 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard-Attention Gates with Gradient Routing for Endoscopic Image Computing
Jul 05, 2024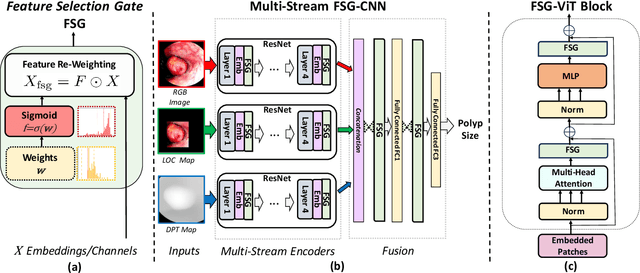
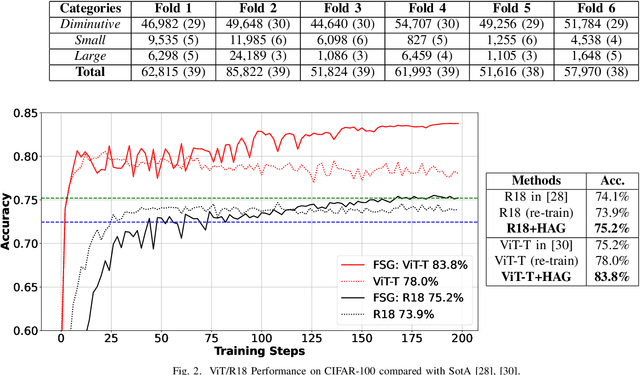
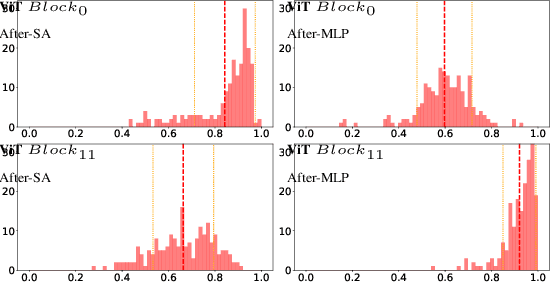
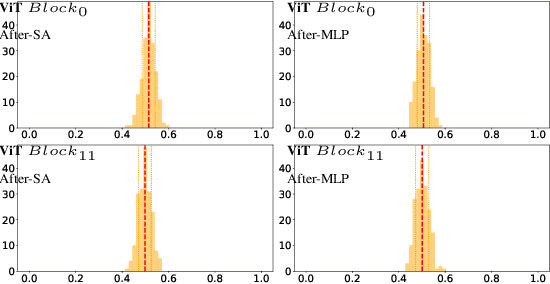
To address overfitting and enhance model generalization in gastroenterological polyp size assessment, our study introduces Feature-Selection Gates (FSG) or Hard-Attention Gates (HAG) alongside Gradient Routing (GR) for dynamic feature selection. This technique aims to boost Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) by promoting sparse connectivity, thereby reducing overfitting and enhancing generalization. HAG achieves this through sparsification with learnable weights, serving as a regularization strategy. GR further refines this process by optimizing HAG parameters via dual forward passes, independently from the main model, to improve feature re-weighting. Our evaluation spanned multiple datasets, including CIFAR-100 for a broad impact assessment and specialized endoscopic datasets (REAL-Colon, Misawa, and SUN) focusing on polyp size estimation, covering over 200 polyps in more than 370,000 frames. The findings indicate that our HAG-enhanced networks substantially enhance performance in both binary and triclass classification tasks related to polyp sizing. Specifically, CNNs experienced an F1 Score improvement to 87.8% in binary classification, while in triclass classification, the ViT-T model reached an F1 Score of 76.5%, outperforming traditional CNNs and ViT-T models. To facilitate further research, we are releasing our codebase, which includes implementations for CNNs, multistream CNNs, ViT, and HAG-augmented variants. This resource aims to standardize the use of endoscopic datasets, providing public training-validation-testing splits for reliable and comparable research in gastroenterological polyp size estimation. The codebase is available at github.com/cosmoimd/feature-selection-gates.
