 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture-Interactions-Aware Trajectory Prediction via Braid Theory
Mar 23, 2026To safely operate, an autonomous vehicle must know the future behavior of a potentially high number of interacting agents around it, a task often posed as multi-agent trajectory prediction. Many previous attempts to model social interactions and solve the joint prediction task either add extensive computational requirements or rely on heuristics to label multi-agent behavior types. Braid theory, in contrast, provides a powerful exact descriptor of multi-agent behavior by projecting future trajectories into braids that express how trajectories cross with each other over time; a braid then corresponds to a specific mode of coordination between the multiple agents in the future. In past work, braids have been used lightly to reason about interacting agents and restrict the attention window of predicted agents. We show that leveraging more fully the expressivity of the braid representation and using it to condition the trajectories themselves leads to even further gains in joint prediction performance, with negligible added complexity either in training or at inference time. We do so by proposing a novel auxiliary task, braid prediction, done in parallel with the trajectory prediction task. By classifying edges between agents into their correct crossing types in the braid representation, the braid prediction task is able to imbue the model with improved social awareness, which is reflected in joint predictions that more closely adhere to the actual multi-agent behavior. This simple auxiliary task allowed us to obtain significant improvements in joint metrics on three separate datasets. We show how the braid prediction task infuses the model with future intention awareness, leading to more accurate joint predictions. Code is available at github.com/caiocj1/traj-pred-braid-theory.
Improving Consistency in Vehicle Trajectory Prediction Through Preference Optimization
Jul 03, 2025Trajectory prediction is an essential step in the pipeline of an autonomous vehicle. Inaccurate or inconsistent predictions regarding the movement of agents in its surroundings lead to poorly planned maneuvers and potentially dangerous situations for the end-user. Current state-of-the-art deep-learning-based trajectory prediction models can achieve excellent accuracy on public datasets. However, when used in more complex, interactive scenarios, they often fail to capture important interdependencies between agents, leading to inconsistent predictions among agents in the traffic scene. Inspired by the efficacy of incorporating human preference into large language models, this work fine-tunes trajectory prediction models in multi-agent settings using preference optimization. By taking as input automatically calculated preference rankings among predicted futures in the fine-tuning process, our experiments--using state-of-the-art models on three separate datasets--show that we are able to significantly improve scene consistency while minimally sacrificing trajectory prediction accuracy and without adding any excess computational requirements at inference time.
Optimizing Diffusion Models for Joint Trajectory Prediction and Controllable Generation
Aug 01, 2024



Diffusion models are promising for joint trajectory prediction and controllable generation in autonomous driving, but they face challenges of inefficient inference steps and high computational demands. To tackle these challenges, we introduce Optimal Gaussian Diffusion (OGD) and Estimated Clean Manifold (ECM) Guidance. OGD optimizes the prior distribution for a small diffusion time $T$ and starts the reverse diffusion process from it. ECM directly injects guidance gradients to the estimated clean manifold, eliminating extensive gradient backpropagation throughout the network. Our methodology streamlines the generative process, enabling practical applications with reduced computational overhead. Experimental validation on the large-scale Argoverse 2 dataset demonstrates our approach's superior performance, offering a viable solution for computationally efficient, high-quality joint trajectory prediction and controllable generation for autonomous driving. Our project webpage is at https://yixiaowang7.github.io/OptTrajDiff_Page/.
