 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBooW-VTON: Boosting In-the-Wild Virtual Try-On via Mask-Free Pseudo Data Training
Paper and Code


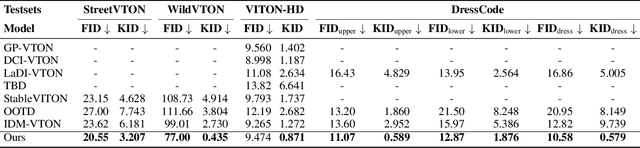
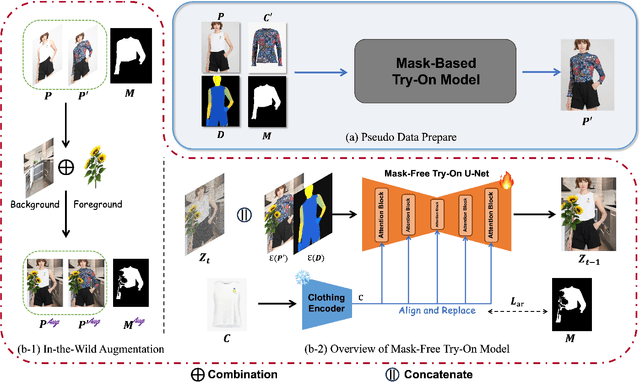
Image-based virtual try-on is an increasingly popular and important task to generate realistic try-on images of specific person. Existing methods always employ an accurate mask to remove the original garment in the source image, thus achieving realistic synthesized images in simple and conventional try-on scenarios based on powerful diffusion model. Therefore, acquiring suitable mask is vital to the try-on performance of these methods. However, obtaining precise inpainting masks, especially for complex wild try-on data containing diverse foreground occlusions and person poses, is not easy as Figure 1-Top shows. This difficulty often results in poor performance in more practical and challenging real-life scenarios, such as the selfie scene shown in Figure 1-Bottom. To this end, we propose a novel training paradigm combined with an efficient data augmentation method to acquire large-scale unpaired training data from wild scenarios, thereby significantly facilitating the try-on performance of our model without the need for additional inpainting masks. Besides, a try-on localization loss is designed to localize a more accurate try-on area to obtain more reasonable try-on results. It is noted that our method only needs the reference cloth image, source pose image and source person image as input, which is more cost-effective and user-friendly compared to existing methods. Extensive qualitative and quantitative experiments have demonstrated superior performance in wild scenarios with such a low-demand input.