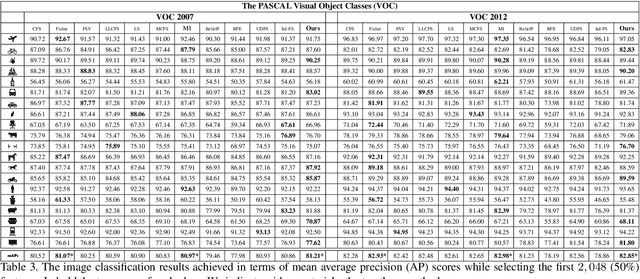
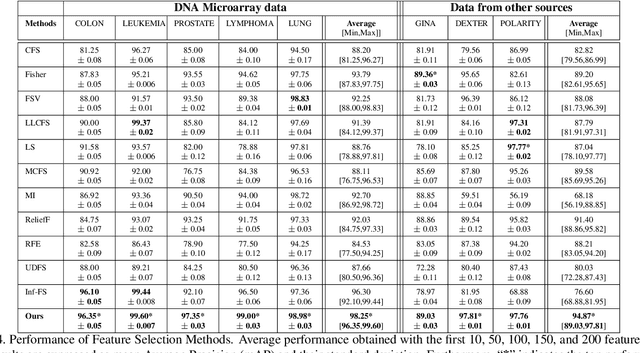
Feature selection is playing an increasingly significant role with respect to many computer vision applications spanning from object recognition to visual object tracking. However, most of the recent solutions in feature selection are not robust across different and heterogeneous set of data. In this paper, we address this issue proposing a robust probabilistic latent graph-based feature selection algorithm that performs the ranking step while considering all the possible subsets of features, as paths on a graph, bypassing the combinatorial problem analytically. An appealing characteristic of the approach is that it aims to discover an abstraction behind low-level sensory data, that is, relevancy. Relevancy is modelled as a latent variable in a PLSA-inspired generative process that allows the investigation of the importance of a feature when injected into an arbitrary set of cues. The proposed method has been tested on ten diverse benchmarks, and compared against eleven state of the art feature selection methods. Results show that the proposed approach attains the highest performance levels across many different scenarios and difficulties, thereby confirming its strong robustness while setting a new state of the art in feature selection domain.