 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback
Paper and Code
May 24, 2023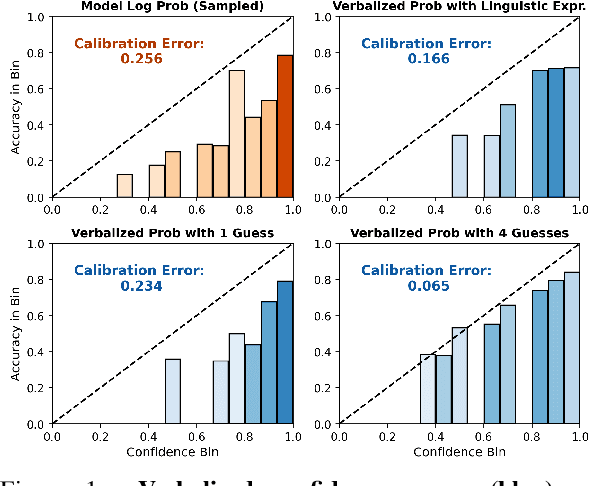
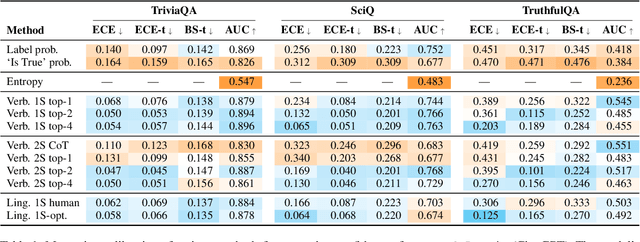
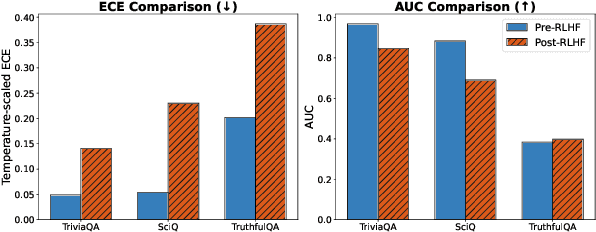
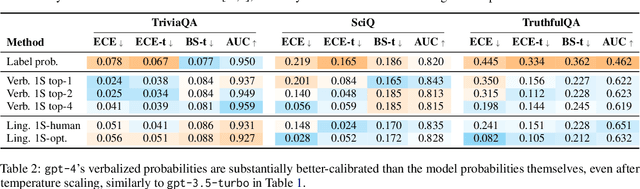
A trustworthy real-world prediction system should be well-calibrated; that is, its confidence in an answer is indicative of the likelihood that the answer is correct, enabling deferral to a more expensive expert in cases of low-confidence predictions. While recent studies have shown that unsupervised pre-training produces large language models (LMs) that are remarkably well-calibrated, the most widely-used LMs in practice are fine-tuned with reinforcement learning with human feedback (RLHF-LMs) after the initial unsupervised pre-training stage, and results are mixed as to whether these models preserve the well-calibratedness of their ancestors. In this paper, we conduct a broad evaluation of computationally feasible methods for extracting confidence scores from LLMs fine-tuned with RLHF. We find that with the right prompting strategy, RLHF-LMs verbalize probabilities that are much better calibrated than the model's conditional probabilities, enabling fairly well-calibrated predictions. Through a combination of prompting strategy and temperature scaling, we find that we can reduce the expected calibration error of RLHF-LMs by over 50%.