 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Pixels: Leveraging the Language of Soccer to Improve Spatio-Temporal Action Detection in Broadcast Videos
May 14, 2025State-of-the-art spatio-temporal action detection (STAD) methods show promising results for extracting soccer events from broadcast videos. However, when operated in the high-recall, low-precision regime required for exhaustive event coverage in soccer analytics, their lack of contextual understanding becomes apparent: many false positives could be resolved by considering a broader sequence of actions and game-state information. In this work, we address this limitation by reasoning at the game level and improving STAD through the addition of a denoising sequence transduction task. Sequences of noisy, context-free player-centric predictions are processed alongside clean game state information using a Transformer-based encoder-decoder model. By modeling extended temporal context and reasoning jointly over team-level dynamics, our method leverages the "language of soccer" - its tactical regularities and inter-player dependencies - to generate "denoised" sequences of actions. This approach improves both precision and recall in low-confidence regimes, enabling more reliable event extraction from broadcast video and complementing existing pixel-based methods.
Game State and Spatio-temporal Action Detection in Soccer using Graph Neural Networks and 3D Convolutional Networks
Feb 21, 2025



Soccer analytics rely on two data sources: the player positions on the pitch and the sequences of events they perform. With around 2000 ball events per game, their precise and exhaustive annotation based on a monocular video stream remains a tedious and costly manual task. While state-of-the-art spatio-temporal action detection methods show promise for automating this task, they lack contextual understanding of the game. Assuming professional players' behaviors are interdependent, we hypothesize that incorporating surrounding players' information such as positions, velocity and team membership can enhance purely visual predictions. We propose a spatio-temporal action detection approach that combines visual and game state information via Graph Neural Networks trained end-to-end with state-of-the-art 3D CNNs, demonstrating improved metrics through game state integration.
LED: Light Enhanced Depth Estimation at Night
Sep 12, 2024



Nighttime camera-based depth estimation is a highly challenging task, especially for autonomous driving applications, where accurate depth perception is essential for ensuring safe navigation. We aim to improve the reliability of perception systems at night time, where models trained on daytime data often fail in the absence of precise but costly LiDAR sensors. In this work, we introduce Light Enhanced Depth (LED), a novel cost-effective approach that significantly improves depth estimation in low-light environments by harnessing a pattern projected by high definition headlights available in modern vehicles. LED leads to significant performance boosts across multiple depth-estimation architectures (encoder-decoder, Adabins, DepthFormer) both on synthetic and real datasets. Furthermore, increased performances beyond illuminated areas reveal a holistic enhancement in scene understanding. Finally, we release the Nighttime Synthetic Drive Dataset, a new synthetic and photo-realistic nighttime dataset, which comprises 49,990 comprehensively annotated images.
