 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep residual learning with product units
May 07, 2025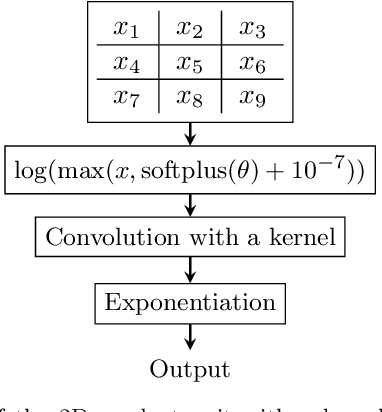
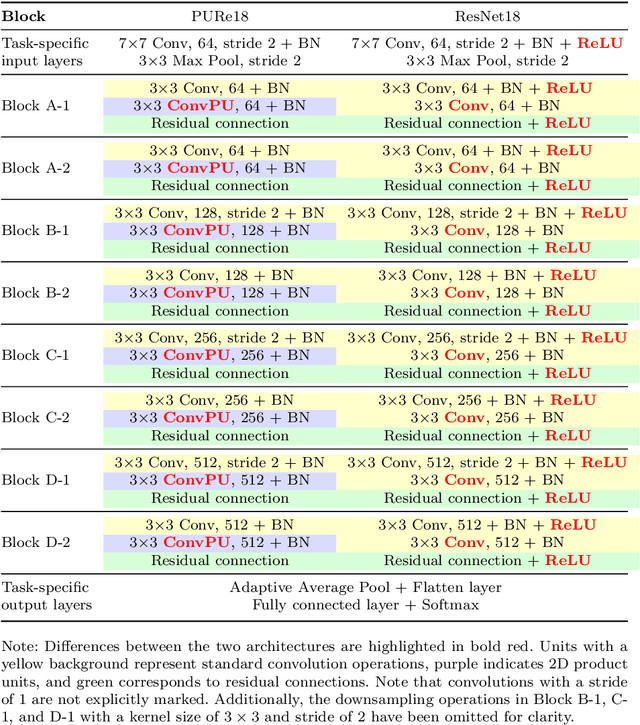
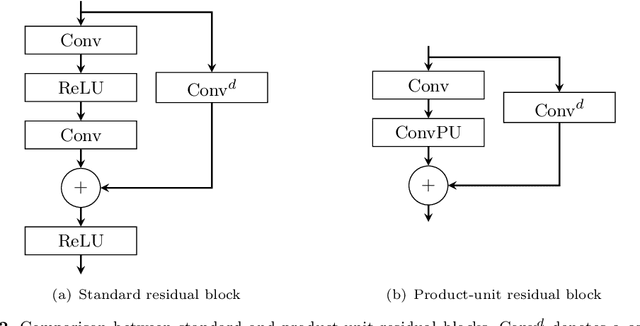
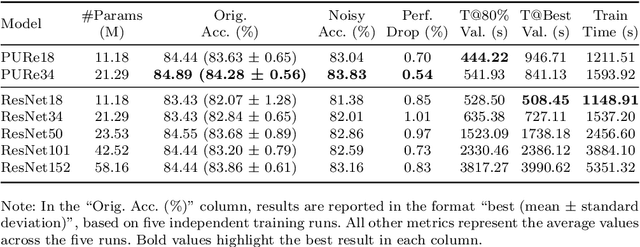
We propose a deep product-unit residual neural network (PURe) that integrates product units into residual blocks to improve the expressiveness and parameter efficiency of deep convolutional networks. Unlike standard summation neurons, product units enable multiplicative feature interactions, potentially offering a more powerful representation of complex patterns. PURe replaces conventional convolutional layers with 2D product units in the second layer of each residual block, eliminating nonlinear activation functions to preserve structural information. We validate PURe on three benchmark datasets. On Galaxy10 DECaLS, PURe34 achieves the highest test accuracy of 84.89%, surpassing the much deeper ResNet152, while converging nearly five times faster and demonstrating strong robustness to Poisson noise. On ImageNet, PURe architectures outperform standard ResNet models at similar depths, with PURe34 achieving a top-1 accuracy of 80.27% and top-5 accuracy of 95.78%, surpassing deeper ResNet variants (ResNet50, ResNet101) while utilizing significantly fewer parameters and computational resources. On CIFAR-10, PURe consistently outperforms ResNet variants across varying depths, with PURe272 reaching 95.01% test accuracy, comparable to ResNet1001 but at less than half the model size. These results demonstrate that PURe achieves a favorable balance between accuracy, efficiency, and robustness. Compared to traditional residual networks, PURe not only achieves competitive classification performance with faster convergence and fewer parameters, but also demonstrates greater robustness to noise. Its effectiveness across diverse datasets highlights the potential of product-unit-based architectures for scalable and reliable deep learning in computer vision.
