 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLEE-GNN: A Federated Learning System for Edge-Enhanced Graph Neural Network in Analyzing Geospatial Resilience of Multicommodity Food Flows
Oct 20, 2023



Understanding and measuring the resilience of food supply networks is a global imperative to tackle increasing food insecurity. However, the complexity of these networks, with their multidimensional interactions and decisions, presents significant challenges. This paper proposes FLEE-GNN, a novel Federated Learning System for Edge-Enhanced Graph Neural Network, designed to overcome these challenges and enhance the analysis of geospatial resilience of multicommodity food flow network, which is one type of spatial networks. FLEE-GNN addresses the limitations of current methodologies, such as entropy-based methods, in terms of generalizability, scalability, and data privacy. It combines the robustness and adaptability of graph neural networks with the privacy-conscious and decentralized aspects of federated learning on food supply network resilience analysis across geographical regions. This paper also discusses FLEE-GNN's innovative data generation techniques, experimental designs, and future directions for improvement. The results show the advancements of this approach to quantifying the resilience of multicommodity food flow networks, contributing to efforts towards ensuring global food security using AI methods. The developed FLEE-GNN has the potential to be applied in other spatial networks with spatially heterogeneous sub-network distributions.
* 10 pages, 5 figures
Artificial Neuronal Ensembles with Learned Context Dependent Gating
Jan 19, 2023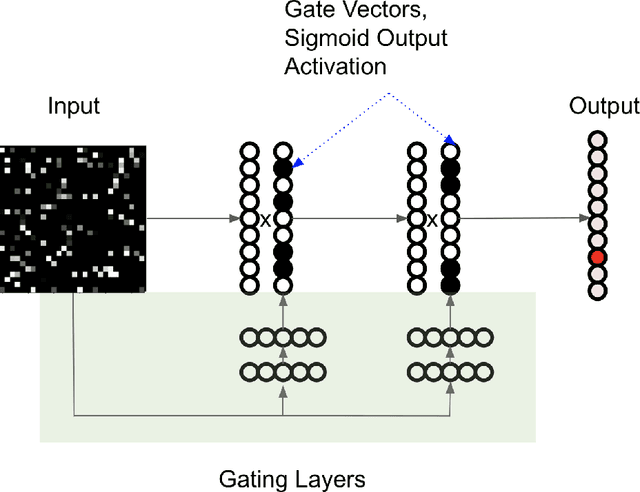

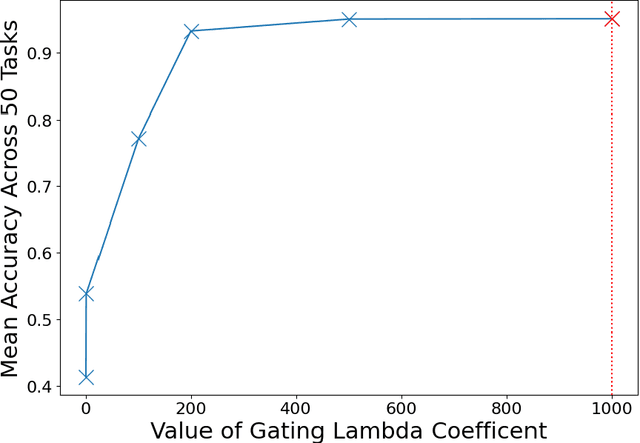
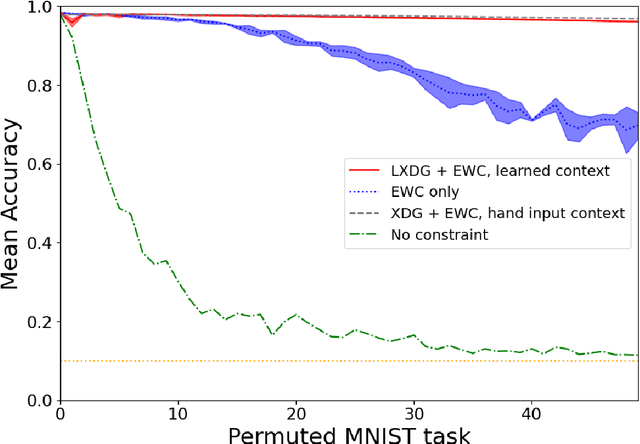
Biological neural networks are capable of recruiting different sets of neurons to encode different memories. However, when training artificial neural networks on a set of tasks, typically, no mechanism is employed for selectively producing anything analogous to these neuronal ensembles. Further, artificial neural networks suffer from catastrophic forgetting, where the network's performance rapidly deteriorates as tasks are learned sequentially. By contrast, sequential learning is possible for a range of biological organisms. We introduce Learned Context Dependent Gating (LXDG), a method to flexibly allocate and recall `artificial neuronal ensembles', using a particular network structure and a new set of regularization terms. Activities in the hidden layers of the network are modulated by gates, which are dynamically produced during training. The gates are outputs of networks themselves, trained with a sigmoid output activation. The regularization terms we have introduced correspond to properties exhibited by biological neuronal ensembles. The first term penalizes low gate sparsity, ensuring that only a specified fraction of the network is used. The second term ensures that previously learned gates are recalled when the network is presented with input from previously learned tasks. Finally, there is a regularization term responsible for ensuring that new tasks are encoded in gates that are as orthogonal as possible from previously used ones. We demonstrate the ability of this method to alleviate catastrophic forgetting on continual learning benchmarks. When the new regularization terms are included in the model along with Elastic Weight Consolidation (EWC) it achieves better performance on the benchmark `permuted MNIST' than with EWC alone. The benchmark `rotated MNIST' demonstrates how similar tasks recruit similar neurons to the artificial neuronal ensemble.