Exploiting map information for self-supervised learning in motion forecasting
Oct 10, 2022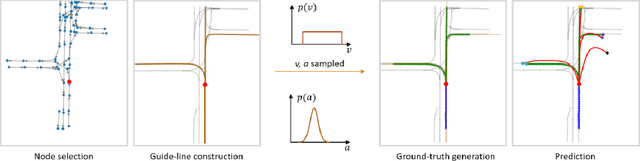
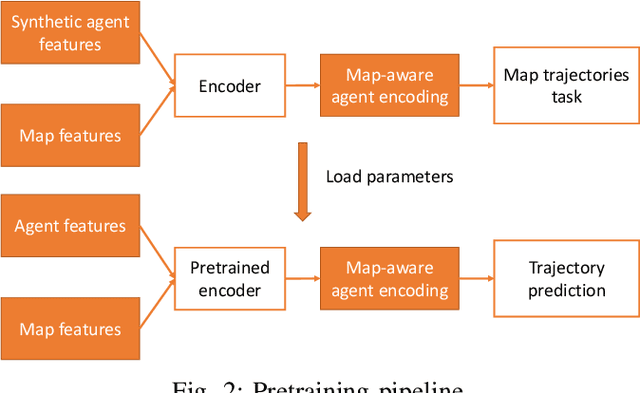
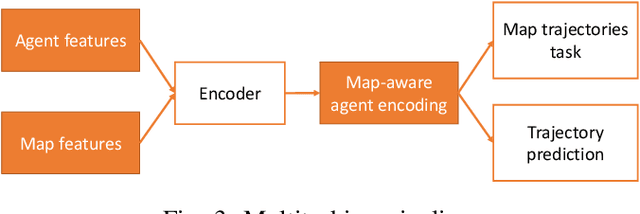
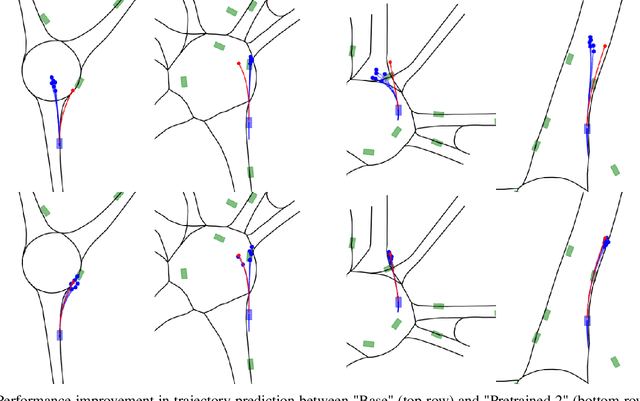
Inspired by recent developments regarding the application of self-supervised learning (SSL), we devise an auxiliary task for trajectory prediction that takes advantage of map-only information such as graph connectivity with the intent of improving map comprehension and generalization. We apply this auxiliary task through two frameworks - multitasking and pretraining. In either framework we observe significant improvement of our baseline in metrics such as $\mathrm{minFDE}_6$ (as much as 20.3%) and $\mathrm{MissRate}_6$ (as much as 33.3%), as well as a richer comprehension of map features demonstrated by different training configurations. The results obtained were consistent in all three data sets used for experiments: Argoverse, Interaction and NuScenes. We also submit our new pretrained model's results to the Interaction challenge and achieve $\textit{1st}$ place with respect to $\mathrm{minFDE}_6$ and $\mathrm{minADE}_6$.
Exploring the trade off between human driving imitation and safety for traffic simulation
Aug 09, 2022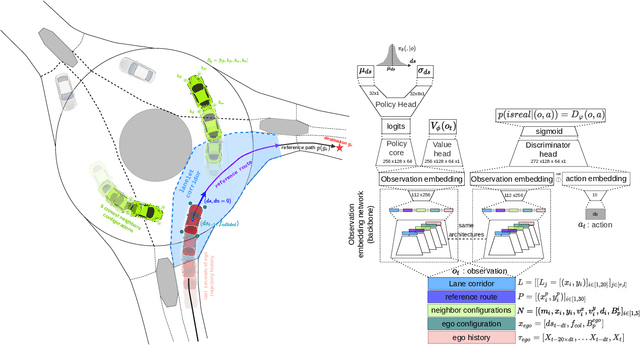
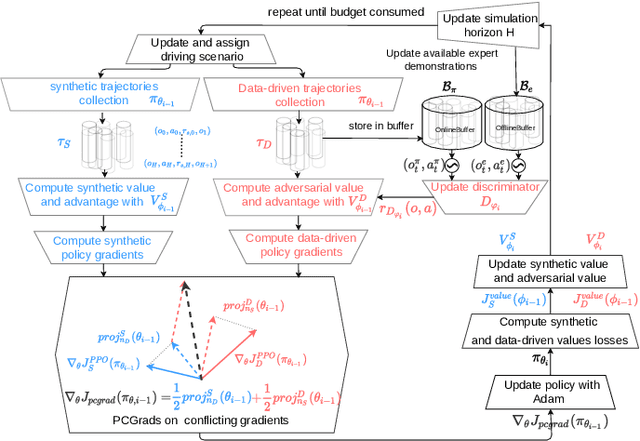

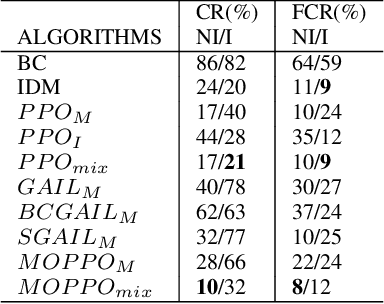
Traffic simulation has gained a lot of interest for quantitative evaluation of self driving vehicles performance. In order for a simulator to be a valuable test bench, it is required that the driving policy animating each traffic agent in the scene acts as humans would do while maintaining minimal safety guarantees. Learning the driving policies of traffic agents from recorded human driving data or through reinforcement learning seems to be an attractive solution for the generation of realistic and highly interactive traffic situations in uncontrolled intersections or roundabouts. In this work, we show that a trade-off exists between imitating human driving and maintaining safety when learning driving policies. We do this by comparing how various Imitation learning and Reinforcement learning algorithms perform when applied to the driving task. We also propose a multi objective learning algorithm (MOPPO) that improves both objectives together. We test our driving policies on highly interactive driving scenarios extracted from INTERACTION Dataset to evaluate how human-like they behave.
