 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Language Models for Factuality
Nov 14, 2023The fluency and creativity of large pre-trained language models (LLMs) have led to their widespread use, sometimes even as a replacement for traditional search engines. Yet language models are prone to making convincing but factually inaccurate claims, often referred to as 'hallucinations.' These errors can inadvertently spread misinformation or harmfully perpetuate misconceptions. Further, manual fact-checking of model responses is a time-consuming process, making human factuality labels expensive to acquire. In this work, we fine-tune language models to be more factual, without human labeling and targeting more open-ended generation settings than past work. We leverage two key recent innovations in NLP to do so. First, several recent works have proposed methods for judging the factuality of open-ended text by measuring consistency with an external knowledge base or simply a large model's confidence scores. Second, the direct preference optimization algorithm enables straightforward fine-tuning of language models on objectives other than supervised imitation, using a preference ranking over possible model responses. We show that learning from automatically generated factuality preference rankings, generated either through existing retrieval systems or our novel retrieval-free approach, significantly improves the factuality (percent of generated claims that are correct) of Llama-2 on held-out topics compared with RLHF or decoding strategies targeted at factuality. At 7B scale, compared to Llama-2-chat, we observe 58% and 40% reduction in factual error rate when generating biographies and answering medical questions, respectively.
Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback
May 24, 2023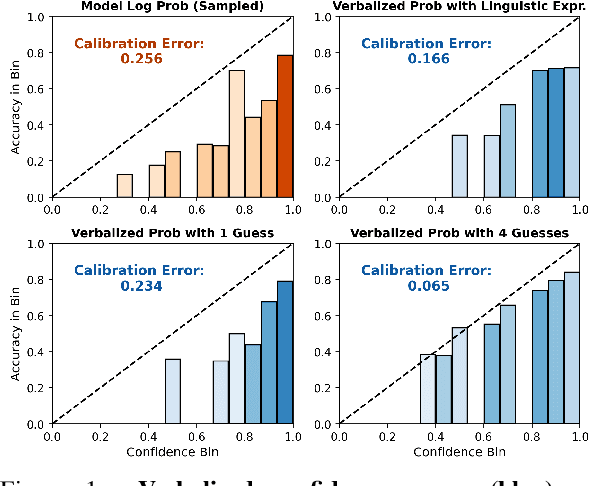
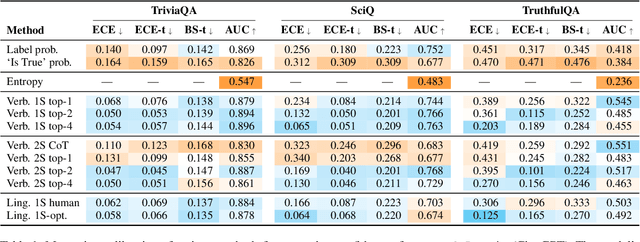
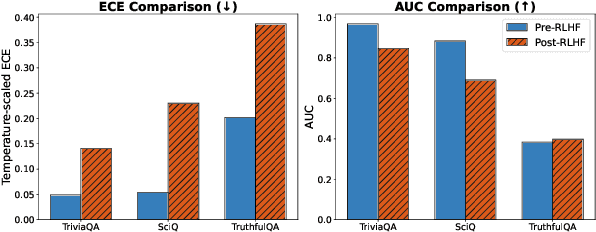
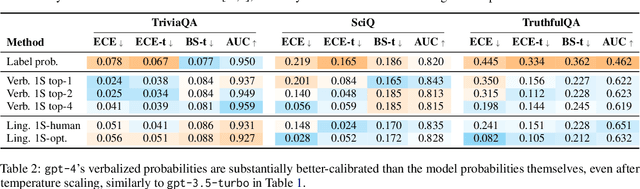
A trustworthy real-world prediction system should be well-calibrated; that is, its confidence in an answer is indicative of the likelihood that the answer is correct, enabling deferral to a more expensive expert in cases of low-confidence predictions. While recent studies have shown that unsupervised pre-training produces large language models (LMs) that are remarkably well-calibrated, the most widely-used LMs in practice are fine-tuned with reinforcement learning with human feedback (RLHF-LMs) after the initial unsupervised pre-training stage, and results are mixed as to whether these models preserve the well-calibratedness of their ancestors. In this paper, we conduct a broad evaluation of computationally feasible methods for extracting confidence scores from LLMs fine-tuned with RLHF. We find that with the right prompting strategy, RLHF-LMs verbalize probabilities that are much better calibrated than the model's conditional probabilities, enabling fairly well-calibrated predictions. Through a combination of prompting strategy and temperature scaling, we find that we can reduce the expected calibration error of RLHF-LMs by over 50%.
