 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapability Self-Assessment: Teaching LLMs to Know Their Limits
May 29, 2026The ability to recognize one's own limitations and decide whether to solve a problem or delegate is fundamental for reliable intelligent systems. Yet we show that modern large language models systematically lack this ability: across diverse model families and scales, they overestimate their competence and attempt queries they cannot solve. We refer to this ability as Capability Self-Assessment (CSA) and formulate it as a policy-learning problem, aiming to improve self-assessment while preserving the model's original capabilities. Our results show that reinforcement learning teaches CSA effectively, significantly outperforming supervised fine-tuning while preserving original capabilities. In contrast, supervised fine-tuning severely degrades the capabilities the model is meant to assess. Moreover, learned self-assessment behavior generalizes well out of distribution, suggesting that CSA is a transferable model trait. Finally, CSA is practically useful: it improves local-cloud decision making at inference time and provides a signal for targeted data selection during training.
SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
May 18, 2026Long-horizon LLM agents leave traces that could become reusable experience, but raw trajectories are noisy and hard to govern. We treat Agent Skills as an experience schema that couples executable scripts, with non-executable guidance on procedures. Yet open skill ecosystems contain redundant, uneven, environment-sensitive artifacts, and indiscriminate updates can pollute future context. We present SkillsVote, a lifecycle-governance framework for Agent Skills from collection and recommendation to evolution. SkillsVote profiles a million-scale open-source corpus for environment requirements, quality, and verifiability, then synthesizes tasks for verifiable skills. Before execution, SkillsVote performs agentic library search over structured skill library to expose instructional skill context. After execution, it decomposes trajectories into skill-linked subtasks, attributes outcomes to skill use, agent exploration, environment, and result signals, and admits only successful reusable discoveries to evidence-gated updates. In our evaluation, offline evolution improves GPT-5.2 on Terminal-Bench 2.0 by up to 7.9 pp, while online evolution improves SWE-Bench Pro by up to 2.6 pp. Overall, governed external skill libraries can improve frozen agents without model updates when systems control exposure, credit, and preservation.
External Validation of Deep Learning Models for BI-RADS Breast Density Prediction from Ultrasound Images
May 06, 2026We externally validated three deep learning models (DenseNet121, ViT-B/32, and ResNet50) for predicting mammographic breast density from breast ultrasound exams on an independent cohort. The external validation set comprised 2,000 ultrasound exams, including 500 cancer cases defined by an initial negative exam (BI-RADS 1 or 2) followed by a cancer diagnosis within 6 months to 10 years, and 1,500 negative controls matched by manufacturer and study year. Performance was measured using patient-level AUROC across four density categories: A (fatty), B (scattered), C (heterogeneous), and D (extremely dense). As a downstream assessment, we also evaluated 10-year risk prediction by incorporating age and AI-derived density into the Tyrer-Cuzick model and comparing performance against a reference model using age and mammography-reported density. All three models performed best in extremely dense breasts (AUROC 0.868-0.899), with strong performance in fatty (0.814-0.838) and scattered density (0.764-0.799), and lower performance in heterogeneously dense breasts (0.699-0.729). DenseNet121 achieved the highest overall performance (micro-averaged AUROC 0.885), and performance across categories was comparable between internal and external testing. For risk modeling, age combined with AI-derived density yielded a lower AUROC than age combined with mammography-reported density (0.541 vs. 0.570; p = 0.23), with no statistically significant difference. These findings indicate that deep learning models generalize well to external data with different racial composition for breast density assessment. While performance is strongest in extremely dense breasts, heterogeneously dense remains more challenging, highlighting the need for targeted optimization.
Self-Improvement of Large Language Models: A Technical Overview and Future Outlook
Mar 26, 2026As large language models (LLMs) continue to advance, improving them solely through human supervision is becoming increasingly costly and limited in scalability. As models approach human-level capabilities in certain domains, human feedback may no longer provide sufficiently informative signals for further improvement. At the same time, the growing ability of models to make autonomous decisions and execute complex actions naturally enables abstractions in which components of the model development process can be progressively automated. Together, these challenges and opportunities have driven increasing interest in self-improvement, where models autonomously generate data, evaluate outputs, and iteratively refine their own capabilities. In this paper, we present a system-level perspective on self-improving language models and introduce a unified framework that organizes existing techniques. We conceptualize the self-improvement system as a closed-loop lifecycle, consisting of four tightly coupled processes: data acquisition, data selection, model optimization, and inference refinement, along with an autonomous evaluation layer. Within this framework, the model itself plays a central role in driving each stage: collecting or generating data, selecting informative signals, updating its parameters, and refining outputs, while the autonomous evaluation layer continuously monitors progress and guides the improvement cycle across stages. Following this lifecycle perspective, we systematically review and analyze representative methods for each component from a technical standpoint. We further discuss current limitations and outline our vision for future research toward fully self-improving LLMs.
Any Large Language Model Can Be a Reliable Judge: Debiasing with a Reasoning-based Bias Detector
May 21, 2025



