 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Neuronal Ensembles with Learned Context Dependent Gating
Jan 19, 2023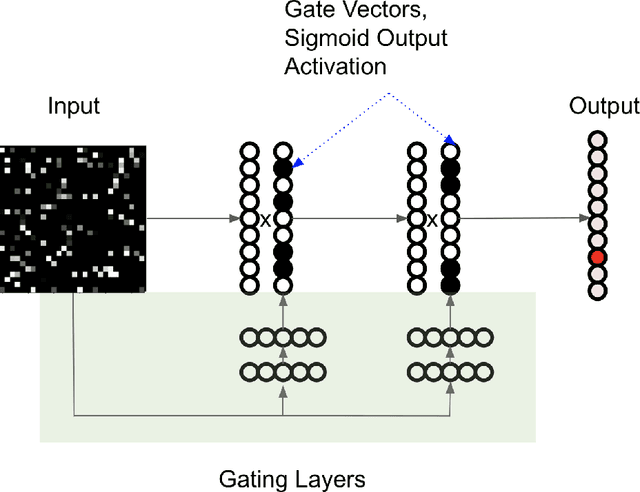

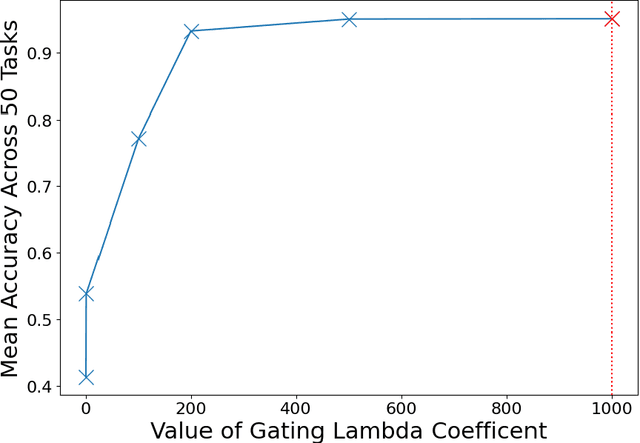
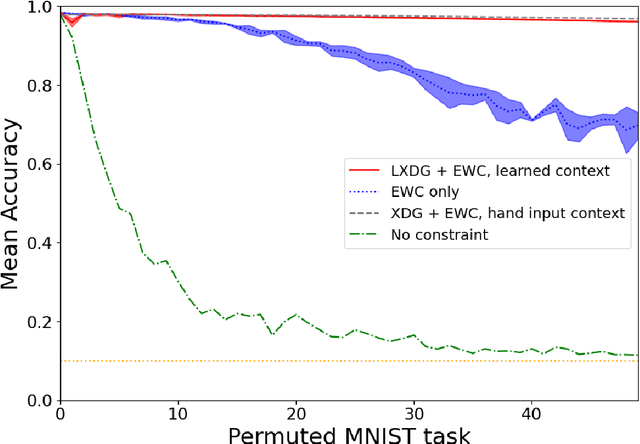
Biological neural networks are capable of recruiting different sets of neurons to encode different memories. However, when training artificial neural networks on a set of tasks, typically, no mechanism is employed for selectively producing anything analogous to these neuronal ensembles. Further, artificial neural networks suffer from catastrophic forgetting, where the network's performance rapidly deteriorates as tasks are learned sequentially. By contrast, sequential learning is possible for a range of biological organisms. We introduce Learned Context Dependent Gating (LXDG), a method to flexibly allocate and recall `artificial neuronal ensembles', using a particular network structure and a new set of regularization terms. Activities in the hidden layers of the network are modulated by gates, which are dynamically produced during training. The gates are outputs of networks themselves, trained with a sigmoid output activation. The regularization terms we have introduced correspond to properties exhibited by biological neuronal ensembles. The first term penalizes low gate sparsity, ensuring that only a specified fraction of the network is used. The second term ensures that previously learned gates are recalled when the network is presented with input from previously learned tasks. Finally, there is a regularization term responsible for ensuring that new tasks are encoded in gates that are as orthogonal as possible from previously used ones. We demonstrate the ability of this method to alleviate catastrophic forgetting on continual learning benchmarks. When the new regularization terms are included in the model along with Elastic Weight Consolidation (EWC) it achieves better performance on the benchmark `permuted MNIST' than with EWC alone. The benchmark `rotated MNIST' demonstrates how similar tasks recruit similar neurons to the artificial neuronal ensemble.
Improving Importance Weighted Auto-Encoders with Annealed Importance Sampling
Jun 12, 2019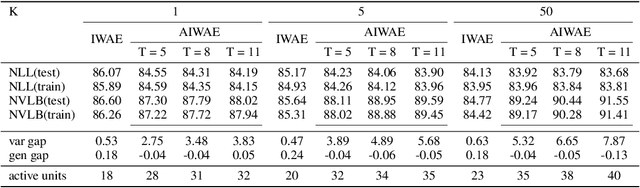
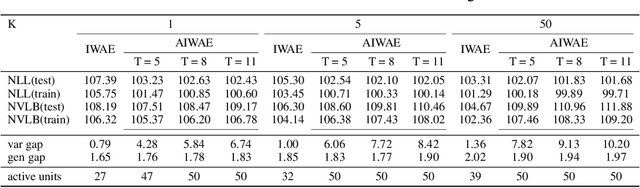
Stochastic variational inference with an amortized inference model and the reparameterization trick has become a widely-used algorithm for learning latent variable models. Increasing the flexibility of approximate posterior distributions while maintaining computational tractability is one of the core problems in stochastic variational inference. Two families of approaches proposed to address the problem are flow-based and multisample-based approaches such as importance weighted auto-encoders (IWAE). We introduce a new learning algorithm, the annealed importance weighted auto-encoder (AIWAE), for learning latent variable models. The proposed AIWAE combines multisample-based and flow-based approaches with the annealed importance sampling and its memory cost stays constant when the depth of flows increases. The flow constructed using an annealing process in AIWAE facilitates the exploration of the latent space when the posterior distribution has multiple modes. Through computational experiments, we show that, compared to models trained using the IWAE, AIWAE-trained models are better density models, have more complex posterior distributions and use more latent space representation capacity.
Alleviating catastrophic forgetting using context-dependent gating and synaptic stabilization
Feb 02, 2018



Humans and most animals can learn new tasks without forgetting old ones. However, training artificial neural networks (ANNs) on new tasks typically cause it to forget previously learned tasks. This phenomenon is the result of "catastrophic forgetting", in which training an ANN disrupts connection weights that were important for solving previous tasks, degrading task performance. Several recent studies have proposed methods to stabilize connection weights of ANNs that are deemed most important for solving a task, which helps alleviate catastrophic forgetting. Here, drawing inspiration from algorithms that are believed to be implemented in vivo, we propose a complementary method: adding a context-dependent gating signal, such that only sparse, mostly non-overlapping patterns of units are active for any one task. This method is easy to implement, requires little computational overhead, and allows ANNs to maintain high performance across large numbers of sequentially presented tasks when combined with weight stabilization. This work provides another example of how neuroscience-inspired algorithms can benefit ANN design and capability.