 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis over vision-based models for pedestrian action anticipation
Paper and Code
May 27, 2023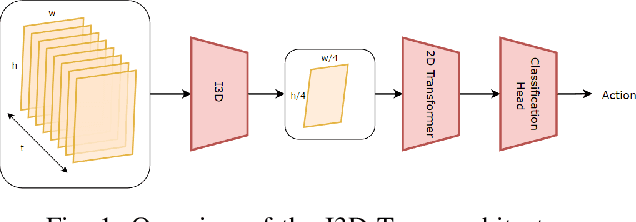
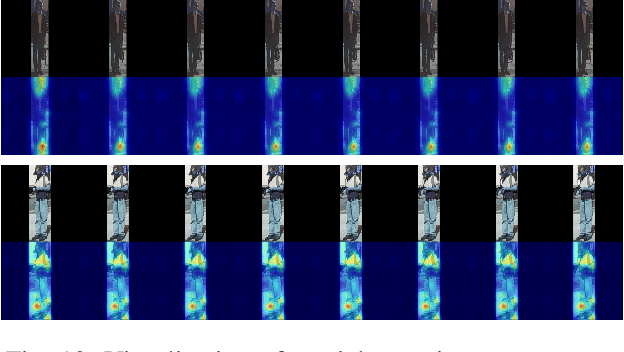

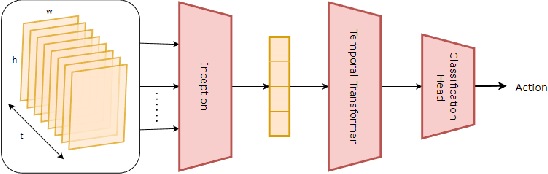
Anticipating human actions in front of autonomous vehicles is a challenging task. Several papers have recently proposed model architectures to address this problem by combining multiple input features to predict pedestrian crossing actions. This paper focuses specifically on using images of the pedestrian's context as an input feature. We present several spatio-temporal model architectures that utilize standard CNN and Transformer modules to serve as a backbone for pedestrian anticipation. However, the objective of this paper is not to surpass state-of-the-art benchmarks but rather to analyze the positive and negative predictions of these models. Therefore, we provide insights on the explainability of vision-based Transformer models in the context of pedestrian action prediction. We will highlight cases where the model can achieve correct quantitative results but falls short in providing human-like explanations qualitatively, emphasizing the importance of investing in explainability for pedestrian action anticipation problems.