* Attention Gates, Hard-Attention Gates, Gradient Routing, Feature Selection Gates, Endoscopy, Medical Image Processing, Computer Vision
Infinite Feature Selection: A Graph-based Feature Filtering Approach
Jun 15, 2020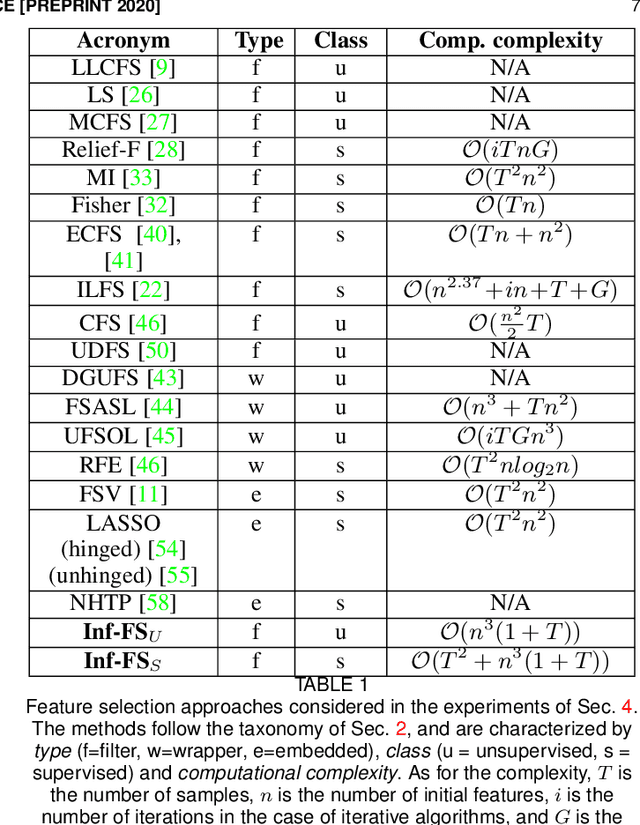
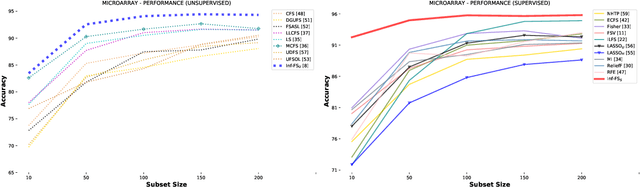
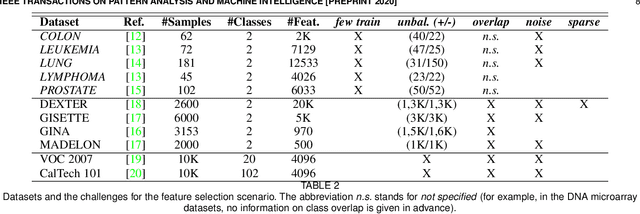
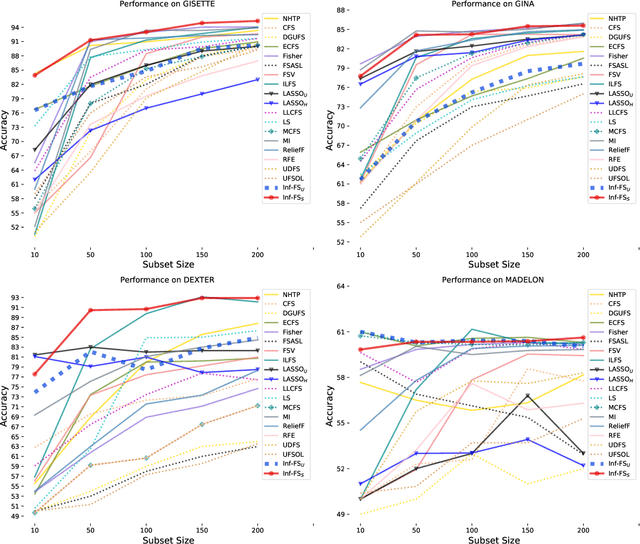
We propose a filtering feature selection framework that considers subsets of features as paths in a graph, where a node is a feature and an edge indicates pairwise (customizable) relations among features, dealing with relevance and redundancy principles. By two different interpretations (exploiting properties of power series of matrices and relying on Markov chains fundamentals) we can evaluate the values of paths (i.e., feature subsets) of arbitrary lengths, eventually go to infinite, from which we dub our framework Infinite Feature Selection (Inf-FS). Going to infinite allows to constrain the computational complexity of the selection process, and to rank the features in an elegant way, that is, considering the value of any path (subset) containing a particular feature. We also propose a simple unsupervised strategy to cut the ranking, so providing the subset of features to keep. In the experiments, we analyze diverse settings with heterogeneous features, for a total of 11 benchmarks, comparing against 18 widely-known comparative approaches. The results show that Inf-FS behaves better in almost any situation, that is, when the number of features to keep are fixed a priori, or when the decision of the subset cardinality is part of the process.