TSGN: Temporal Scene Graph Neural Networks with Projected Vectorized Representation for Multi-Agent Motion Prediction
May 14, 2023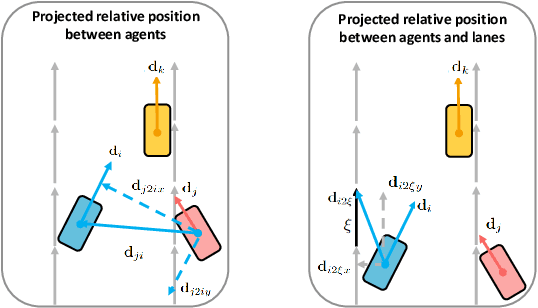
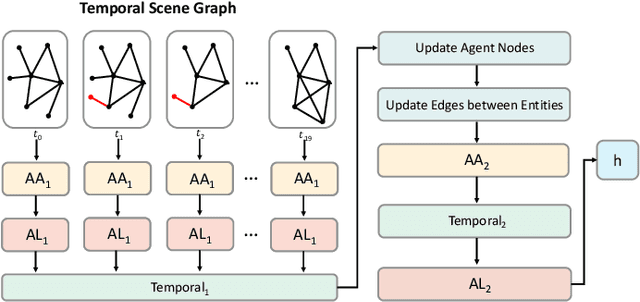
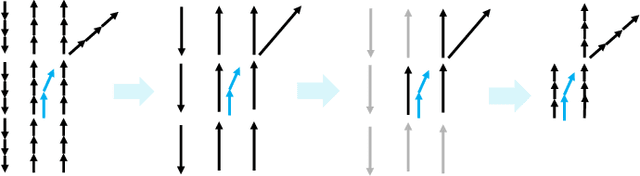
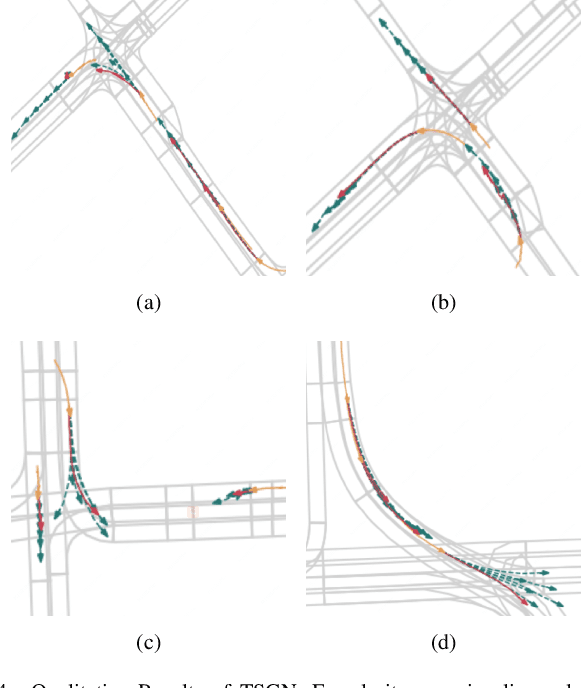
Predicting future motions of nearby agents is essential for an autonomous vehicle to take safe and effective actions. In this paper, we propose TSGN, a framework using Temporal Scene Graph Neural Networks with projected vectorized representations for multi-agent trajectory prediction. Projected vectorized representation models the traffic scene as a graph which is constructed by a set of vectors. These vectors represent agents, road network, and their spatial relative relationships. All relative features under this representation are both translationand rotation-invariant. Based on this representation, TSGN captures the spatial-temporal features across agents, road network, interactions among them, and temporal dependencies of temporal traffic scenes. TSGN can predict multimodal future trajectories for all agents simultaneously, plausibly, and accurately. Meanwhile, we propose a Hierarchical Lane Transformer for capturing interactions between agents and road network, which filters the surrounding road network and only keeps the most probable lane segments which could have an impact on the future behavior of the target agent. Without sacrificing the prediction performance, this greatly reduces the computational burden. Experiments show TSGN achieves state-of-the-art performance on the Argoverse motion forecasting benchmar.
CROSSFIRE: Camera Relocalization On Self-Supervised Features from an Implicit Representation
Mar 08, 2023
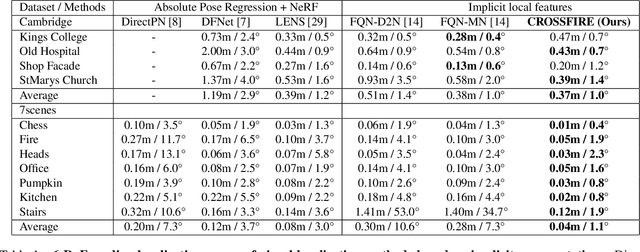
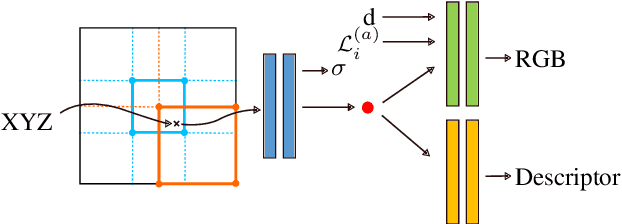
Beyond novel view synthesis, Neural Radiance Fields are useful for applications that interact with the real world. In this paper, we use them as an implicit map of a given scene and propose a camera relocalization algorithm tailored for this representation. The proposed method enables to compute in real-time the precise position of a device using a single RGB camera, during its navigation. In contrast with previous work, we do not rely on pose regression or photometric alignment but rather use dense local features obtained through volumetric rendering which are specialized on the scene with a self-supervised objective. As a result, our algorithm is more accurate than competitors, able to operate in dynamic outdoor environments with changing lightning conditions and can be readily integrated in any volumetric neural renderer.
