 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveGPT: Scaling Autoregressive Behavior Models for Driving
Dec 19, 2024



We present DriveGPT, a scalable behavior model for autonomous driving. We model driving as a sequential decision making task, and learn a transformer model to predict future agent states as tokens in an autoregressive fashion. We scale up our model parameters and training data by multiple orders of magnitude, enabling us to explore the scaling properties in terms of dataset size, model parameters, and compute. We evaluate DriveGPT across different scales in a planning task, through both quantitative metrics and qualitative examples including closed-loop driving in complex real-world scenarios. In a separate prediction task, DriveGPT outperforms a state-of-the-art baseline and exhibits improved performance by pretraining on a large-scale dataset, further validating the benefits of data scaling.
HR-Depth: High Resolution Self-Supervised Monocular Depth Estimation
Dec 14, 2020
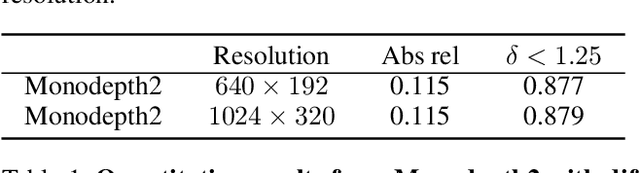
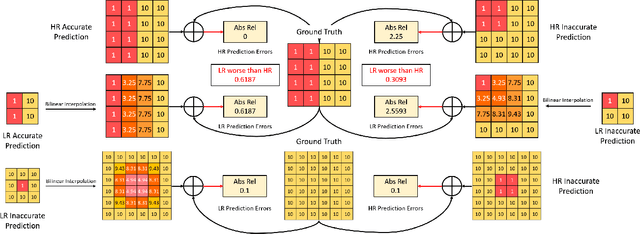

Self-supervised learning shows great potential in monoculardepth estimation, using image sequences as the only source ofsupervision. Although people try to use the high-resolutionimage for depth estimation, the accuracy of prediction hasnot been significantly improved. In this work, we find thecore reason comes from the inaccurate depth estimation inlarge gradient regions, making the bilinear interpolation er-ror gradually disappear as the resolution increases. To obtainmore accurate depth estimation in large gradient regions, itis necessary to obtain high-resolution features with spatialand semantic information. Therefore, we present an improvedDepthNet, HR-Depth, with two effective strategies: (1) re-design the skip-connection in DepthNet to get better high-resolution features and (2) propose feature fusion Squeeze-and-Excitation(fSE) module to fuse feature more efficiently.Using Resnet-18 as the encoder, HR-Depth surpasses all pre-vious state-of-the-art(SoTA) methods with the least param-eters at both high and low resolution. Moreover, previousstate-of-the-art methods are based on fairly complex and deepnetworks with a mass of parameters which limits their realapplications. Thus we also construct a lightweight networkwhich uses MobileNetV3 as encoder. Experiments show thatthe lightweight network can perform on par with many largemodels like Monodepth2 at high-resolution with only20%parameters. All codes and models will be available at https://github.com/shawLyu/HR-Depth.