 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Consistency in Vehicle Trajectory Prediction Through Preference Optimization
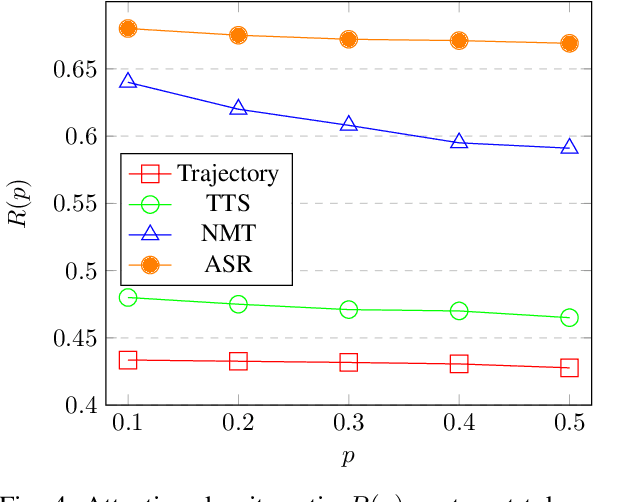
Jul 03, 2025Trajectory prediction is an essential step in the pipeline of an autonomous vehicle. Inaccurate or inconsistent predictions regarding the movement of agents in its surroundings lead to poorly planned maneuvers and potentially dangerous situations for the end-user. Current state-of-the-art deep-learning-based trajectory prediction models can achieve excellent accuracy on public datasets. However, when used in more complex, interactive scenarios, they often fail to capture important interdependencies between agents, leading to inconsistent predictions among agents in the traffic scene. Inspired by the efficacy of incorporating human preference into large language models, this work fine-tunes trajectory prediction models in multi-agent settings using preference optimization. By taking as input automatically calculated preference rankings among predicted futures in the fine-tuning process, our experiments--using state-of-the-art models on three separate datasets--show that we are able to significantly improve scene consistency while minimally sacrificing trajectory prediction accuracy and without adding any excess computational requirements at inference time.
Analysis over vision-based models for pedestrian action anticipation
May 27, 2023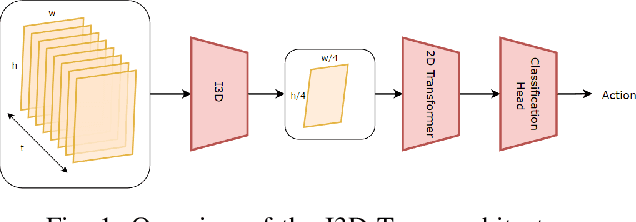
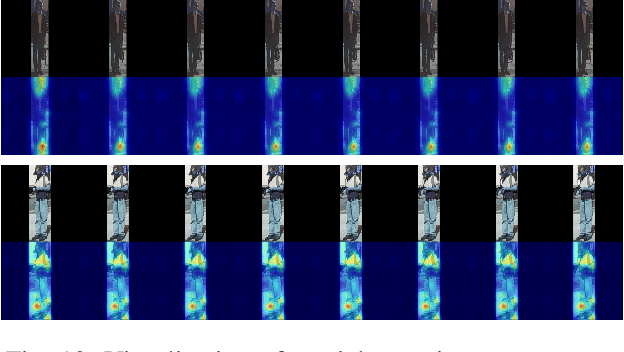

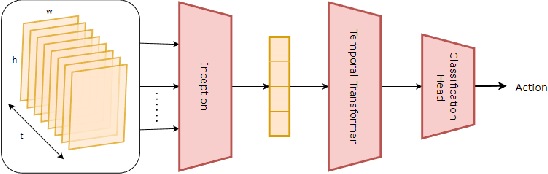
Anticipating human actions in front of autonomous vehicles is a challenging task. Several papers have recently proposed model architectures to address this problem by combining multiple input features to predict pedestrian crossing actions. This paper focuses specifically on using images of the pedestrian's context as an input feature. We present several spatio-temporal model architectures that utilize standard CNN and Transformer modules to serve as a backbone for pedestrian anticipation. However, the objective of this paper is not to surpass state-of-the-art benchmarks but rather to analyze the positive and negative predictions of these models. Therefore, we provide insights on the explainability of vision-based Transformer models in the context of pedestrian action prediction. We will highlight cases where the model can achieve correct quantitative results but falls short in providing human-like explanations qualitatively, emphasizing the importance of investing in explainability for pedestrian action anticipation problems.