A Stock Price Prediction Approach Based on Time Series Decomposition and Multi-Scale CNN using OHLCT Images
Oct 29, 2024



Recently, deep learning in stock prediction has become an important branch. Image-based methods show potential by capturing complex visual patterns and spatial correlations, offering advantages in interpretability over time series models. However, image-based approaches are more prone to overfitting, hindering robust predictive performance. To improve accuracy, this paper proposes a novel method, named Sequence-based Multi-scale Fusion Regression Convolutional Neural Network (SMSFR-CNN), for predicting stock price movements in the China A-share market. By utilizing CNN to learn sequential features and combining them with image features, we improve the accuracy of stock trend prediction on the A-share market stock dataset. This approach reduces the search space for image features, stabilizes, and accelerates the training process. Extensive comparative experiments on 4,454 A-share stocks show that the model achieves a 61.15% positive predictive value and a 63.37% negative predictive value for the next 5 days, resulting in a total profit of 165.09%.
FinTextQA: A Dataset for Long-form Financial Question Answering
May 16, 2024



Accurate evaluation of financial question answering (QA) systems necessitates a comprehensive dataset encompassing diverse question types and contexts. However, current financial QA datasets lack scope diversity and question complexity. This work introduces FinTextQA, a novel dataset for long-form question answering (LFQA) in finance. FinTextQA comprises 1,262 high-quality, source-attributed QA pairs extracted and selected from finance textbooks and government agency websites.Moreover, we developed a Retrieval-Augmented Generation (RAG)-based LFQA system, comprising an embedder, retriever, reranker, and generator. A multi-faceted evaluation approach, including human ranking, automatic metrics, and GPT-4 scoring, was employed to benchmark the performance of different LFQA system configurations under heightened noisy conditions. The results indicate that: (1) Among all compared generators, Baichuan2-7B competes closely with GPT-3.5-turbo in accuracy score; (2) The most effective system configuration on our dataset involved setting the embedder, retriever, reranker, and generator as Ada2, Automated Merged Retrieval, Bge-Reranker-Base, and Baichuan2-7B, respectively; (3) models are less susceptible to noise after the length of contexts reaching a specific threshold.