* TPAMI PREPRINT 2020
Feature Selection Library (MATLAB Toolbox)
Aug 06, 2018


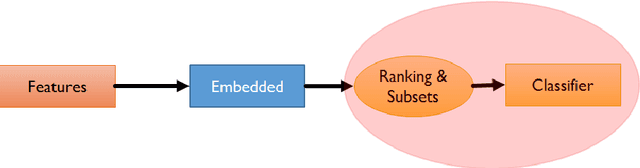
Feature Selection Library (FSLib) is a widely applicable MATLAB library for Feature Selection (FS). FS is an essential component of machine learning and data mining which has been studied for many years under many different conditions and in diverse scenarios. These algorithms aim at ranking and selecting a subset of relevant features according to their degrees of relevance, preference, or importance as defined in a specific application. Because feature selection can reduce the amount of features used for training classification models, it alleviates the effect of the curse of dimensionality, speeds up the learning process, improves model's performance, and enhances data understanding. This short report provides an overview of the feature selection algorithms included in the FSLib MATLAB toolbox among filter, embedded, and wrappers methods.
Infinite Latent Feature Selection: A Probabilistic Latent Graph-Based Ranking Approach
Jul 24, 2017
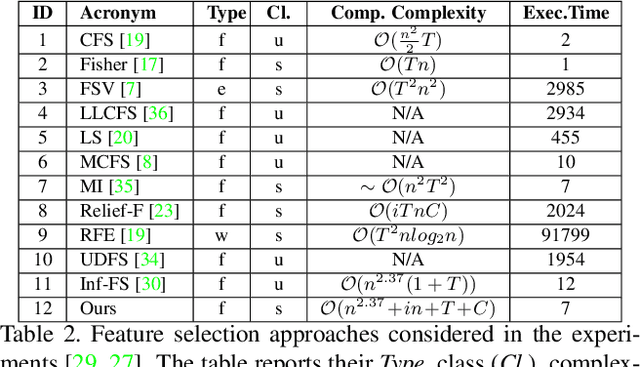
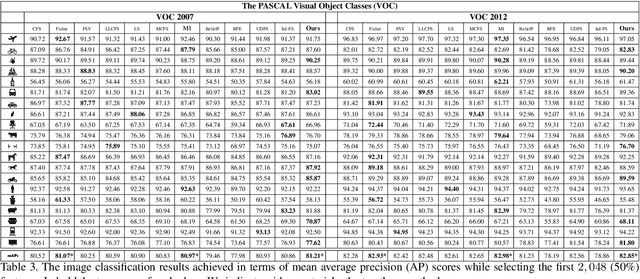
Feature selection is playing an increasingly significant role with respect to many computer vision applications spanning from object recognition to visual object tracking. However, most of the recent solutions in feature selection are not robust across different and heterogeneous set of data. In this paper, we address this issue proposing a robust probabilistic latent graph-based feature selection algorithm that performs the ranking step while considering all the possible subsets of features, as paths on a graph, bypassing the combinatorial problem analytically. An appealing characteristic of the approach is that it aims to discover an abstraction behind low-level sensory data, that is, relevancy. Relevancy is modelled as a latent variable in a PLSA-inspired generative process that allows the investigation of the importance of a feature when injected into an arbitrary set of cues. The proposed method has been tested on ten diverse benchmarks, and compared against eleven state of the art feature selection methods. Results show that the proposed approach attains the highest performance levels across many different scenarios and difficulties, thereby confirming its strong robustness while setting a new state of the art in feature selection domain.
