 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRV-FuseNet: Range View based Fusion of Time-Series LiDAR Data for Joint 3D Object Detection and Motion Forecasting
Paper and Code
May 21, 2020
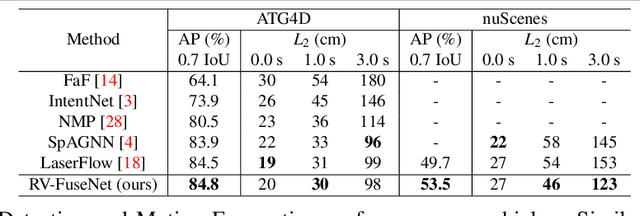
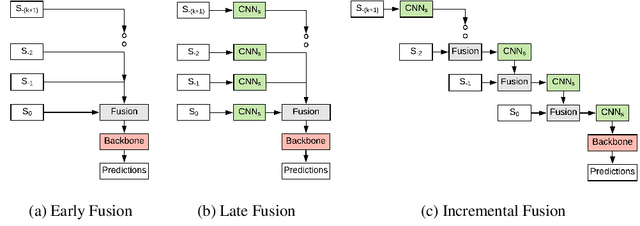

Autonomous vehicles rely on robust real-time detection and future motion prediction of traffic participants to safely navigate urban environments. We present a novel end-to-end approach that uses raw time-series LiDAR data to jointly solve both detection and prediction. We use the range view representation of LiDAR instead of voxelization since it does not discard information and is more efficient due to its compactness. However, for time-series fusion the data needs to be projected to a common viewpoint, and often this viewpoint is different from where it was captured leading to distortions. These distortions have an adverse impact on performance. Thus, we propose a novel architecture which reduces the impact of distortions by sequentially projecting each sweep into the viewpoint of the next sweep in time. We demonstrate that our sequential fusion approach is superior to methods that directly project all the data into the most recent viewpoint. Furthermore, we compare our approach to existing state-of-the art methods on multiple autonomous driving datasets and show competitive results.