Multimodal Image-Text Matching Improves Retrieval-based Chest X-Ray Report Generation
Mar 29, 2023
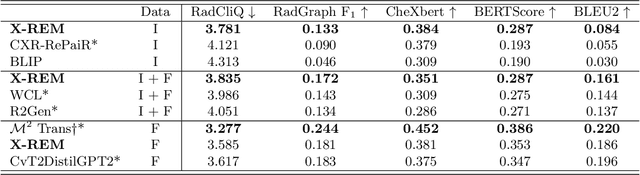
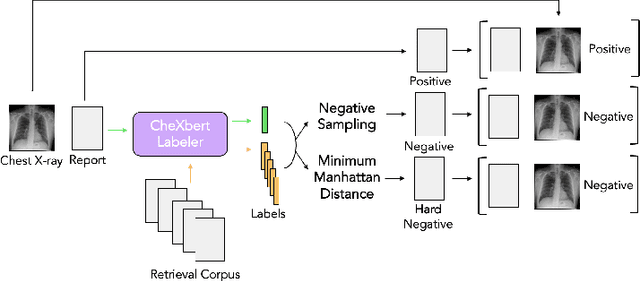

Automated generation of clinically accurate radiology reports can improve patient care. Previous report generation methods that rely on image captioning models often generate incoherent and incorrect text due to their lack of relevant domain knowledge, while retrieval-based attempts frequently retrieve reports that are irrelevant to the input image. In this work, we propose Contrastive X-Ray REport Match (X-REM), a novel retrieval-based radiology report generation module that uses an image-text matching score to measure the similarity of a chest X-ray image and radiology report for report retrieval. We observe that computing the image-text matching score with a language-image model can effectively capture the fine-grained interaction between image and text that is often lost when using cosine similarity. X-REM outperforms multiple prior radiology report generation modules in terms of both natural language and clinical metrics. Human evaluation of the generated reports suggests that X-REM increased the number of zero-error reports and decreased the average error severity compared to the baseline retrieval approach. Our code is available at: https://github.com/rajpurkarlab/X-REM
Doubly robust nearest neighbors in factor models
Nov 28, 2022In this technical note, we introduce an improved variant of nearest neighbors for counterfactual inference in panel data settings where multiple units are assigned multiple treatments over multiple time points, each sampled with constant probabilities. We call this estimator a doubly robust nearest neighbor estimator and provide a high probability non-asymptotic error bound for the mean parameter corresponding to each unit at each time. Our guarantee shows that the doubly robust estimator provides a (near-)quadratic improvement in the error compared to nearest neighbor estimators analyzed in prior work for these settings.