SSIF: Learning Continuous Image Representation for Spatial-Spectral Super-Resolution
Sep 30, 2023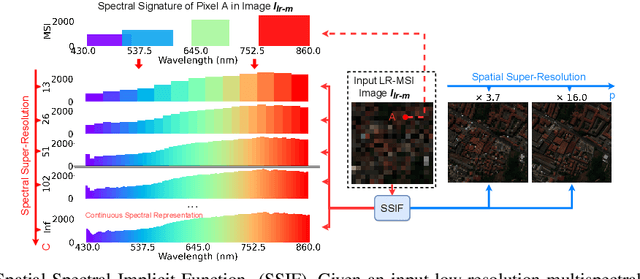
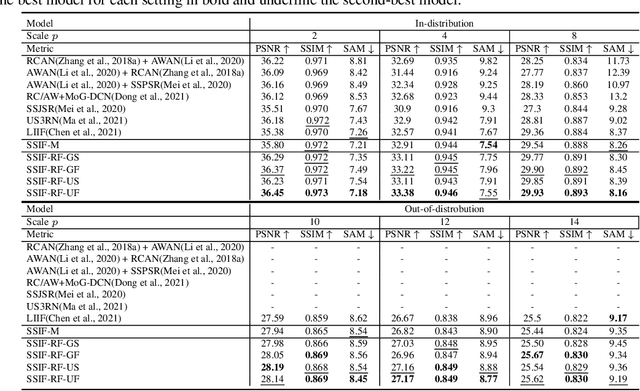
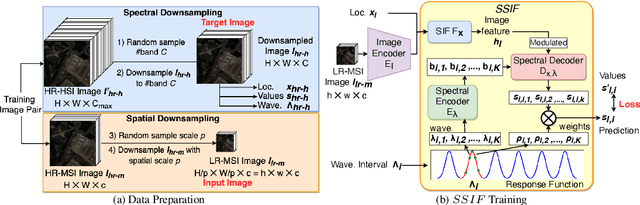
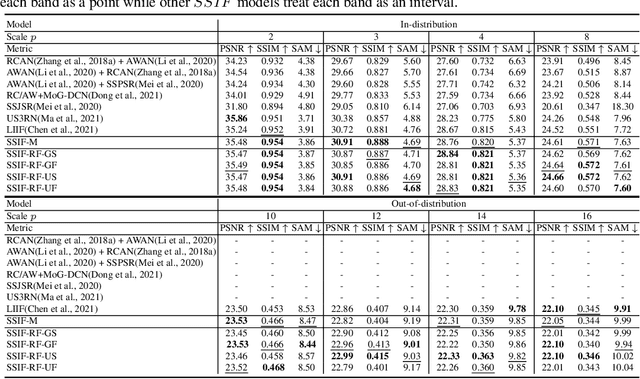
Existing digital sensors capture images at fixed spatial and spectral resolutions (e.g., RGB, multispectral, and hyperspectral images), and each combination requires bespoke machine learning models. Neural Implicit Functions partially overcome the spatial resolution challenge by representing an image in a resolution-independent way. However, they still operate at fixed, pre-defined spectral resolutions. To address this challenge, we propose Spatial-Spectral Implicit Function (SSIF), a neural implicit model that represents an image as a function of both continuous pixel coordinates in the spatial domain and continuous wavelengths in the spectral domain. We empirically demonstrate the effectiveness of SSIF on two challenging spatio-spectral super-resolution benchmarks. We observe that SSIF consistently outperforms state-of-the-art baselines even when the baselines are allowed to train separate models at each spectral resolution. We show that SSIF generalizes well to both unseen spatial resolutions and spectral resolutions. Moreover, SSIF can generate high-resolution images that improve the performance of downstream tasks (e.g., land use classification) by 1.7%-7%.
On the Opportunities and Challenges of Foundation Models for Geospatial Artificial Intelligence
Apr 13, 2023



Large pre-trained models, also known as foundation models (FMs), are trained in a task-agnostic manner on large-scale data and can be adapted to a wide range of downstream tasks by fine-tuning, few-shot, or even zero-shot learning. Despite their successes in language and vision tasks, we have yet seen an attempt to develop foundation models for geospatial artificial intelligence (GeoAI). In this work, we explore the promises and challenges of developing multimodal foundation models for GeoAI. We first investigate the potential of many existing FMs by testing their performances on seven tasks across multiple geospatial subdomains including Geospatial Semantics, Health Geography, Urban Geography, and Remote Sensing. Our results indicate that on several geospatial tasks that only involve text modality such as toponym recognition, location description recognition, and US state-level/county-level dementia time series forecasting, these task-agnostic LLMs can outperform task-specific fully-supervised models in a zero-shot or few-shot learning setting. However, on other geospatial tasks, especially tasks that involve multiple data modalities (e.g., POI-based urban function classification, street view image-based urban noise intensity classification, and remote sensing image scene classification), existing foundation models still underperform task-specific models. Based on these observations, we propose that one of the major challenges of developing a FM for GeoAI is to address the multimodality nature of geospatial tasks. After discussing the distinct challenges of each geospatial data modality, we suggest the possibility of a multimodal foundation model which can reason over various types of geospatial data through geospatial alignments. We conclude this paper by discussing the unique risks and challenges to develop such a model for GeoAI.