LLM-as-a-Judge has emerged as a promising tool for automatically evaluating generated outputs, but its reliability is often undermined by potential biases in judgment. Existing efforts to mitigate these biases face key limitations: in-context learning-based methods fail to address rooted biases due to the evaluator's limited capacity for self-reflection, whereas fine-tuning is not applicable to all evaluator types, especially closed-source models. To address this challenge, we introduce the Reasoning-based Bias Detector (RBD), which is a plug-in module that identifies biased evaluations and generates structured reasoning to guide evaluator self-correction. Rather than modifying the evaluator itself, RBD operates externally and engages in an iterative process of bias detection and feedback-driven revision. To support its development, we design a complete pipeline consisting of biased dataset construction, supervision collection, distilled reasoning-based fine-tuning of RBD, and integration with LLM evaluators. We fine-tune four sizes of RBD models, ranging from 1.5B to 14B, and observe consistent performance improvements across all scales. Experimental results on 4 bias types--verbosity, position, bandwagon, and sentiment--evaluated using 8 LLM evaluators demonstrate RBD's strong effectiveness. For example, the RBD-8B model improves evaluation accuracy by an average of 18.5% and consistency by 10.9%, and surpasses prompting-based baselines and fine-tuned judges by 12.8% and 17.2%, respectively. These results highlight RBD's effectiveness and scalability. Additional experiments further demonstrate its strong generalization across biases and domains, as well as its efficiency.
Dynamic Noise Preference Optimization for LLM Self-Improvement via Synthetic Data
Feb 08, 2025



Although LLMs have achieved significant success, their reliance on large volumes of human-annotated data has limited their potential for further scaling. In this situation, utilizing self-generated synthetic data has become crucial for fine-tuning LLMs without extensive human annotation. However, current methods often fail to ensure consistent improvements across iterations, with performance stagnating after only minimal updates. To overcome these challenges, we introduce Dynamic Noise Preference Optimization (DNPO). DNPO employs a dynamic sample labeling mechanism to construct preference pairs for training and introduces controlled, trainable noise into the preference optimization process. Our approach effectively prevents stagnation and enables continuous improvement. In experiments with Zephyr-7B, DNPO consistently outperforms existing methods, showing an average performance boost of 2.6% across multiple benchmarks. Additionally, DNPO shows a significant improvement in model-generated data quality, with a 29.4% win-loss rate gap compared to the baseline in GPT-4 evaluations. This highlights its effectiveness in enhancing model performance through iterative refinement.
Exploring Performance Contrasts in TableQA: Step-by-Step Reasoning Boosts Bigger Language Models, Limits Smaller Language Models
Nov 24, 2024This paper proposes a detailed prompting flow, termed Table-Logic, to investigate the performance contrasts between bigger and smaller language models (LMs) utilizing step-by-step reasoning methods in the TableQA task. The method processes tasks by sequentially identifying critical columns and rows given question and table with its structure, determining necessary aggregations, calculations, or comparisons, and finally inferring the results to generate a precise prediction. By deploying this method, we observe a 7.8% accuracy improvement in bigger LMs like Llama-3-70B compared to the vanilla on HybridQA, while smaller LMs like Llama-2-7B shows an 11% performance decline. We empirically investigate the potential causes of performance contrasts by exploring the capabilities of bigger and smaller LMs from various dimensions in TableQA task. Our findings highlight the limitations of the step-by-step reasoning method in small models and provide potential insights for making improvements.
BURExtract-Llama: An LLM for Clinical Concept Extraction in Breast Ultrasound Reports
Aug 21, 2024



