 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Graph Generation by Iterative Message Passing
Paper and Code

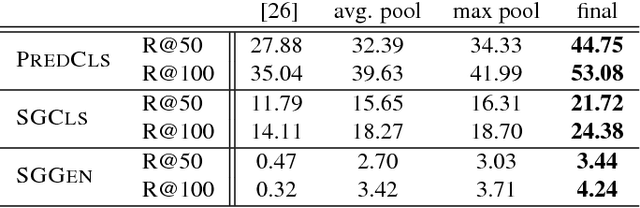
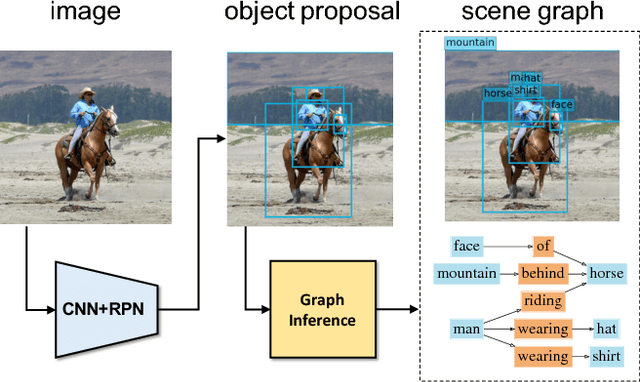
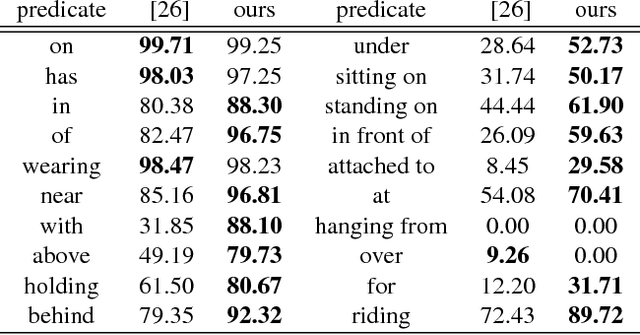
Understanding a visual scene goes beyond recognizing individual objects in isolation. Relationships between objects also constitute rich semantic information about the scene. In this work, we explicitly model the objects and their relationships using scene graphs, a visually-grounded graphical structure of an image. We propose a novel end-to-end model that generates such structured scene representation from an input image. The model solves the scene graph inference problem using standard RNNs and learns to iteratively improves its predictions via message passing. Our joint inference model can take advantage of contextual cues to make better predictions on objects and their relationships. The experiments show that our model significantly outperforms previous methods for generating scene graphs using Visual Genome dataset and inferring support relations with NYU Depth v2 dataset.