Uncertainty estimation for Cross-dataset performance in Trajectory prediction
May 15, 2022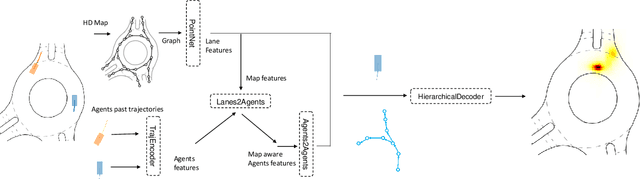
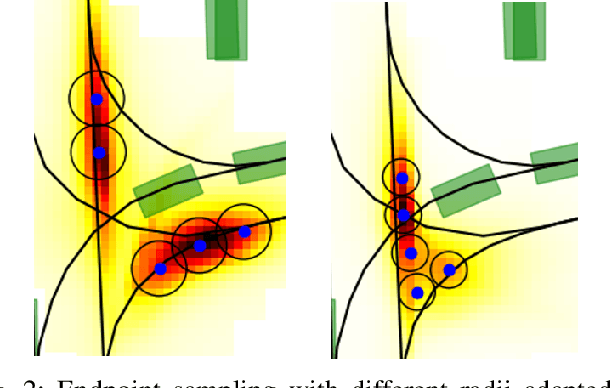
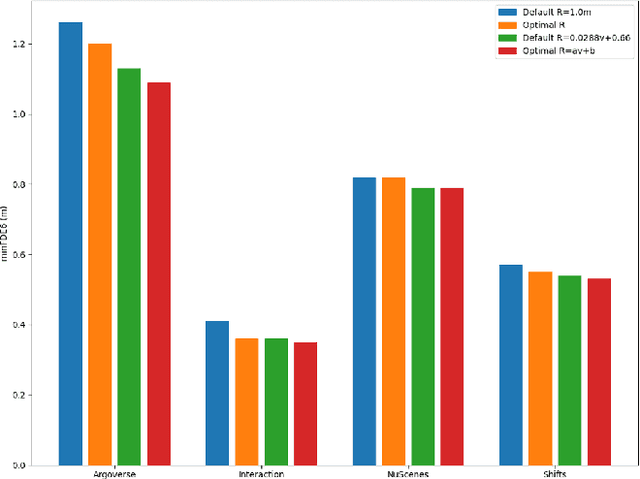
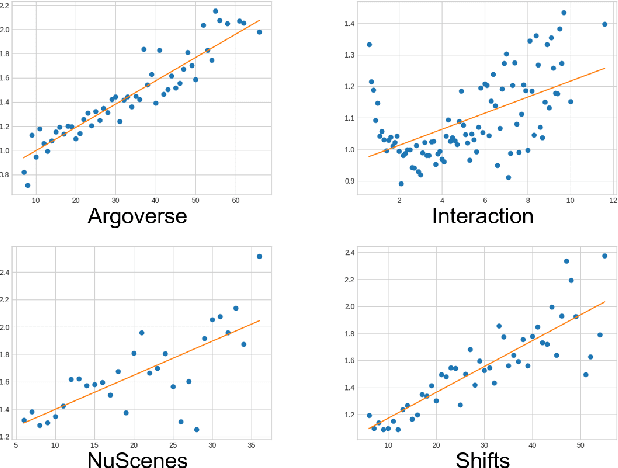
While a lot of work has been done on developing trajectory prediction methods, and various datasets have been proposed for benchmarking this task, little study has been done so far on the generalizability and the transferability of these methods across dataset. In this paper, we study the performance of a state-of-the-art trajectory prediction method across four different datasets (Argoverse, NuScenes, Interaction, Shifts). We first check how a similar method can be applied and trained on all these datasets with similar hyperparameters. Then we highlight which datasets work best on others, and study how uncertainty estimation allows for a better transferable performance; proposing a novel way to estimate uncertainty and to directly use it in prediction.
