 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDK-Root: A Joint Data-and-Knowledge-Driven Framework for Root Cause Analysis of QoE Degradations in Mobile Networks
Nov 13, 2025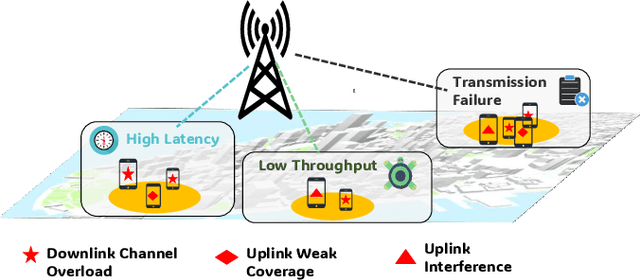
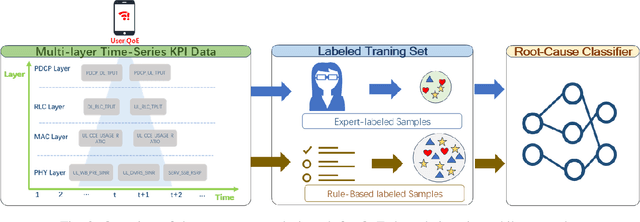
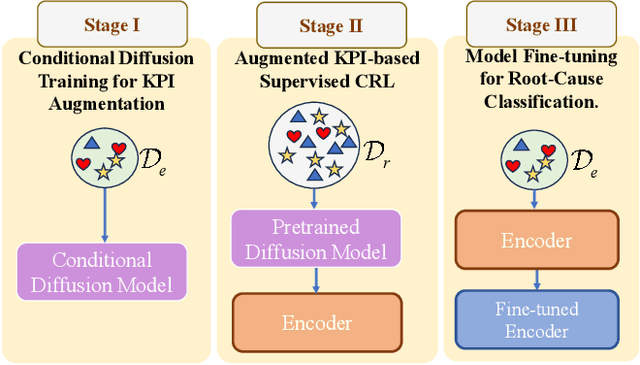
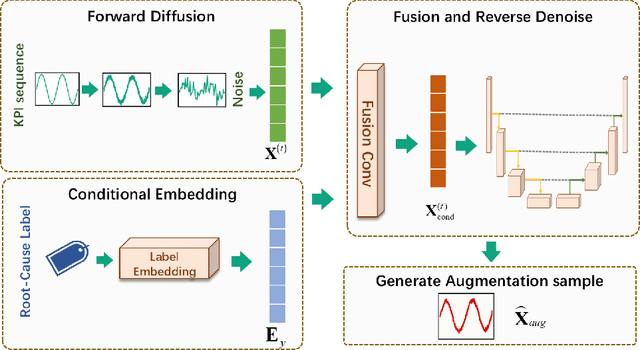
Diagnosing the root causes of Quality of Experience (QoE) degradations in operational mobile networks is challenging due to complex cross-layer interactions among kernel performance indicators (KPIs) and the scarcity of reliable expert annotations. Although rule-based heuristics can generate labels at scale, they are noisy and coarse-grained, limiting the accuracy of purely data-driven approaches. To address this, we propose DK-Root, a joint data-and-knowledge-driven framework that unifies scalable weak supervision with precise expert guidance for robust root-cause analysis. DK-Root first pretrains an encoder via contrastive representation learning using abundant rule-based labels while explicitly denoising their noise through a supervised contrastive objective. To supply task-faithful data augmentation, we introduce a class-conditional diffusion model that generates KPIs sequences preserving root-cause semantics, and by controlling reverse diffusion steps, it produces weak and strong augmentations that improve intra-class compactness and inter-class separability. Finally, the encoder and the lightweight classifier are jointly fine-tuned with scarce expert-verified labels to sharpen decision boundaries. Extensive experiments on a real-world, operator-grade dataset demonstrate state-of-the-art accuracy, with DK-Root surpassing traditional ML and recent semi-supervised time-series methods. Ablations confirm the necessity of the conditional diffusion augmentation and the pretrain-finetune design, validating both representation quality and classification gains.
