 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwenty Years of Personality Computing: Threats, Challenges and Future Directions
Mar 03, 2025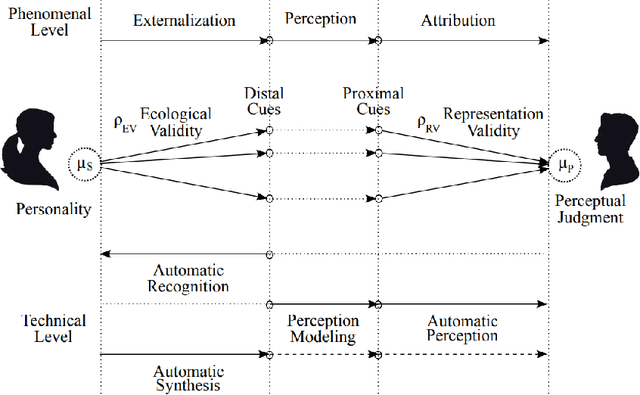
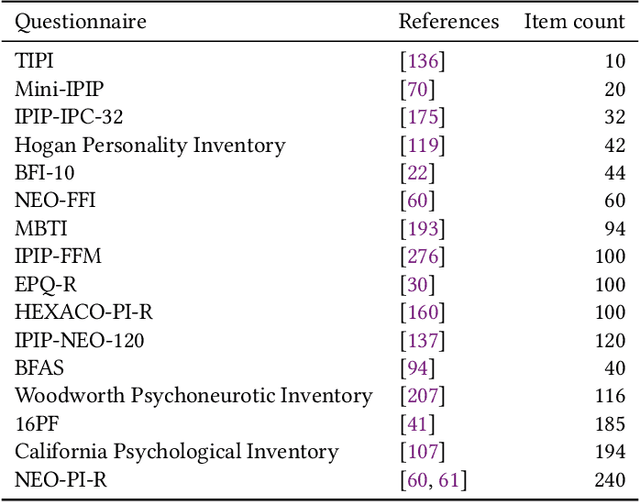
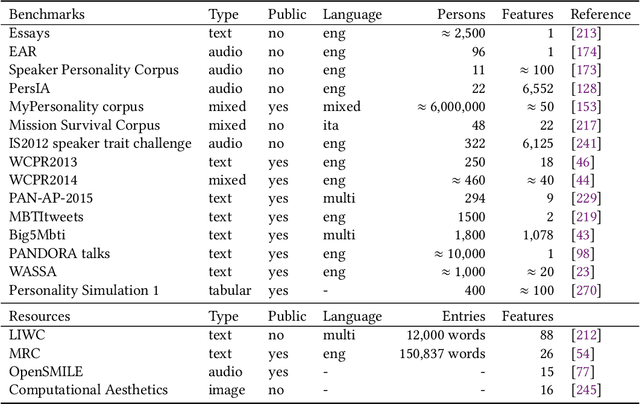
Personality Computing is a field at the intersection of Personality Psychology and Computer Science. Started in 2005, research in the field utilizes computational methods to understand and predict human personality traits. The expansion of the field has been very rapid and, by analyzing digital footprints (text, images, social media, etc.), it helped to develop systems that recognize and even replicate human personality. While offering promising applications in talent recruiting, marketing and healthcare, the ethical implications of Personality Computing are significant. Concerns include data privacy, algorithmic bias, and the potential for manipulation by personality-aware Artificial Intelligence. This paper provides an overview of the field, explores key methodologies, discusses the challenges and threats, and outlines potential future directions for responsible development and deployment of Personality Computing technologies.
A Learning Search Algorithm for the Restricted Longest Common Subsequence Problem
Oct 15, 2024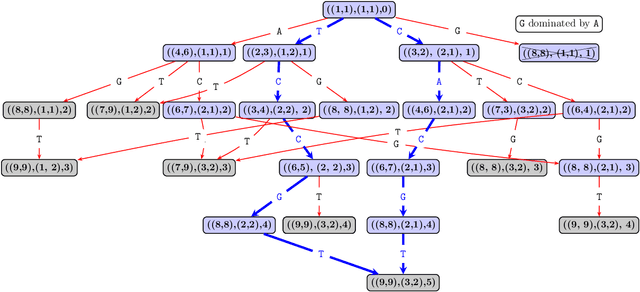
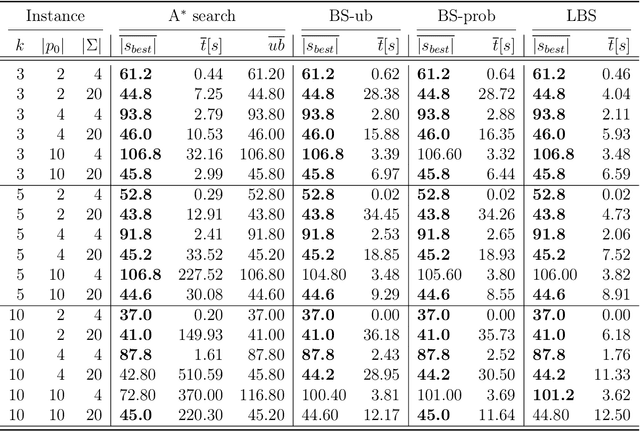
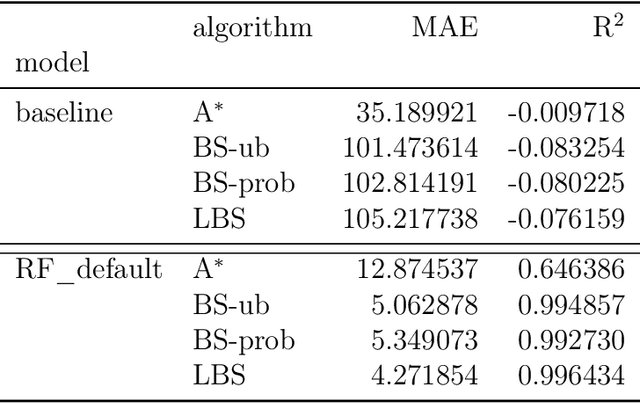
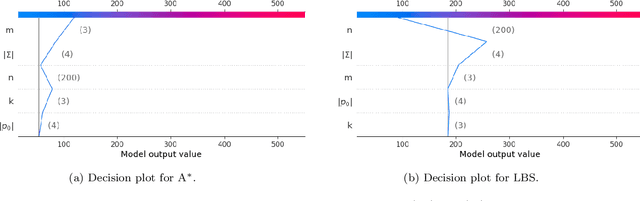
This paper addresses the Restricted Longest Common Subsequence (RLCS) problem, an extension of the well-known Longest Common Subsequence (LCS) problem. This problem has significant applications in bioinformatics, particularly for identifying similarities and discovering mutual patterns and important motifs among DNA, RNA, and protein sequences. Building on recent advancements in solving this problem through a general search framework, this paper introduces two novel heuristic approaches designed to enhance the search process by steering it towards promising regions in the search space. The first heuristic employs a probabilistic model to evaluate partial solutions during the search process. The second heuristic is based on a neural network model trained offline using a genetic algorithm. A key aspect of this approach is extracting problem-specific features of partial solutions and the complete problem instance. An effective hybrid method, referred to as the learning beam search, is developed by combining the trained neural network model with a beam search framework. An important contribution of this paper is found in the generation of real-world instances where scientific abstracts serve as input strings, and a set of frequently occurring academic words from the literature are used as restricted patterns. Comprehensive experimental evaluations demonstrate the effectiveness of the proposed approaches in solving the RLCS problem. Finally, an empirical explainability analysis is applied to the obtained results. In this way, key feature combinations and their respective contributions to the success or failure of the algorithms across different problem types are identified.
A Three-Stage Algorithm for the Closest String Problem on Artificial and Real Gene Sequences
