 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen GNNs meet symmetry in ILPs: an orbit-based feature augmentation approach
Jan 24, 2025A common characteristic in integer linear programs (ILPs) is symmetry, allowing variables to be permuted without altering the underlying problem structure. Recently, GNNs have emerged as a promising approach for solving ILPs. However, a significant challenge arises when applying GNNs to ILPs with symmetry: classic GNN architectures struggle to differentiate between symmetric variables, which limits their predictive accuracy. In this work, we investigate the properties of permutation equivariance and invariance in GNNs, particularly in relation to the inherent symmetry of ILP formulations. We reveal that the interaction between these two factors contributes to the difficulty of distinguishing between symmetric variables. To address this challenge, we explore the potential of feature augmentation and propose several guiding principles for constructing augmented features. Building on these principles, we develop an orbit-based augmentation scheme that first groups symmetric variables and then samples augmented features for each group from a discrete uniform distribution. Empirical results demonstrate that our proposed approach significantly enhances both training efficiency and predictive performance.
An Efficient Unsupervised Framework for Convex Quadratic Programs via Deep Unrolling
Dec 02, 2024



Quadratic programs (QPs) arise in various domains such as machine learning, finance, and control. Recently, learning-enhanced primal-dual hybrid gradient (PDHG) methods have shown great potential in addressing large-scale linear programs; however, this approach has not been extended to QPs. In this work, we focus on unrolling "PDQP", a PDHG algorithm specialized for convex QPs. Specifically, we propose a neural network model called "PDQP-net" to learn optimal QP solutions. Theoretically, we demonstrate that a PDQP-net of polynomial size can align with the PDQP algorithm, returning optimal primal-dual solution pairs. We propose an unsupervised method that incorporates KKT conditions into the loss function. Unlike the standard learning-to-optimize framework that requires optimization solutions generated by solvers, our unsupervised method adjusts the network weights directly from the evaluation of the primal-dual gap. This method has two benefits over supervised learning: first, it helps generate better primal-dual gap since the primal-dual gap is in the objective function; second, it does not require solvers. We show that PDQP-net trained in this unsupervised manner can effectively approximate optimal QP solutions. Extensive numerical experiments confirm our findings, indicating that using PDQP-net predictions to warm-start PDQP can achieve up to 45% acceleration on QP instances. Moreover, it achieves 14% to 31% acceleration on out-of-distribution instances.
NeuroLifting: Neural Inference on Markov Random Fields at Scale
Nov 28, 2024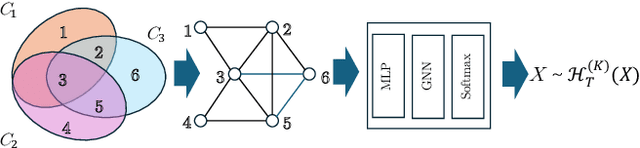


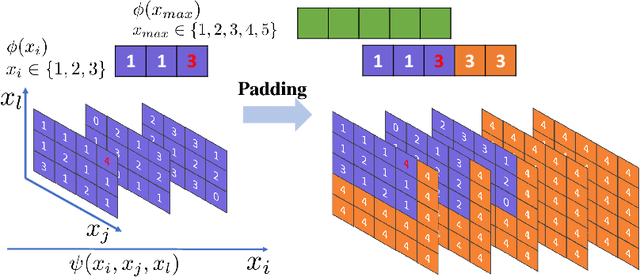
Inference in large-scale Markov Random Fields (MRFs) is a critical yet challenging task, traditionally approached through approximate methods like belief propagation and mean field, or exact methods such as the Toulbar2 solver. These strategies often fail to strike an optimal balance between efficiency and solution quality, particularly as the problem scale increases. This paper introduces NeuroLifting, a novel technique that leverages Graph Neural Networks (GNNs) to reparameterize decision variables in MRFs, facilitating the use of standard gradient descent optimization. By extending traditional lifting techniques into a non-parametric neural network framework, NeuroLifting benefits from the smooth loss landscape of neural networks, enabling efficient and parallelizable optimization. Empirical results demonstrate that, on moderate scales, NeuroLifting performs very close to the exact solver Toulbar2 in terms of solution quality, significantly surpassing existing approximate methods. Notably, on large-scale MRFs, NeuroLifting delivers superior solution quality against all baselines, as well as exhibiting linear computational complexity growth. This work presents a significant advancement in MRF inference, offering a scalable and effective solution for large-scale problems.