PreTR: Spatio-Temporal Non-Autoregressive Trajectory Prediction Transformer
Mar 17, 2022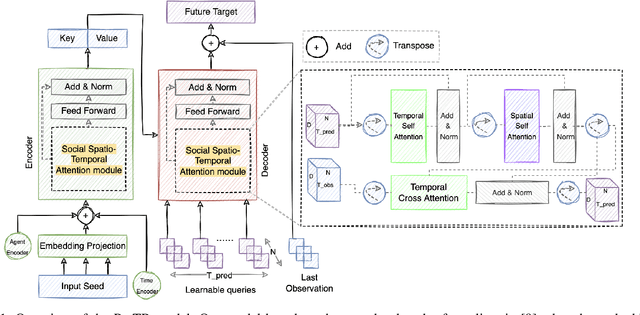
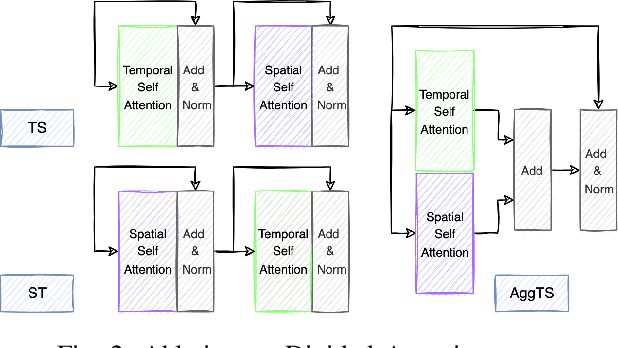
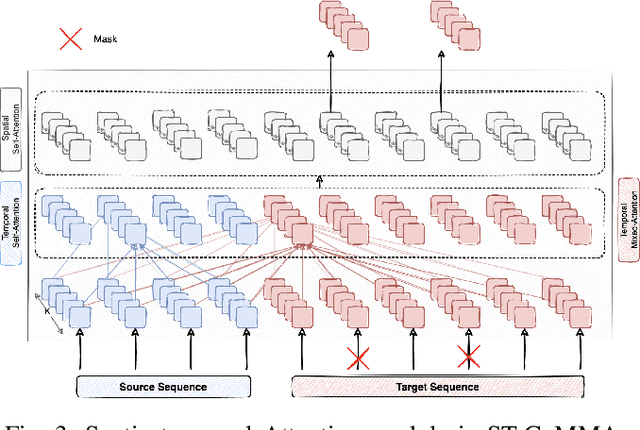
Nowadays, our mobility systems are evolving into the era of intelligent vehicles that aim to improve road safety. Due to their vulnerability, pedestrians are the users who will benefit the most from these developments. However, predicting their trajectory is one of the most challenging concerns. Indeed, accurate prediction requires a good understanding of multi-agent interactions that can be complex. Learning the underlying spatial and temporal patterns caused by these interactions is even more of a competitive and open problem that many researchers are tackling. In this paper, we introduce a model called PRediction Transformer (PReTR) that extracts features from the multi-agent scenes by employing a factorized spatio-temporal attention module. It shows less computational needs than previously studied models with empirically better results. Besides, previous works in motion prediction suffer from the exposure bias problem caused by generating future sequences conditioned on model prediction samples rather than ground-truth samples. In order to go beyond the proposed solutions, we leverage encoder-decoder Transformer networks for parallel decoding a set of learned object queries. This non-autoregressive solution avoids the need for iterative conditioning and arguably decreases training and testing computational time. We evaluate our model on the ETH/UCY datasets, a publicly available benchmark for pedestrian trajectory prediction. Finally, we justify our usage of the parallel decoding technique by showing that the trajectory prediction task can be better solved as a non-autoregressive task.
Is attention to bounding boxes all you need for pedestrian action prediction?
Jul 16, 2021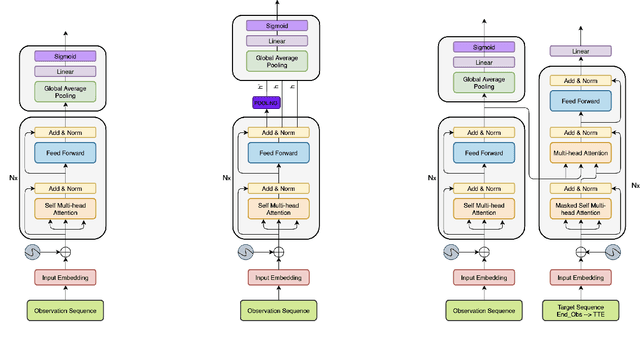


The human driver is no longer the only one concerned with the complexity of the driving scenarios. Autonomous vehicles (AV) are similarly becoming involved in the process. Nowadays, the development of AV in urban places underpins essential safety concerns for vulnerable road users (VRUs) such as pedestrians. Therefore, to make the roads safer, it is critical to classify and predict their future behavior. In this paper, we present a framework based on multiple variations of the Transformer models to reason attentively about the dynamic evolution of the pedestrians' past trajectory and predict its future actions of crossing or not crossing the street. We proved that using only bounding boxes as input to our model can outperform the previous state-of-the-art models and reach a prediction accuracy of 91 % and an F1-score of 0.83 on the PIE dataset up to two seconds ahead in the future. In addition, we introduced a large-size simulated dataset (CP2A) using CARLA for action prediction. Our model has similarly reached high accuracy (91 %) and F1-score (0.91) on this dataset. Interestingly, we showed that pre-training our Transformer model on the simulated dataset and then fine-tuning it on the real dataset can be very effective for the action prediction task.