 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHOMAS: Trajectory Heatmap Output with learned Multi-Agent Sampling
Paper and Code
Oct 17, 2021

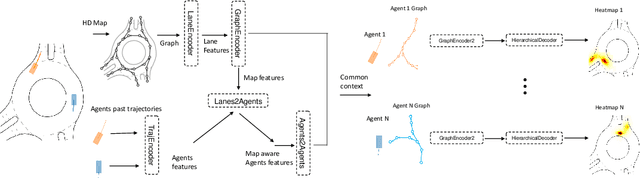

In this paper, we propose THOMAS, a joint multi-agent trajectory prediction framework allowing for efficient and consistent prediction of multi-agent multi-modal trajectories. We present a unified model architecture for fast and simultaneous agent future heatmap estimation leveraging hierarchical and sparse image generation. We demonstrate that heatmap output enables a higher level of control on the predicted trajectories compared to vanilla multi-modal trajectory regression, allowing to incorporate additional constraints for tighter sampling or collision-free predictions in a deterministic way. However, we also highlight that generating scene-consistent predictions goes beyond the mere generation of collision-free trajectories. We therefore propose a learnable trajectory recombination model that takes as input a set of predicted trajectories for each agent and outputs its consistent reordered recombination. We report our results on the Interaction multi-agent prediction challenge and rank $1^{st}$ on the online test leaderboard.