 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSAL: Self-adaptive Labeling based Clustering Integrating Supervised Learning on Unlabeled Data
Paper and Code
Feb 18, 2015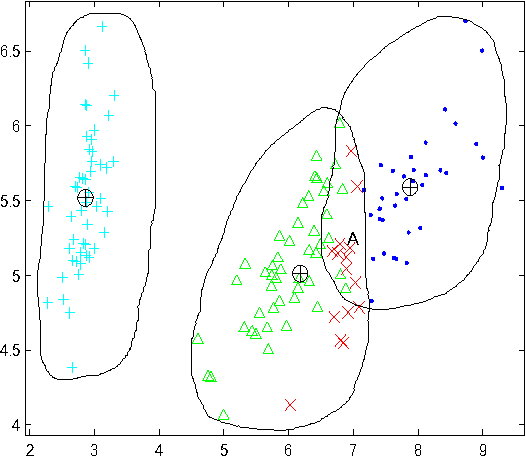

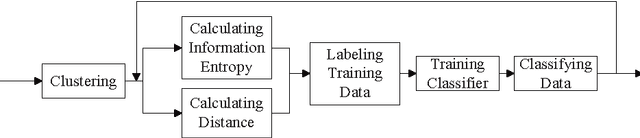
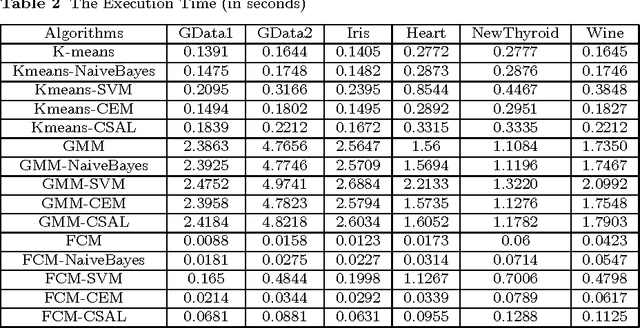
Supervised classification approaches can predict labels for unknown data because of the supervised training process. The success of classification is heavily dependent on the labeled training data. Differently, clustering is effective in revealing the aggregation property of unlabeled data, but the performance of most clustering methods is limited by the absence of labeled data. In real applications, however, it is time-consuming and sometimes impossible to obtain labeled data. The combination of clustering and classification is a promising and active approach which can largely improve the performance. In this paper, we propose an innovative and effective clustering framework based on self-adaptive labeling (CSAL) which integrates clustering and classification on unlabeled data. Clustering is first employed to partition data and a certain proportion of clustered data are selected by our proposed labeling approach for training classifiers. In order to refine the trained classifiers, an iterative process of Expectation-Maximization algorithm is devised into the proposed clustering framework CSAL. Experiments are conducted on publicly data sets to test different combinations of clustering algorithms and classification models as well as various training data labeling methods. The experimental results show that our approach along with the self-adaptive method outperforms other methods.