Uncertainty estimation for Cross-dataset performance in Trajectory prediction
May 15, 2022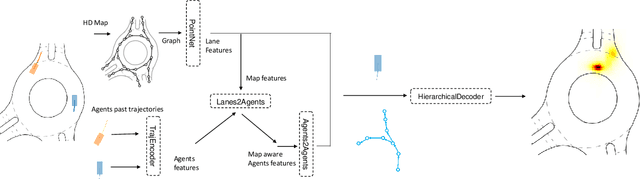
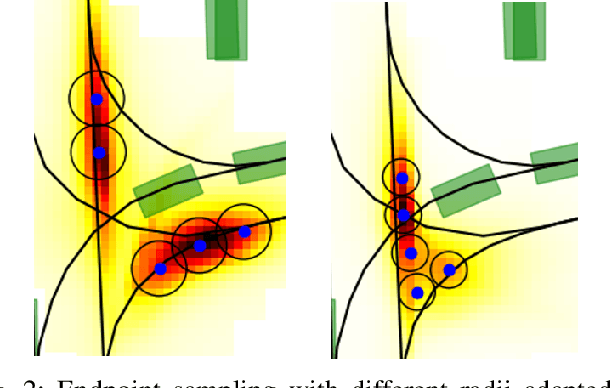
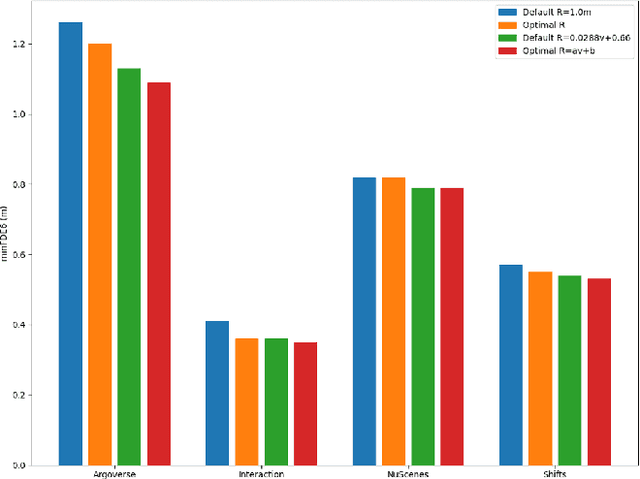
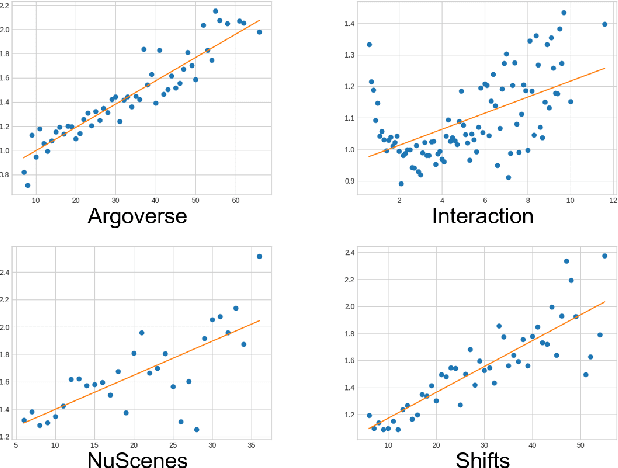
While a lot of work has been done on developing trajectory prediction methods, and various datasets have been proposed for benchmarking this task, little study has been done so far on the generalizability and the transferability of these methods across dataset. In this paper, we study the performance of a state-of-the-art trajectory prediction method across four different datasets (Argoverse, NuScenes, Interaction, Shifts). We first check how a similar method can be applied and trained on all these datasets with similar hyperparameters. Then we highlight which datasets work best on others, and study how uncertainty estimation allows for a better transferable performance; proposing a novel way to estimate uncertainty and to directly use it in prediction.
