 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-MedRAG: a Self-Reflective Hybrid Retrieval-Augmented Generation Framework for Reliable Medical Question Answering
Jan 08, 2026Large Language Models (LLMs) have demonstrated significant potential in medical Question Answering (QA), yet they remain prone to hallucinations and ungrounded reasoning, limiting their reliability in high-stakes clinical scenarios. While Retrieval-Augmented Generation (RAG) mitigates these issues by incorporating external knowledge, conventional single-shot retrieval often fails to resolve complex biomedical queries requiring multi-step inference. To address this, we propose Self-MedRAG, a self-reflective hybrid framework designed to mimic the iterative hypothesis-verification process of clinical reasoning. Self-MedRAG integrates a hybrid retrieval strategy, combining sparse (BM25) and dense (Contriever) retrievers via Reciprocal Rank Fusion (RRF) to maximize evidence coverage. It employs a generator to produce answers with supporting rationales, which are then assessed by a lightweight self-reflection module using Natural Language Inference (NLI) or LLM-based verification. If the rationale lacks sufficient evidentiary support, the system autonomously reformulates the query and iterates to refine the context. We evaluated Self-MedRAG on the MedQA and PubMedQA benchmarks. The results demonstrate that our hybrid retrieval approach significantly outperforms single-retriever baselines. Furthermore, the inclusion of the self-reflective loop yielded substantial gains, increasing accuracy on MedQA from 80.00% to 83.33% and on PubMedQA from 69.10% to 79.82%. These findings confirm that integrating hybrid retrieval with iterative, evidence-based self-reflection effectively reduces unsupported claims and enhances the clinical reliability of LLM-based systems.
Leveraging IndoBERT and DistilBERT for Indonesian Emotion Classification in E-Commerce Reviews
Sep 18, 2025Understanding emotions in the Indonesian language is essential for improving customer experiences in e-commerce. This study focuses on enhancing the accuracy of emotion classification in Indonesian by leveraging advanced language models, IndoBERT and DistilBERT. A key component of our approach was data processing, specifically data augmentation, which included techniques such as back-translation and synonym replacement. These methods played a significant role in boosting the model's performance. After hyperparameter tuning, IndoBERT achieved an accuracy of 80\%, demonstrating the impact of careful data processing. While combining multiple IndoBERT models led to a slight improvement, it did not significantly enhance performance. Our findings indicate that IndoBERT was the most effective model for emotion classification in Indonesian, with data augmentation proving to be a vital factor in achieving high accuracy. Future research should focus on exploring alternative architectures and strategies to improve generalization for Indonesian NLP tasks.
Twenty Years of Personality Computing: Threats, Challenges and Future Directions
Mar 03, 2025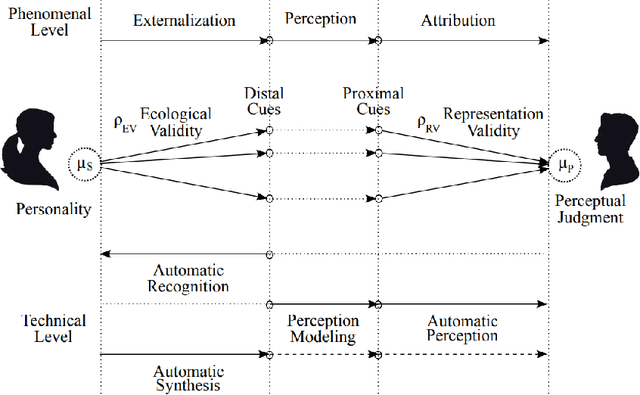
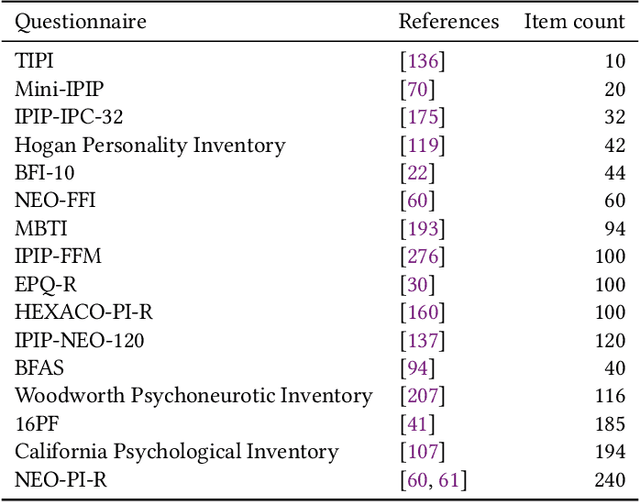
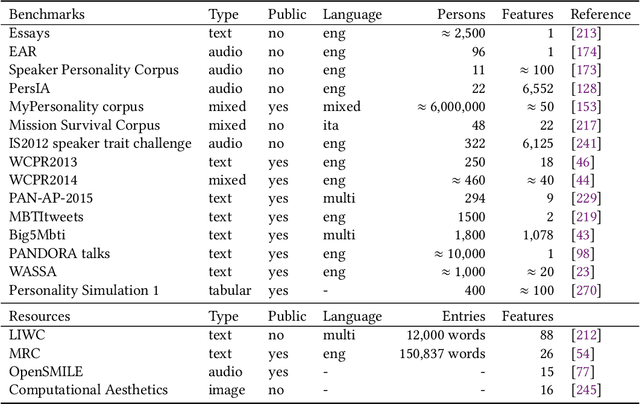
Personality Computing is a field at the intersection of Personality Psychology and Computer Science. Started in 2005, research in the field utilizes computational methods to understand and predict human personality traits. The expansion of the field has been very rapid and, by analyzing digital footprints (text, images, social media, etc.), it helped to develop systems that recognize and even replicate human personality. While offering promising applications in talent recruiting, marketing and healthcare, the ethical implications of Personality Computing are significant. Concerns include data privacy, algorithmic bias, and the potential for manipulation by personality-aware Artificial Intelligence. This paper provides an overview of the field, explores key methodologies, discusses the challenges and threats, and outlines potential future directions for responsible development and deployment of Personality Computing technologies.