Manifold Clustering with Schatten p-norm Maximization
Apr 29, 2025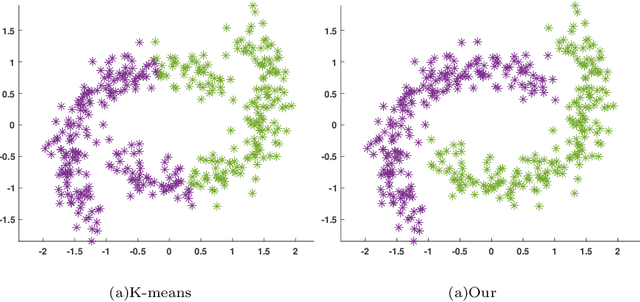
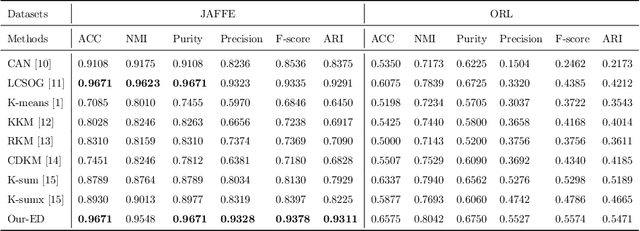
Manifold clustering, with its exceptional ability to capture complex data structures, holds a pivotal position in cluster analysis. However, existing methods often focus only on finding the optimal combination between K-means and manifold learning, and overlooking the consistency between the data structure and labels. To address this issue, we deeply explore the relationship between K-means and manifold learning, and on this basis, fuse them to develop a new clustering framework. Specifically, the algorithm uses labels to guide the manifold structure and perform clustering on it, which ensures the consistency between the data structure and labels. Furthermore, in order to naturally maintain the class balance in the clustering process, we maximize the Schatten p-norm of labels, and provide a theoretical proof to support this. Additionally, our clustering framework is designed to be flexible and compatible with many types of distance functions, which facilitates efficient processing of nonlinear separable data. The experimental results of several databases confirm the superiority of our proposed model.
HIPPO: Enhancing the Table Understanding Capability of Large Language Models through Hybrid-Modal Preference Optimization
Feb 24, 2025Tabular data contains rich structural semantics and plays a crucial role in organizing and manipulating information. To better capture these structural semantics, this paper introduces the HybrId-modal Preference oPtimizatiOn (HIPPO) model, which represents tables using both text and image, and optimizes MLLMs to effectively learn more comprehensive table information from these multiple modalities. Specifically, HIPPO samples model responses from hybrid-modal table representations and designs a modality-consistent sampling strategy to enhance response diversity and mitigate modality bias during DPO training. Experimental results on table question answering and table fact verification tasks demonstrate the effectiveness of HIPPO, achieving a 4% improvement over various table reasoning models. Further analysis reveals that HIPPO not only enhances reasoning abilities based on unimodal table representations but also facilitates the extraction of crucial and distinct semantics from different modal representations. All data and codes are available at https://github.com/NEUIR/HIPPO.
Self-Supervised Graph Embedding Clustering
Sep 24, 2024



The K-means one-step dimensionality reduction clustering method has made some progress in addressing the curse of dimensionality in clustering tasks. However, it combines the K-means clustering and dimensionality reduction processes for optimization, leading to limitations in the clustering effect due to the introduced hyperparameters and the initialization of clustering centers. Moreover, maintaining class balance during clustering remains challenging. To overcome these issues, we propose a unified framework that integrates manifold learning with K-means, resulting in the self-supervised graph embedding framework. Specifically, we establish a connection between K-means and the manifold structure, allowing us to perform K-means without explicitly defining centroids. Additionally, we use this centroid-free K-means to generate labels in low-dimensional space and subsequently utilize the label information to determine the similarity between samples. This approach ensures consistency between the manifold structure and the labels. Our model effectively achieves one-step clustering without the need for redundant balancing hyperparameters. Notably, we have discovered that maximizing the $\ell_{2,1}$-norm naturally maintains class balance during clustering, a result that we have theoretically proven. Finally, experiments on multiple datasets demonstrate that the clustering results of Our-LPP and Our-MFA exhibit excellent and reliable performance.
High-Discriminative Attribute Feature Learning for Generalized Zero-Shot Learning
Apr 07, 2024Zero-shot learning(ZSL) aims to recognize new classes without prior exposure to their samples, relying on semantic knowledge from observed classes. However, current attention-based models may overlook the transferability of visual features and the distinctiveness of attribute localization when learning regional features in images. Additionally, they often overlook shared attributes among different objects. Highly discriminative attribute features are crucial for identifying and distinguishing unseen classes. To address these issues, we propose an innovative approach called High-Discriminative Attribute Feature Learning for Generalized Zero-Shot Learning (HDAFL). HDAFL optimizes visual features by learning attribute features to obtain discriminative visual embeddings. Specifically, HDAFL utilizes multiple convolutional kernels to automatically learn discriminative regions highly correlated with attributes in images, eliminating irrelevant interference in image features. Furthermore, we introduce a Transformer-based attribute discrimination encoder to enhance the discriminative capability among attributes. Simultaneously, the method employs contrastive loss to alleviate dataset biases and enhance the transferability of visual features, facilitating better semantic transfer between seen and unseen classes. Experimental results demonstrate the effectiveness of HDAFL across three widely used datasets.