THOMAS: Trajectory Heatmap Output with learned Multi-Agent Sampling
Oct 17, 2021

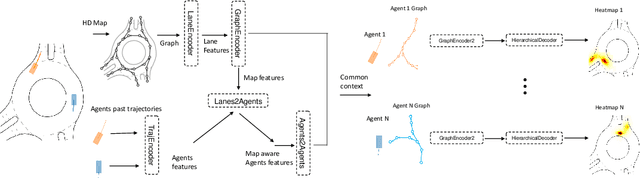

In this paper, we propose THOMAS, a joint multi-agent trajectory prediction framework allowing for efficient and consistent prediction of multi-agent multi-modal trajectories. We present a unified model architecture for fast and simultaneous agent future heatmap estimation leveraging hierarchical and sparse image generation. We demonstrate that heatmap output enables a higher level of control on the predicted trajectories compared to vanilla multi-modal trajectory regression, allowing to incorporate additional constraints for tighter sampling or collision-free predictions in a deterministic way. However, we also highlight that generating scene-consistent predictions goes beyond the mere generation of collision-free trajectories. We therefore propose a learnable trajectory recombination model that takes as input a set of predicted trajectories for each agent and outputs its consistent reordered recombination. We report our results on the Interaction multi-agent prediction challenge and rank $1^{st}$ on the online test leaderboard.
GOHOME: Graph-Oriented Heatmap Output for future Motion Estimation
Sep 21, 2021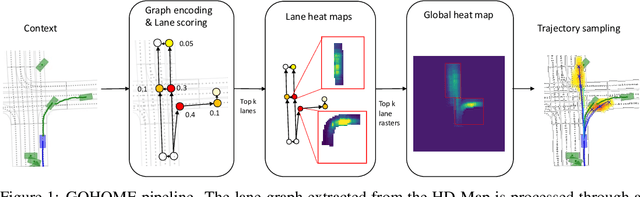
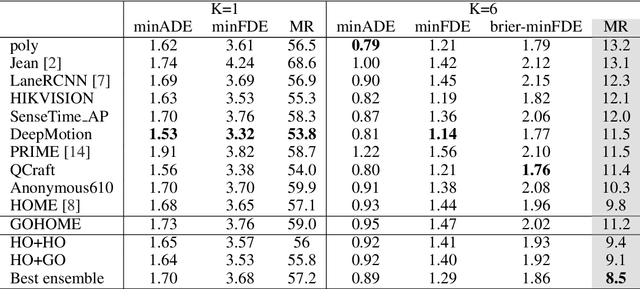
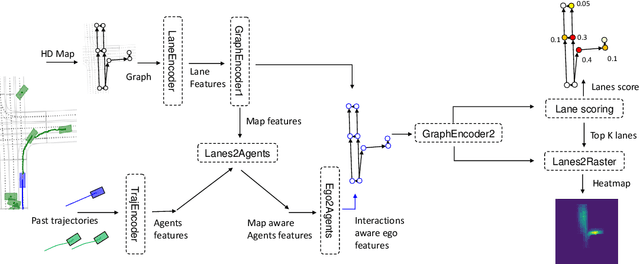
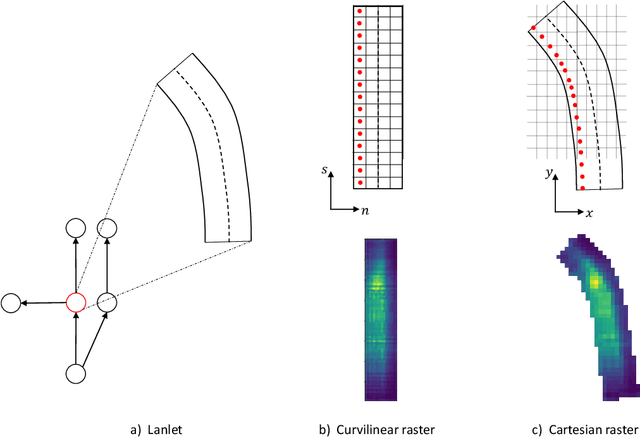
In this paper, we propose GOHOME, a method leveraging graph representations of the High Definition Map and sparse projections to generate a heatmap output representing the future position probability distribution for a given agent in a traffic scene. This heatmap output yields an unconstrained 2D grid representation of agent future possible locations, allowing inherent multimodality and a measure of the uncertainty of the prediction. Our graph-oriented model avoids the high computation burden of representing the surrounding context as squared images and processing it with classical CNNs, but focuses instead only on the most probable lanes where the agent could end up in the immediate future. GOHOME reaches 2$nd$ on Argoverse Motion Forecasting Benchmark on the MissRate$_6$ metric while achieving significant speed-up and memory burden diminution compared to Argoverse 1$^{st}$ place method HOME. We also highlight that heatmap output enables multimodal ensembling and improve 1$^{st}$ place MissRate$_6$ by more than 15$\%$ with our best ensemble on Argoverse. Finally, we evaluate and reach state-of-the-art performance on the other trajectory prediction datasets nuScenes and Interaction, demonstrating the generalizability of our method.