ImPosIng: Implicit Pose Encoding for Efficient Camera Pose Estimation
May 05, 2022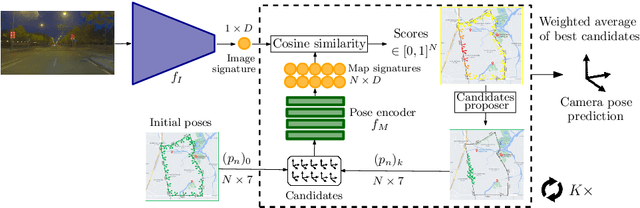
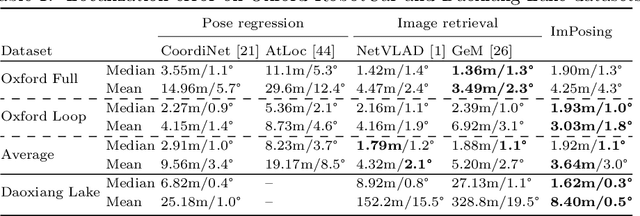


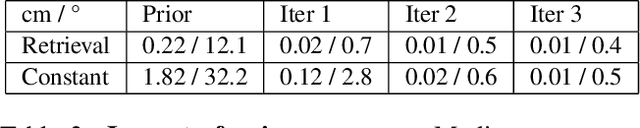
We propose a novel learning-based formulation for camera pose estimation that can perform relocalization accurately and in real-time in city-scale environments. Camera pose estimation algorithms determine the position and orientation from which an image has been captured, using a set of geo-referenced images or 3D scene representation. Our new localization paradigm, named Implicit Pose Encoding (ImPosing), embeds images and camera poses into a common latent representation with 2 separate neural networks, such that we can compute a similarity score for each image-pose pair. By evaluating candidates through the latent space in a hierarchical manner, the camera position and orientation are not directly regressed but incrementally refined. Compared to the representation used in structure-based relocalization methods, our implicit map is memory bounded and can be properly explored to improve localization performances against learning-based regression approaches. In this paper, we describe how to effectively optimize our learned modules, how to combine them to achieve real-time localization, and demonstrate results on diverse large scale scenarios that significantly outperform prior work in accuracy and computational efficiency.
Assessing Cross-dataset Generalization of Pedestrian Crossing Predictors
Jan 29, 2022
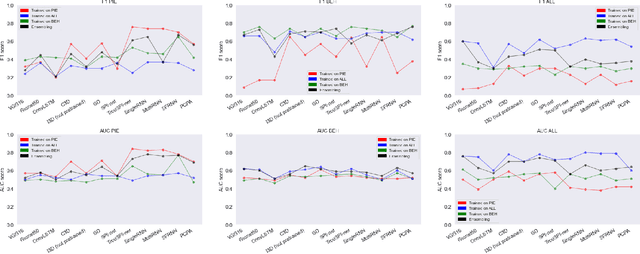
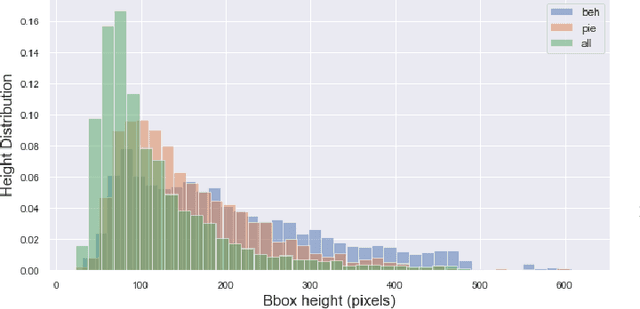
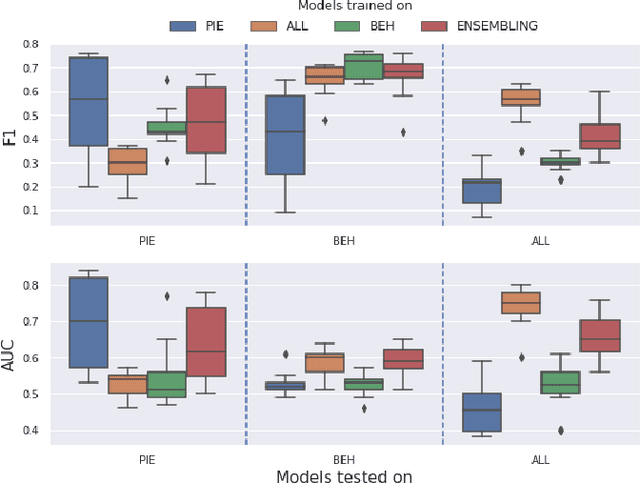
Pedestrian crossing prediction has been a topic of active research, resulting in many new algorithmic solutions. While measuring the overall progress of those solutions over time tends to be more and more established due to the new publicly available benchmark and standardized evaluation procedures, knowing how well existing predictors react to unseen data remains an unanswered question. This evaluation is imperative as serviceable crossing behavior predictors should be set to work in various scenarii without compromising pedestrian safety due to misprediction. To this end, we conduct a study based on direct cross-dataset evaluation. Our experiments show that current state-of-the-art pedestrian behavior predictors generalize poorly in cross-dataset evaluation scenarii, regardless of their robustness during a direct training-test set evaluation setting. In the light of what we observe, we argue that the future of pedestrian crossing prediction, e.g. reliable and generalizable implementations, should not be about tailoring models, trained with very little available data, and tested in a classical train-test scenario with the will to infer anything about their behavior in real life. It should be about evaluating models in a cross-dataset setting while considering their uncertainty estimates under domain shift.