TF-MoDISco v0.4.4.2-alpha: Technical Note
Oct 31, 2018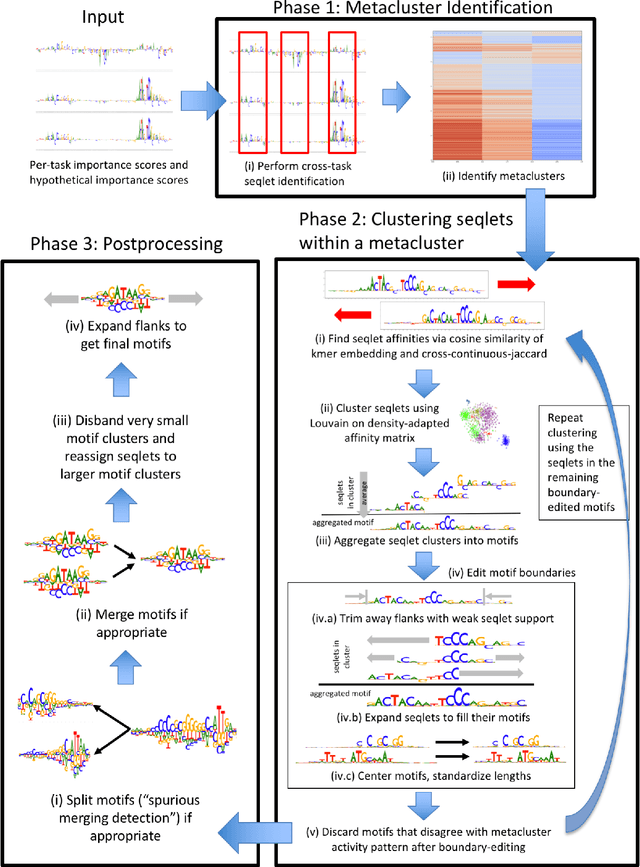
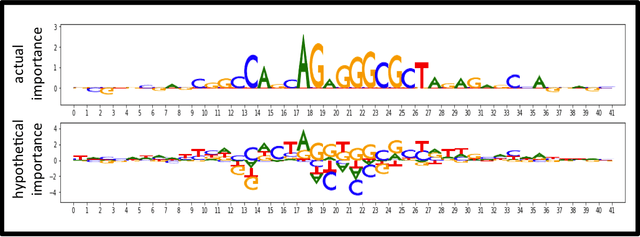
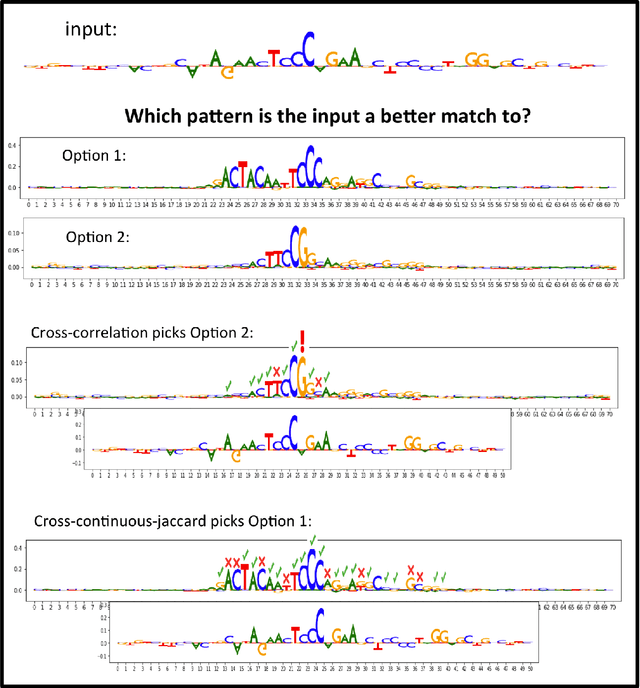
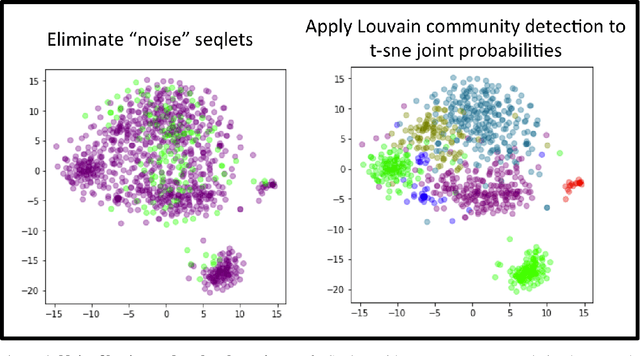
TF-MoDISco (Transcription Factor Motif Discovery from Importance Scores) is an algorithm for identifying motifs from basepair-level importance scores computed on genomic sequence data. This paper describes the methods behind TF-MoDISco version 0.4.4.2-alpha (available at https://github.com/kundajelab/tfmodisco/tree/v0.4.2.2-alpha).