Jul 17, 2024The Closest String Problem is an NP-hard problem that aims to find a string that has the minimum distance from all sequences that belong to the given set of strings. Its applications can be found in coding theory, computational biology, and designing degenerated primers, among others. There are efficient exact algorithms that have reached high-quality solutions for binary sequences. However, there is still room for improvement concerning the quality of solutions over DNA and protein sequences. In this paper, we introduce a three-stage algorithm that comprises the following process: first, we apply a novel alphabet pruning method to reduce the search space for effectively finding promising search regions. Second, a variant of beam search to find a heuristic solution is employed. This method utilizes a newly developed guiding function based on an expected distance heuristic score of partial solutions. Last, we introduce a local search to improve the quality of the solution obtained from the beam search. Furthermore, due to the lack of real-world benchmarks, two real-world datasets are introduced to verify the robustness of the method. The extensive experimental results show that the proposed method outperforms the previous approaches from the literature.
Graph Protection under Multiple Simultaneous Attacks: A Heuristic Approach
Mar 25, 2024This work focuses on developing an effective meta-heuristic approach to protect against simultaneous attacks on nodes of a network modeled using a graph. Specifically, we focus on the $k$-strong Roman domination problem, a generalization of the well-known Roman domination problem on graphs. This general problem is about assigning integer weights to nodes that represent the number of field armies stationed at each node in order to satisfy the protection constraints while minimizing the total weights. These constraints concern the protection of a graph against any simultaneous attack consisting of $k \in \mathbb{N}$ nodes. An attack is considered repelled if each node labeled 0 can be defended by borrowing an army from one of its neighboring nodes, ensuring that the neighbor retains at least one army for self-defense. The $k$-SRD problem has practical applications in various areas, such as developing counter-terrorism strategies or managing supply chain disruptions. The solution to this problem is notoriously difficult to find, as even checking the feasibility of the proposed solution requires an exponential number of steps. We propose a variable neighborhood search algorithm in which the feasibility of the solution is checked by introducing the concept of quasi-feasibility, which is realized by careful sampling within the set of all possible attacks. Extensive experimental evaluations show the scalability and robustness of the proposed approach compared to the two exact approaches from the literature. Experiments are conducted with random networks from the literature and newly introduced random wireless networks as well as with real-world networks. A practical application scenario, using real-world networks, involves applying our approach to graphs extracted from GeoJSON files containing geographic features of hundreds of cities or larger regions.
Topologically sensitive metaheuristics
Feb 25, 2020

This paper proposes topologically sensitive metaheuristics, and describes conceptual design of topologically sensitive Variable Neighborhood Search method (TVNS) and topologically sensitive Electromagnetism Metaheuristic (TEM).