 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere you go is who you are -- A study on machine learning based semantic privacy attacks
Paper and Code
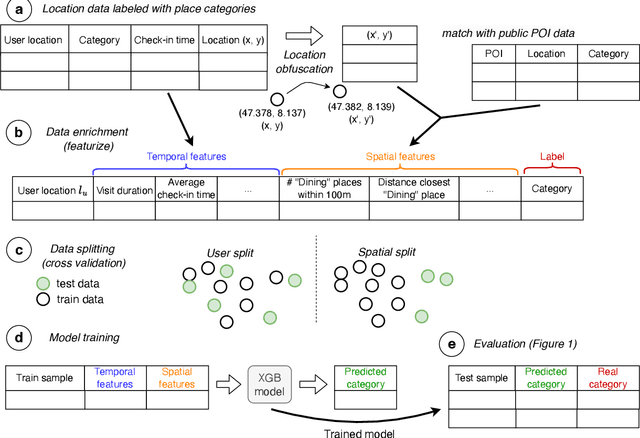
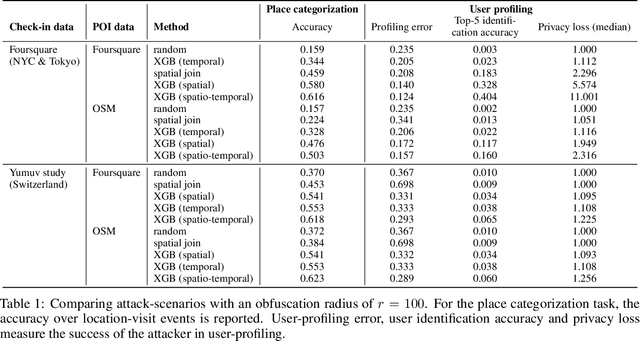
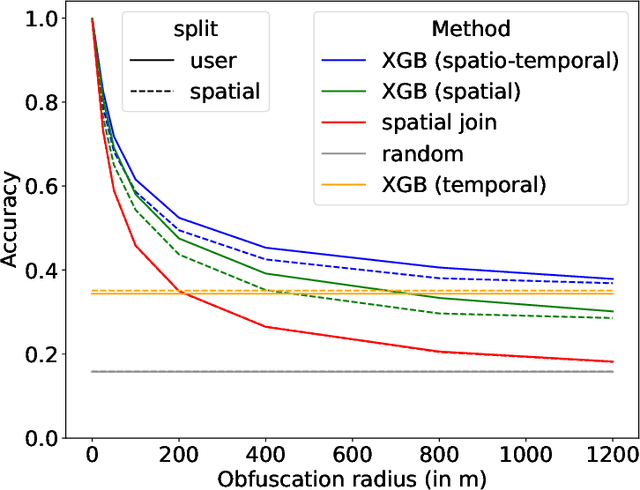
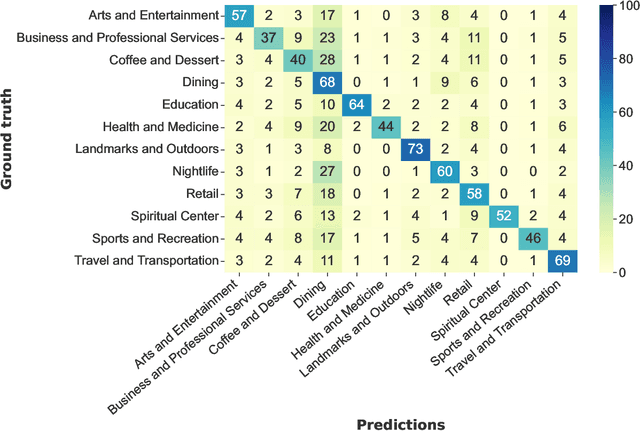
Concerns about data privacy are omnipresent, given the increasing usage of digital applications and their underlying business model that includes selling user data. Location data is particularly sensitive since they allow us to infer activity patterns and interests of users, e.g., by categorizing visited locations based on nearby points of interest (POI). On top of that, machine learning methods provide new powerful tools to interpret big data. In light of these considerations, we raise the following question: What is the actual risk that realistic, machine learning based privacy attacks can obtain meaningful semantic information from raw location data, subject to inaccuracies in the data? In response, we present a systematic analysis of two attack scenarios, namely location categorization and user profiling. Experiments on the Foursquare dataset and tracking data demonstrate the potential for abuse of high-quality spatial information, leading to a significant privacy loss even with location inaccuracy of up to 200m. With location obfuscation of more than 1 km, spatial information hardly adds any value, but a high privacy risk solely from temporal information remains. The availability of public context data such as POIs plays a key role in inference based on spatial information. Our findings point out the risks of ever-growing databases of tracking data and spatial context data, which policymakers should consider for privacy regulations, and which could guide individuals in their personal location protection measures.