THOMAS: Trajectory Heatmap Output with learned Multi-Agent Sampling
Oct 17, 2021


In this paper, we propose THOMAS, a joint multi-agent trajectory prediction framework allowing for efficient and consistent prediction of multi-agent multi-modal trajectories. We present a unified model architecture for fast and simultaneous agent future heatmap estimation leveraging hierarchical and sparse image generation. We demonstrate that heatmap output enables a higher level of control on the predicted trajectories compared to vanilla multi-modal trajectory regression, allowing to incorporate additional constraints for tighter sampling or collision-free predictions in a deterministic way. However, we also highlight that generating scene-consistent predictions goes beyond the mere generation of collision-free trajectories. We therefore propose a learnable trajectory recombination model that takes as input a set of predicted trajectories for each agent and outputs its consistent reordered recombination. We report our results on the Interaction multi-agent prediction challenge and rank $1^{st}$ on the online test leaderboard.
LENS: Localization enhanced by NeRF synthesis
Oct 13, 2021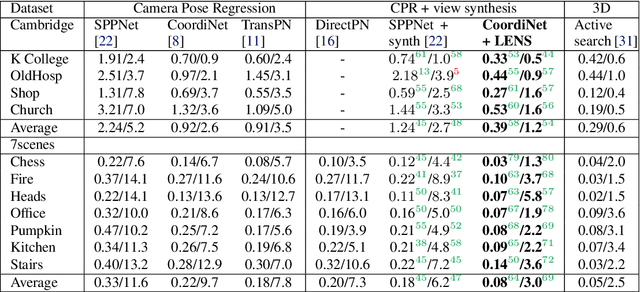
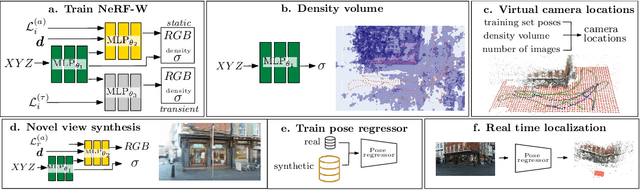

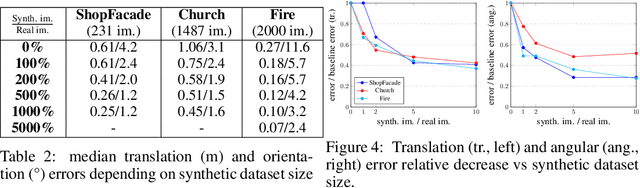
Neural Radiance Fields (NeRF) have recently demonstrated photo-realistic results for the task of novel view synthesis. In this paper, we propose to apply novel view synthesis to the robot relocalization problem: we demonstrate improvement of camera pose regression thanks to an additional synthetic dataset rendered by the NeRF class of algorithm. To avoid spawning novel views in irrelevant places we selected virtual camera locations from NeRF internal representation of the 3D geometry of the scene. We further improved localization accuracy of pose regressors using synthesized realistic and geometry consistent images as data augmentation during training. At the time of publication, our approach improved state of the art with a 60% lower error on Cambridge Landmarks and 7-scenes datasets. Hence, the resulting accuracy becomes comparable to structure-based methods, without any architecture modification or domain adaptation constraints. Since our method allows almost infinite generation of training data, we investigated limitations of camera pose regression depending on size and distribution of data used for training on public benchmarks. We concluded that pose regression accuracy is mostly bounded by relatively small and biased datasets rather than capacity of the pose regression model to solve the localization task.