HOME: Heatmap Output for future Motion Estimation
Jun 02, 2021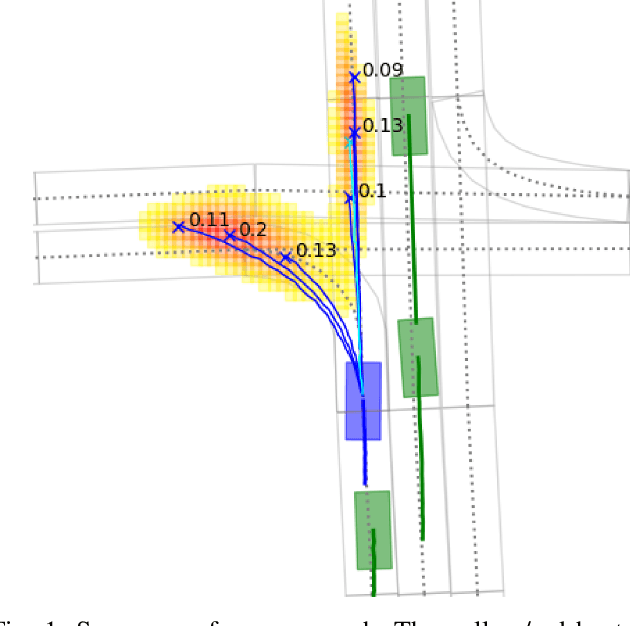

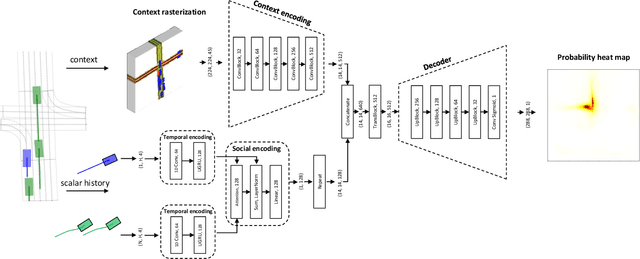
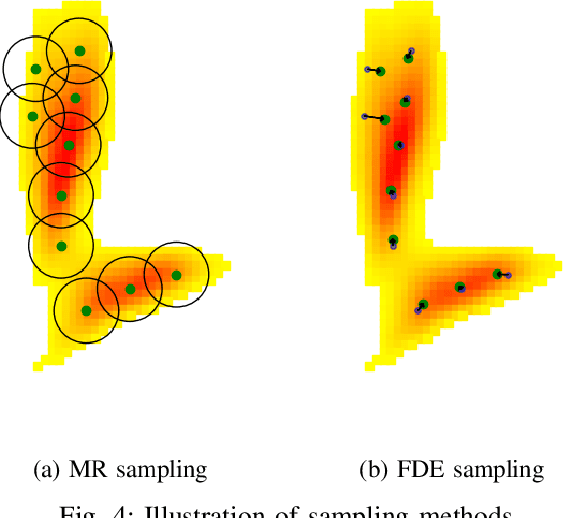
In this paper, we propose HOME, a framework tackling the motion forecasting problem with an image output representing the probability distribution of the agent's future location. This method allows for a simple architecture with classic convolution networks coupled with attention mechanism for agent interactions, and outputs an unconstrained 2D top-view representation of the agent's possible future. Based on this output, we design two methods to sample a finite set of agent's future locations. These methods allow us to control the optimization trade-off between miss rate and final displacement error for multiple modalities without having to retrain any part of the model. We apply our method to the Argoverse Motion Forecasting Benchmark and achieve 1st place on the online leaderboard.