Fuzzy K-Means Clustering without Cluster Centroids
Apr 07, 2024Fuzzy K-Means clustering is a critical technique in unsupervised data analysis. However, the performance of popular Fuzzy K-Means algorithms is sensitive to the selection of initial cluster centroids and is also affected by noise when updating mean cluster centroids. To address these challenges, this paper proposes a novel Fuzzy K-Means clustering algorithm that entirely eliminates the reliance on cluster centroids, obtaining membership matrices solely through distance matrix computation. This innovation enhances flexibility in distance measurement between sample points, thus improving the algorithm's performance and robustness. The paper also establishes theoretical connections between the proposed model and popular Fuzzy K-Means clustering techniques. Experimental results on several real datasets demonstrate the effectiveness of the algorithm.
Anchor-free Clustering based on Anchor Graph Factorization
Feb 24, 2024



Anchor-based methods are a pivotal approach in handling clustering of large-scale data. However, these methods typically entail two distinct stages: selecting anchor points and constructing an anchor graph. This bifurcation, along with the initialization of anchor points, significantly influences the overall performance of the algorithm. To mitigate these issues, we introduce a novel method termed Anchor-free Clustering based on Anchor Graph Factorization (AFCAGF). AFCAGF innovates in learning the anchor graph, requiring only the computation of pairwise distances between samples. This process, achievable through straightforward optimization, circumvents the necessity for explicit selection of anchor points. More concretely, our approach enhances the Fuzzy k-means clustering algorithm (FKM), introducing a new manifold learning technique that obviates the need for initializing cluster centers. Additionally, we evolve the concept of the membership matrix between cluster centers and samples in FKM into an anchor graph encompassing multiple anchor