 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Deep Learning for Legal Text Analysis: Predicting Punishment Durations in Indonesian Court Rulings
Oct 26, 2024Limited public understanding of legal processes and inconsistent verdicts in the Indonesian court system led to widespread dissatisfaction and increased stress on judges. This study addresses these issues by developing a deep learning-based predictive system for court sentence lengths. Our hybrid model, combining CNN and BiLSTM with attention mechanism, achieved an R-squared score of 0.5893, effectively capturing both local patterns and long-term dependencies in legal texts. While document summarization proved ineffective, using only the top 30% most frequent tokens increased prediction performance, suggesting that focusing on core legal terminology balances information retention and computational efficiency. We also implemented a modified text normalization process, addressing common errors like misspellings and incorrectly merged words, which significantly improved the model's performance. These findings have important implications for automating legal document processing, aiding both professionals and the public in understanding court judgments. By leveraging advanced NLP techniques, this research contributes to enhancing transparency and accessibility in the Indonesian legal system, paving the way for more consistent and comprehensible legal decisions.
XLS-R Deep Learning Model for Multilingual ASR on Low- Resource Languages: Indonesian, Javanese, and Sundanese
Jan 12, 2024This research paper focuses on the development and evaluation of Automatic Speech Recognition (ASR) technology using the XLS-R 300m model. The study aims to improve ASR performance in converting spoken language into written text, specifically for Indonesian, Javanese, and Sundanese languages. The paper discusses the testing procedures, datasets used, and methodology employed in training and evaluating the ASR systems. The results show that the XLS-R 300m model achieves competitive Word Error Rate (WER) measurements, with a slight compromise in performance for Javanese and Sundanese languages. The integration of a 5-gram KenLM language model significantly reduces WER and enhances ASR accuracy. The research contributes to the advancement of ASR technology by addressing linguistic diversity and improving performance across various languages. The findings provide insights into optimizing ASR accuracy and applicability for diverse linguistic contexts.
Sarcasm Detection in Twitter -- Performance Impact while using Data Augmentation: Word Embeddings
Aug 31, 2021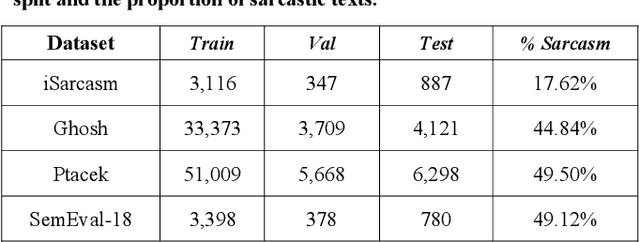
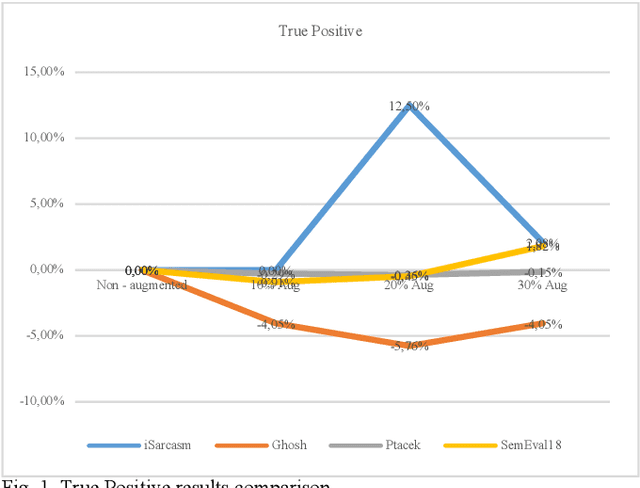
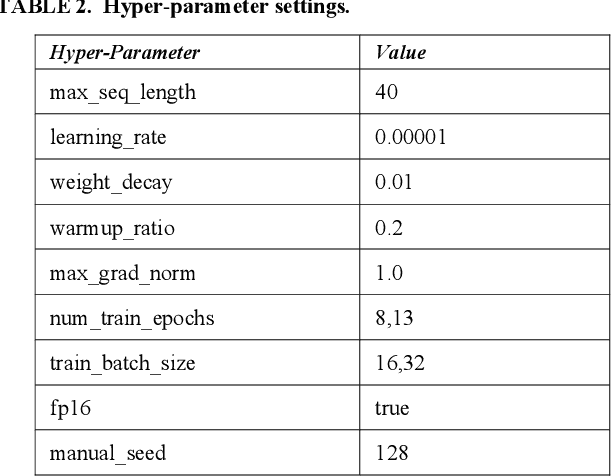

Sarcasm is the use of words usually used to either mock or annoy someone, or for humorous purposes. Sarcasm is largely used in social networks and microblogging websites, where people mock or censure in a way that makes it difficult even for humans to tell if what is said is what is meant. Failure to identify sarcastic utterances in Natural Language Processing applications such as sentiment analysis and opinion mining will confuse classification algorithms and generate false results. Several studies on sarcasm detection have utilized different learning algorithms. However, most of these learning models have always focused on the contents of expression only, leaving the contextual information in isolation. As a result, they failed to capture the contextual information in the sarcastic expression. Moreover, some datasets used in several studies have an unbalanced dataset which impacting the model result. In this paper, we propose a contextual model for sarcasm identification in twitter using RoBERTa, and augmenting the dataset by applying Global Vector representation (GloVe) for the construction of word embedding and context learning to generate more data and balancing the dataset. The effectiveness of this technique is tested with various datasets and data augmentation settings. In particular, we achieve performance gain by 3.2% in the iSarcasm dataset when using data augmentation to increase 20% of data labeled as sarcastic, resulting F-score of 40.4% compared to 37.2% without data augmentation.