Breast ultrasound is essential for detecting and diagnosing abnormalities, with radiology reports summarizing key findings like lesion characteristics and malignancy assessments. Extracting this critical information is challenging due to the unstructured nature of these reports, with varied linguistic styles and inconsistent formatting. While proprietary LLMs like GPT-4 are effective, they are costly and raise privacy concerns when handling protected health information. This study presents a pipeline for developing an in-house LLM to extract clinical information from radiology reports. We first use GPT-4 to create a small labeled dataset, then fine-tune a Llama3-8B model on it. Evaluated on clinician-annotated reports, our model achieves an average F1 score of 84.6%, which is on par with GPT-4. Our findings demonstrate the feasibility of developing an in-house LLM that not only matches GPT-4's performance but also offers cost reductions and enhanced data privacy.
PFID: Privacy First Inference Delegation Framework for LLMs
Jun 18, 2024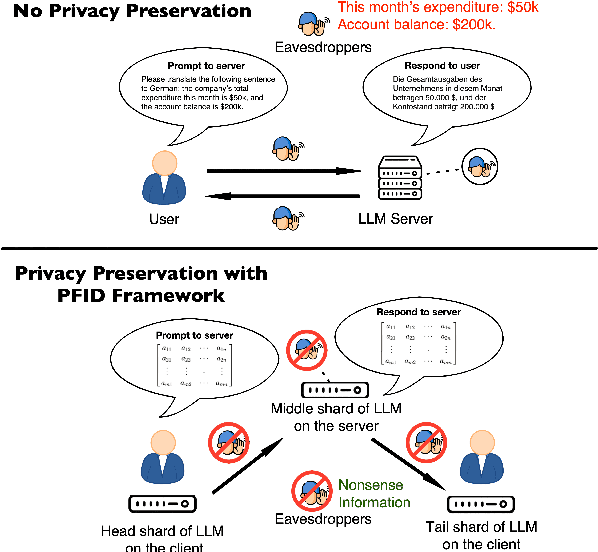
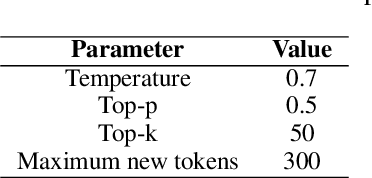

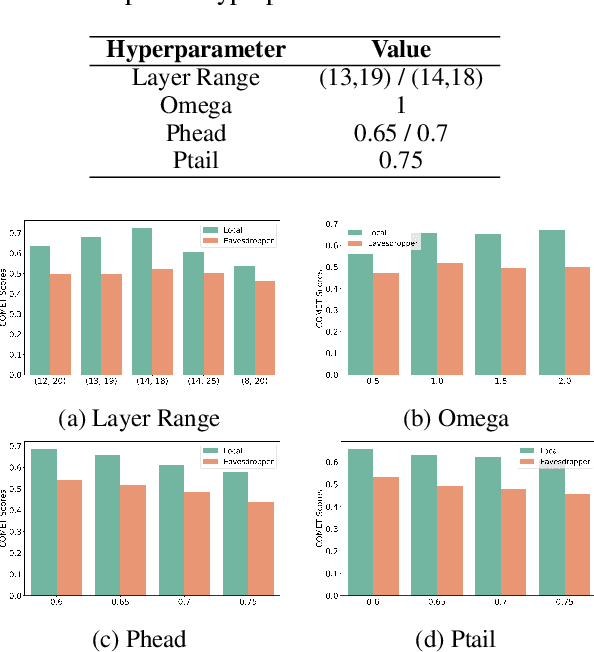
This paper introduces a novel privacy-preservation framework named PFID for LLMs that addresses critical privacy concerns by localizing user data through model sharding and singular value decomposition. When users are interacting with LLM systems, their prompts could be subject to being exposed to eavesdroppers within or outside LLM system providers who are interested in collecting users' input. In this work, we proposed a framework to camouflage user input, so as to alleviate privacy issues. Our framework proposes to place model shards on the client and the public server, we sent compressed hidden states instead of prompts to and from servers. Clients have held back information that can re-privatized the hidden states so that overall system performance is comparable to traditional LLMs services. Our framework was designed to be communication efficient, computation can be delegated to the local client so that the server's computation burden can be lightened. We conduct extensive experiments on machine translation tasks to verify our framework's performance.
Can We Trust LLMs? Mitigate Overconfidence Bias in LLMs through Knowledge Transfer
May 27, 2024



The study explores mitigating overconfidence bias in LLMs to improve their reliability. We introduce a knowledge transfer (KT) method utilizing chain of thoughts, where "big" LLMs impart knowledge to "small" LLMs via detailed, sequential reasoning paths. This method uses advanced reasoning of larger models to fine-tune smaller models, enabling them to produce more accurate predictions with calibrated confidence. Experimental evaluation using multiple-choice questions and sentiment analysis across diverse datasets demonstrated the KT method's superiority over the vanilla and question-answer pair (QA) fine-tuning methods. The most significant improvement in three key metrics, where the KT method outperformed the vanilla and QA methods by an average of 55.3% and 43.1%, respectively. These findings underscore the KT method's potential in enhancing model trustworthiness and accuracy, offering precise outputs with well-matched confidence levels across various contexts.