points and samples. Employing Non-negative Matrix Factorization (NMF) on this anchor graph allows for the direct derivation of cluster labels, thereby eliminating the requirement for further post-processing steps. To solve the method proposed, we implement an alternating optimization algorithm that ensures convergence. Empirical evaluations on various real-world datasets underscore the superior efficacy of our algorithm compared to traditional approaches.
Interpretable Classification from Skin Cancer Histology Slides Using Deep Learning: A Retrospective Multicenter Study
Apr 12, 2019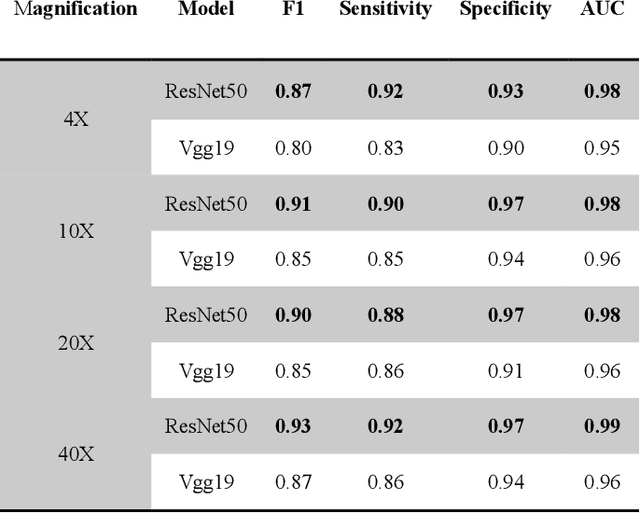
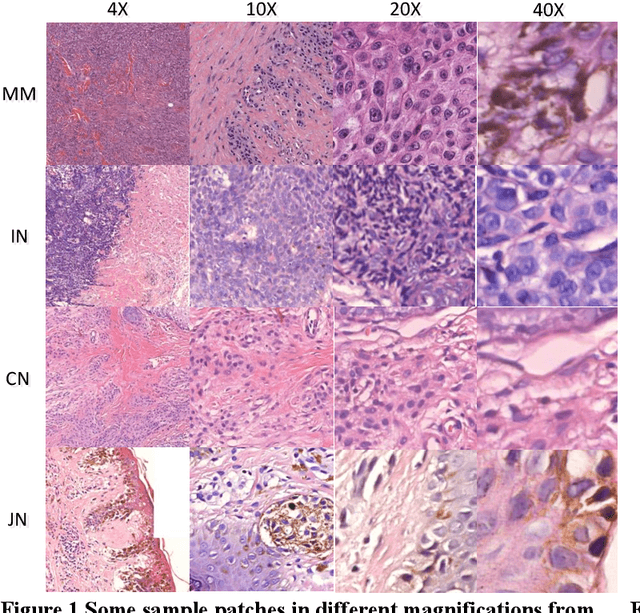
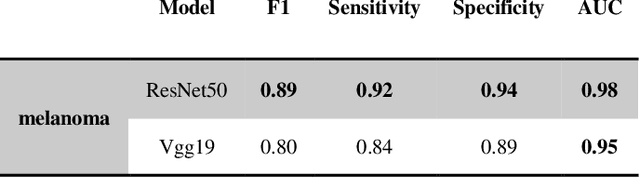
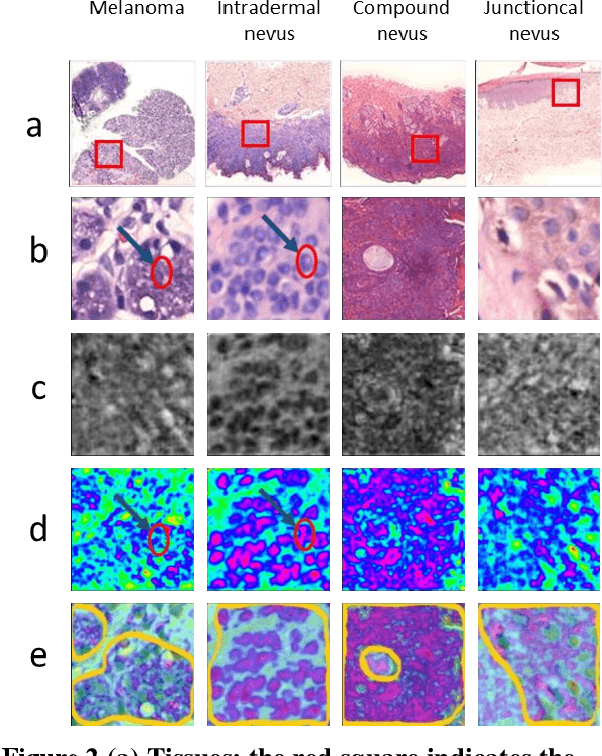
For diagnosing melanoma, hematoxylin and eosin (H&E) stained tissue slides remains the gold standard. These images contain quantitative information in different magnifications. In the present study, we investigated whether deep convolutional neural networks can extract structural features of complex tissues directly from these massive size images in a patched way. In order to face the challenge arise from morphological diversity in histopathological slides, we built a multicenter database of 2241 digital whole-slide images from 1321 patients from 2008 to 2018. We trained both ResNet50 and Vgg19 using over 9.95 million patches by transferring learning, and test performance with two kinds of critical classifications: malignant melanomas versus benign nevi in separate and mixed magnification; and distinguish among nevi in maximum magnification. The CNNs achieves superior performance across both tasks, demonstrating an AI capable of classifying skin cancer in the analysis from histopathological images. For making the classifications reasonable, the visualization of CNN representations is furthermore used to identify cells between melanoma and nevi. Regions of interest (ROI) are also located which are significantly helpful, giving pathologists more support of correctly diagnosis.