The Machine Learning for Combinatorial Optimization Competition (ML4CO): Results and Insights
Mar 17, 2022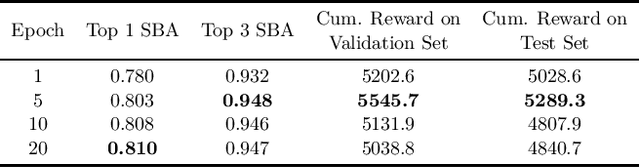

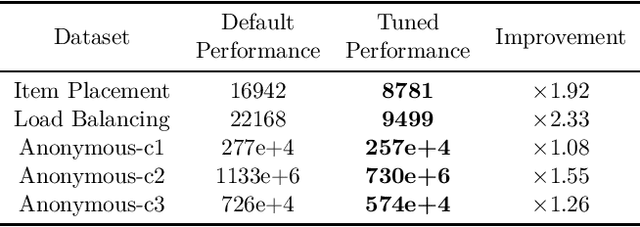
Combinatorial optimization is a well-established area in operations research and computer science. Until recently, its methods have focused on solving problem instances in isolation, ignoring that they often stem from related data distributions in practice. However, recent years have seen a surge of interest in using machine learning as a new approach for solving combinatorial problems, either directly as solvers or by enhancing exact solvers. Based on this context, the ML4CO aims at improving state-of-the-art combinatorial optimization solvers by replacing key heuristic components. The competition featured three challenging tasks: finding the best feasible solution, producing the tightest optimality certificate, and giving an appropriate solver configuration. Three realistic datasets were considered: balanced item placement, workload apportionment, and maritime inventory routing. This last dataset was kept anonymous for the contestants.
FTGAN: A Fully-trained Generative Adversarial Networks for Text to Face Generation
Apr 11, 2019
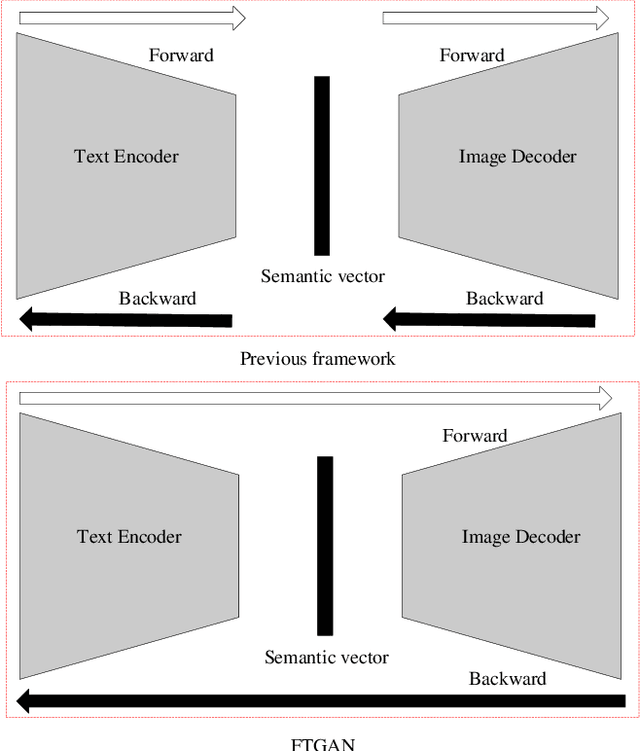
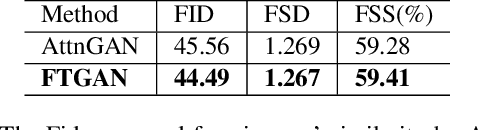
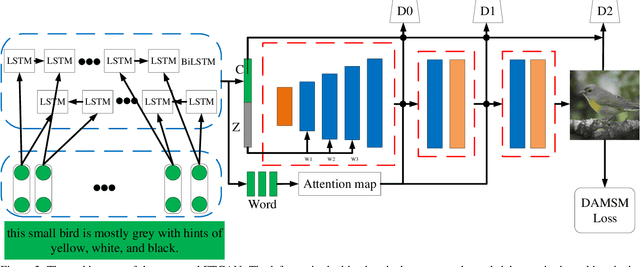
As a sub-domain of text-to-image synthesis, text-to-face generation has huge potentials in public safety domain. With lack of dataset, there are almost no related research focusing on text-to-face synthesis. In this paper, we propose a fully-trained Generative Adversarial Network (FTGAN) that trains the text encoder and image decoder at the same time for fine-grained text-to-face generation. With a novel fully-trained generative network, FTGAN can synthesize higher-quality images and urge the outputs of the FTGAN are more relevant to the input sentences. In addition, we build a dataset called SCU-Text2face for text-to-face synthesis. Through extensive experiments, the FTGAN shows its superiority in boosting both generated images' quality and similarity to the input descriptions. The proposed FTGAN outperforms the previous state of the art, boosting the best reported Inception Score to 4.63 on the CUB dataset. On SCU-text2face, the face images generated by our proposed FTGAN just based on the input descriptions is of average 59% similarity to the ground-truth, which set a baseline for text-to-face synthesis.