Sarcasm Detection in Twitter -- Performance Impact while using Data Augmentation: Word Embeddings
Aug 31, 2021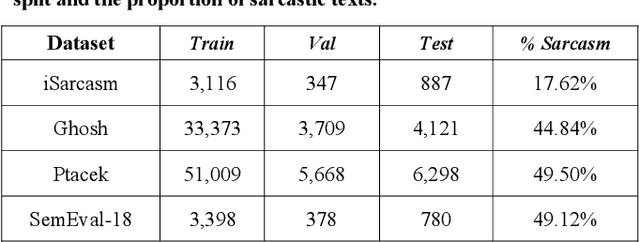
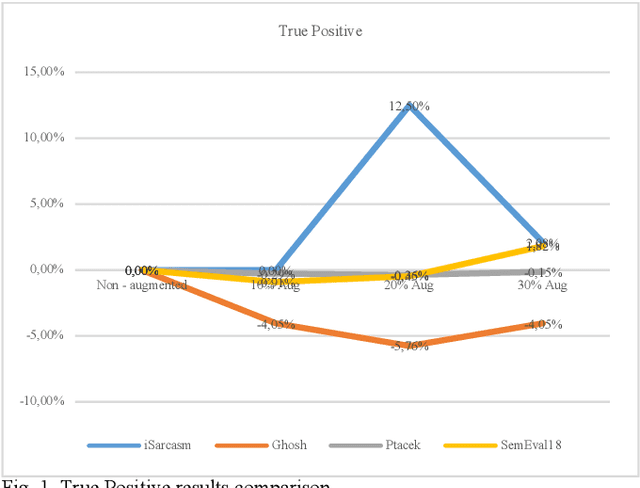
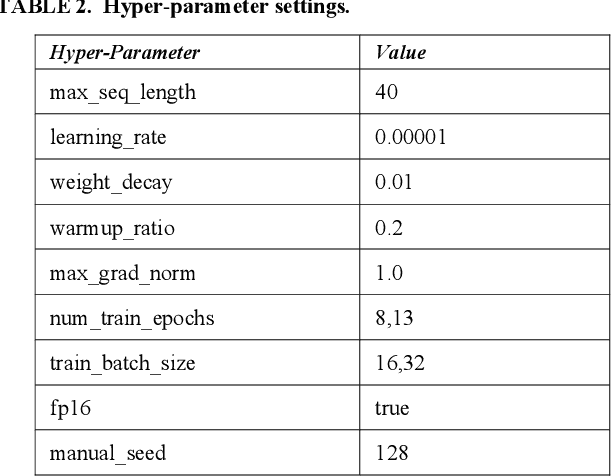

Sarcasm is the use of words usually used to either mock or annoy someone, or for humorous purposes. Sarcasm is largely used in social networks and microblogging websites, where people mock or censure in a way that makes it difficult even for humans to tell if what is said is what is meant. Failure to identify sarcastic utterances in Natural Language Processing applications such as sentiment analysis and opinion mining will confuse classification algorithms and generate false results. Several studies on sarcasm detection have utilized different learning algorithms. However, most of these learning models have always focused on the contents of expression only, leaving the contextual information in isolation. As a result, they failed to capture the contextual information in the sarcastic expression. Moreover, some datasets used in several studies have an unbalanced dataset which impacting the model result. In this paper, we propose a contextual model for sarcasm identification in twitter using RoBERTa, and augmenting the dataset by applying Global Vector representation (GloVe) for the construction of word embedding and context learning to generate more data and balancing the dataset. The effectiveness of this technique is tested with various datasets and data augmentation settings. In particular, we achieve performance gain by 3.2% in the iSarcasm dataset when using data augmentation to increase 20% of data labeled as sarcastic, resulting F-score of 40.4% compared to 37.2% without data augmentation.
Klasifikasi Komponen Argumen Secara Otomatis pada Dokumen Teks berbentuk Esai Argumentatif
Dec 02, 2015By automatically recognize argument component, essay writers can do some inspections to texts that they have written. It will assist essay scoring process objectively and precisely because essay grader is able to see how well the argument components are constructed. Some reseachers have tried to do argument detection and classification along with its implementation in some domains. The common approach is by doing feature extraction to the text. Generally, the features are structural, lexical, syntactic, indicator, and contextual. In this research, we add new feature to the existing features. It adopts keywords list by Knott and Dale (1993). The experiment result shows the argument classification achieves 72.45% accuracy. Moreover, we still get the same accuracy without the keyword lists. This concludes that the keyword lists do not affect significantly to the features. All features are still weak to classify major claim and claim, so we need other features which are useful to differentiate those two kind of argument components.
Probabilistic Latent Semantic Analysis (PLSA) untuk Klasifikasi Dokumen Teks Berbahasa Indonesia
Dec 02, 2015One task that is included in managing documents is how to find substantial information inside. Topic modeling is a technique that has been developed to produce document representation in form of keywords. The keywords will be used in the indexing process and document retrieval as needed by users. In this research, we will discuss specifically about Probabilistic Latent Semantic Analysis (PLSA). It will cover PLSA mechanism which involves Expectation Maximization (EM) as the training algorithm, how to conduct testing, and obtain the accuracy result.