 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreTR: Spatio-Temporal Non-Autoregressive Trajectory Prediction Transformer
Paper and Code
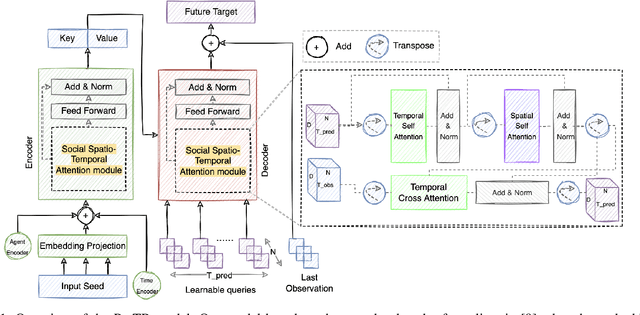
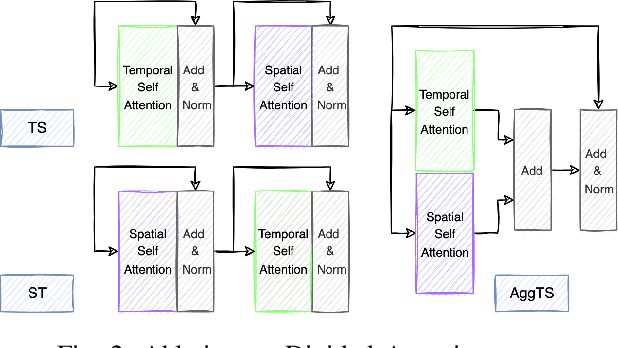
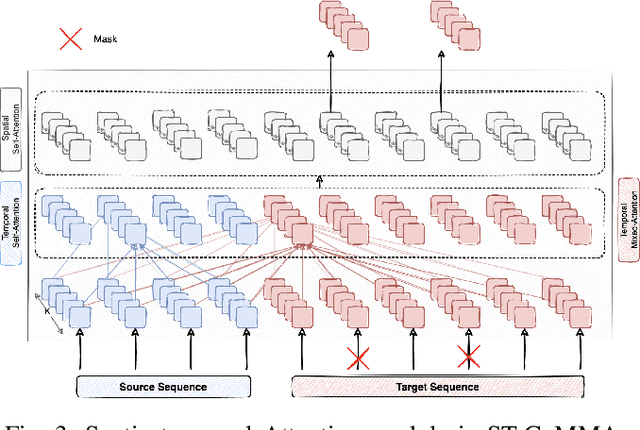
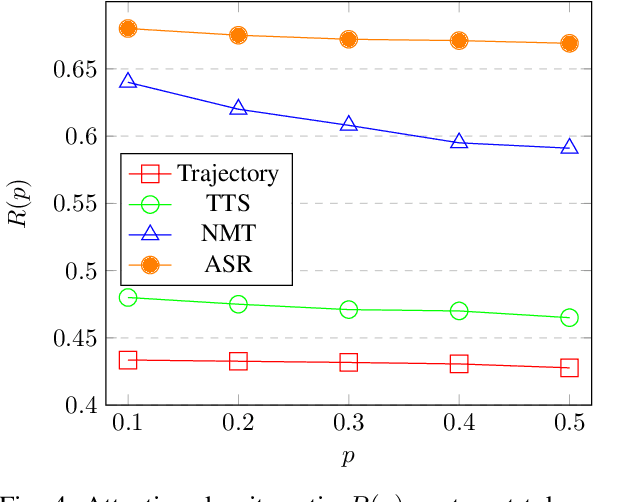
Nowadays, our mobility systems are evolving into the era of intelligent vehicles that aim to improve road safety. Due to their vulnerability, pedestrians are the users who will benefit the most from these developments. However, predicting their trajectory is one of the most challenging concerns. Indeed, accurate prediction requires a good understanding of multi-agent interactions that can be complex. Learning the underlying spatial and temporal patterns caused by these interactions is even more of a competitive and open problem that many researchers are tackling. In this paper, we introduce a model called PRediction Transformer (PReTR) that extracts features from the multi-agent scenes by employing a factorized spatio-temporal attention module. It shows less computational needs than previously studied models with empirically better results. Besides, previous works in motion prediction suffer from the exposure bias problem caused by generating future sequences conditioned on model prediction samples rather than ground-truth samples. In order to go beyond the proposed solutions, we leverage encoder-decoder Transformer networks for parallel decoding a set of learned object queries. This non-autoregressive solution avoids the need for iterative conditioning and arguably decreases training and testing computational time. We evaluate our model on the ETH/UCY datasets, a publicly available benchmark for pedestrian trajectory prediction. Finally, we justify our usage of the parallel decoding technique by showing that the trajectory prediction task can be better solved as a non-autoregressive task.