CSAL: Self-adaptive Labeling based Clustering Integrating Supervised Learning on Unlabeled Data
Feb 18, 2015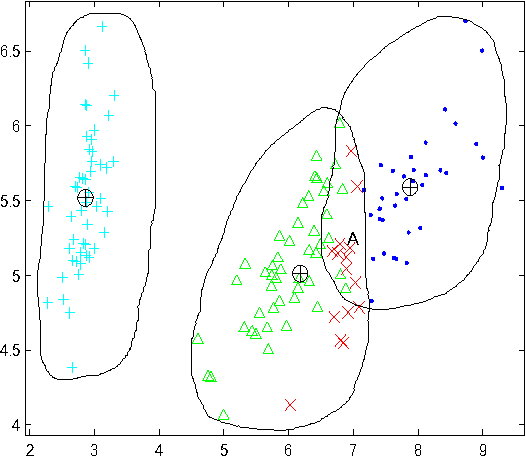

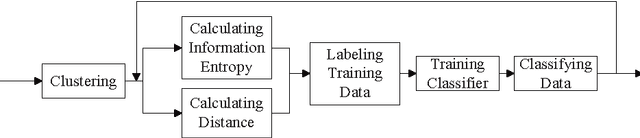
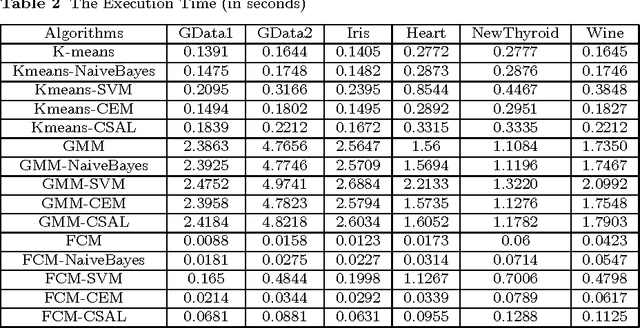
Supervised classification approaches can predict labels for unknown data because of the supervised training process. The success of classification is heavily dependent on the labeled training data. Differently, clustering is effective in revealing the aggregation property of unlabeled data, but the performance of most clustering methods is limited by the absence of labeled data. In real applications, however, it is time-consuming and sometimes impossible to obtain labeled data. The combination of clustering and classification is a promising and active approach which can largely improve the performance. In this paper, we propose an innovative and effective clustering framework based on self-adaptive labeling (CSAL) which integrates clustering and classification on unlabeled data. Clustering is first employed to partition data and a certain proportion of clustered data are selected by our proposed labeling approach for training classifiers. In order to refine the trained classifiers, an iterative process of Expectation-Maximization algorithm is devised into the proposed clustering framework CSAL. Experiments are conducted on publicly data sets to test different combinations of clustering algorithms and classification models as well as various training data labeling methods. The experimental results show that our approach along with the self-adaptive method outperforms other methods.
Coupled Item-based Matrix Factorization
Apr 08, 2014
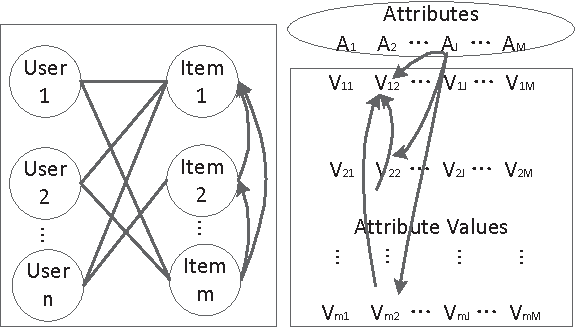
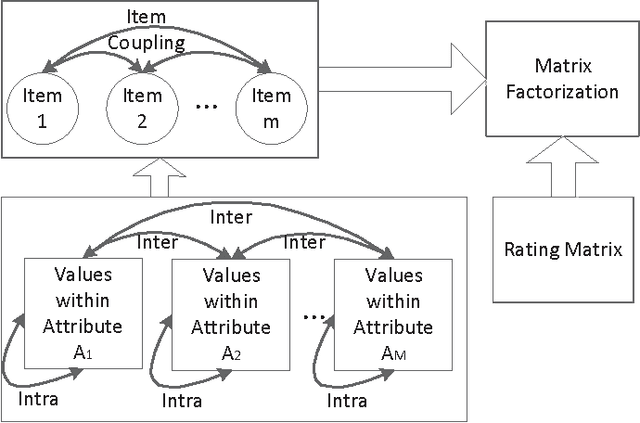
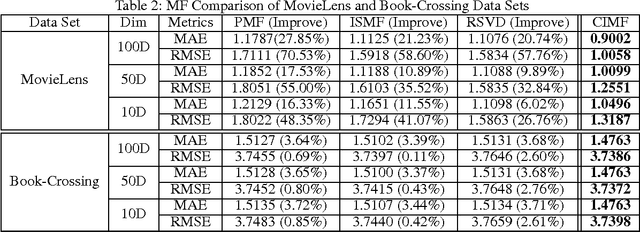
The essence of the challenges cold start and sparsity in Recommender Systems (RS) is that the extant techniques, such as Collaborative Filtering (CF) and Matrix Factorization (MF), mainly rely on the user-item rating matrix, which sometimes is not informative enough for predicting recommendations. To solve these challenges, the objective item attributes are incorporated as complementary information. However, most of the existing methods for inferring the relationships between items assume that the attributes are "independently and identically distributed (iid)", which does not always hold in reality. In fact, the attributes are more or less coupled with each other by some implicit relationships. Therefore, in this pa-per we propose an attribute-based coupled similarity measure to capture the implicit relationships between items. We then integrate the implicit item coupling into MF to form the Coupled Item-based Matrix Factorization (CIMF) model. Experimental results on two open data sets demonstrate that CIMF outperforms the benchmark methods.