 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Performance Contrasts in TableQA: Step-by-Step Reasoning Boosts Bigger Language Models, Limits Smaller Language Models
Nov 24, 2024This paper proposes a detailed prompting flow, termed Table-Logic, to investigate the performance contrasts between bigger and smaller language models (LMs) utilizing step-by-step reasoning methods in the TableQA task. The method processes tasks by sequentially identifying critical columns and rows given question and table with its structure, determining necessary aggregations, calculations, or comparisons, and finally inferring the results to generate a precise prediction. By deploying this method, we observe a 7.8% accuracy improvement in bigger LMs like Llama-3-70B compared to the vanilla on HybridQA, while smaller LMs like Llama-2-7B shows an 11% performance decline. We empirically investigate the potential causes of performance contrasts by exploring the capabilities of bigger and smaller LMs from various dimensions in TableQA task. Our findings highlight the limitations of the step-by-step reasoning method in small models and provide potential insights for making improvements.
Variational Automatic Curriculum Learning for Sparse-Reward Cooperative Multi-Agent Problems
Nov 08, 2021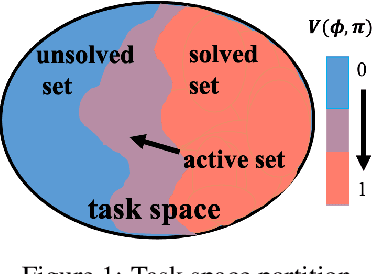

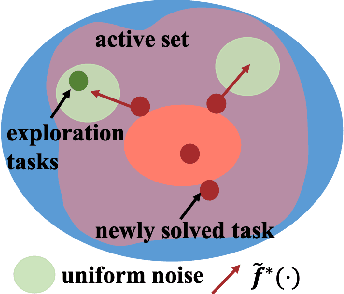

We introduce a curriculum learning algorithm, Variational Automatic Curriculum Learning (VACL), for solving challenging goal-conditioned cooperative multi-agent reinforcement learning problems. We motivate our paradigm through a variational perspective, where the learning objective can be decomposed into two terms: task learning on the current task distribution, and curriculum update to a new task distribution. Local optimization over the second term suggests that the curriculum should gradually expand the training tasks from easy to hard. Our VACL algorithm implements this variational paradigm with two practical components, task expansion and entity progression, which produces training curricula over both the task configurations as well as the number of entities in the task. Experiment results show that VACL solves a collection of sparse-reward problems with a large number of agents. Particularly, using a single desktop machine, VACL achieves 98% coverage rate with 100 agents in the simple-spread benchmark and reproduces the ramp-use behavior originally shown in OpenAI's hide-and-seek project. Our project website is at https://sites.google.com/view/vacl-neurips-2021.