Ranking to Learn and Learning to Rank: On the Role of Ranking in Pattern Recognition Applications
Jun 01, 2017
The last decade has seen a revolution in the theory and application of machine learning and pattern recognition. Through these advancements, variable ranking has emerged as an active and growing research area and it is now beginning to be applied to many new problems. The rationale behind this fact is that many pattern recognition problems are by nature ranking problems. The main objective of a ranking algorithm is to sort objects according to some criteria, so that, the most relevant items will appear early in the produced result list. Ranking methods can be analyzed from two different methodological perspectives: ranking to learn and learning to rank. The former aims at studying methods and techniques to sort objects for improving the accuracy of a machine learning model. Enhancing a model performance can be challenging at times. For example, in pattern classification tasks, different data representations can complicate and hide the different explanatory factors of variation behind the data. In particular, hand-crafted features contain many cues that are either redundant or irrelevant, which turn out to reduce the overall accuracy of the classifier. In such a case feature selection is used, that, by producing ranked lists of features, helps to filter out the unwanted information. Moreover, in real-time systems (e.g., visual trackers) ranking approaches are used as optimization procedures which improve the robustness of the system that deals with the high variability of the image streams that change over time. The other way around, learning to rank is necessary in the construction of ranking models for information retrieval, biometric authentication, re-identification, and recommender systems. In this context, the ranking model's purpose is to sort objects according to their degrees of relevance, importance, or preference as defined in the specific application.
Ranking to Learn: Feature Ranking and Selection via Eigenvector Centrality
Apr 18, 2017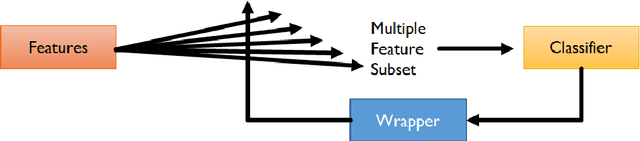

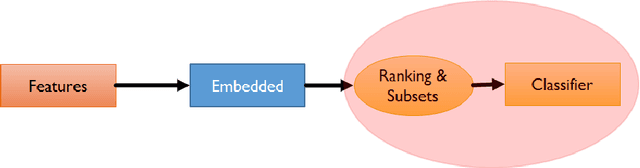
In an era where accumulating data is easy and storing it inexpensive, feature selection plays a central role in helping to reduce the high-dimensionality of huge amounts of otherwise meaningless data. In this paper, we propose a graph-based method for feature selection that ranks features by identifying the most important ones into arbitrary set of cues. Mapping the problem on an affinity graph-where features are the nodes-the solution is given by assessing the importance of nodes through some indicators of centrality, in particular, the Eigen-vector Centrality (EC). The gist of EC is to estimate the importance of a feature as a function of the importance of its neighbors. Ranking central nodes individuates candidate features, which turn out to be effective from a classification point of view, as proved by a thoroughly experimental section. Our approach has been tested on 7 diverse datasets from recent literature (e.g., biological data and object recognition, among others), and compared against filter, embedded and wrappers methods. The results are remarkable in terms of accuracy, stability and low execution time.
* Preprint version - Lecture Notes in Computer Science - Springer 2017
Object Tracking via Dynamic Feature Selection Processes
Sep 07, 2016
DFST proposes an optimized visual tracking algorithm based on the real-time selection of locally and temporally discriminative features. A feature selection mechanism is embedded in the Adaptive colour Names (CN) tracking system that adaptively selects the top-ranked discriminative features for tracking. DFST provides a significant gain in accuracy and precision allowing the use of a dynamic set of features that results in an increased system flexibility. DFST is based on the unsupervised method "Infinite Feature Selection" (Inf-FS), which ranks features according with their "redundancy" without using class labels. By using a fast online algorithm for learning dictionaries the size of the box is adapted during the processing. At each update, we use multiple examples around the target (at different positions and scales). DFST also improved the CN by adding micro-shift at the predicted position and bounding box adaptation.