Ensemble-based kernel learning for a class of data assimilation problems with imperfect forward simulators
Jan 30, 2019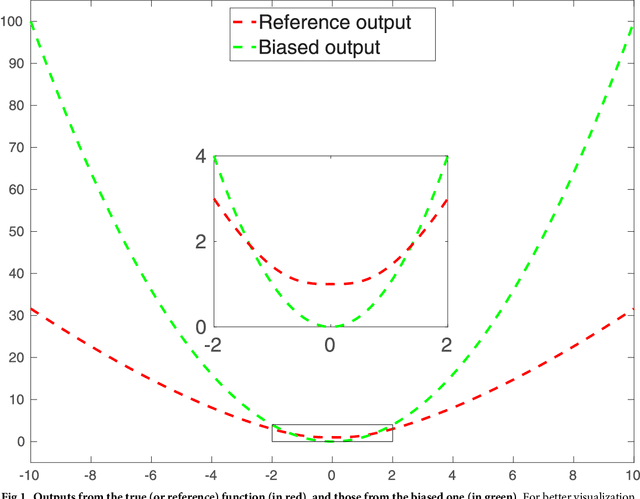
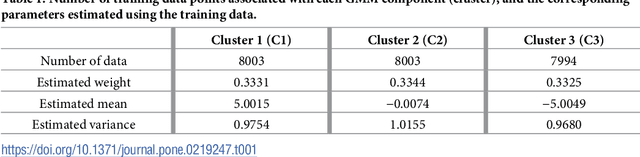
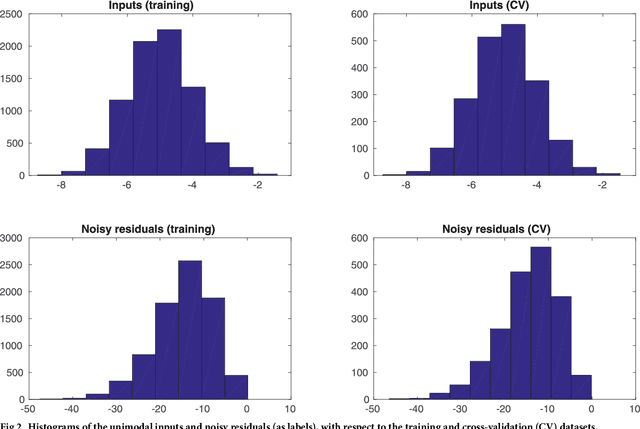

Simulator imperfection, often known as model error, is ubiquitous in practical data assimilation problems. Despite the enormous efforts dedicated to addressing this problem, properly handling simulator imperfection in data assimilation remains to be a challenging task. In this work, we propose an approach to dealing with simulator imperfection from a point of view of functional approximation that can be implemented through a certain machine learning method, such as kernel-based learning adopted in the current work. To this end, we start from considering a class of supervised learning problems, and then identify similarities between supervised learning and variational data assimilation. These similarities found the basis for us to develop an ensemble-based learning framework to tackle supervised learning problems, while achieving various advantages of ensemble-based methods over the variational ones. After establishing the ensemble-based learning framework, we proceed to investigate the integration of ensemble-based learning into an ensemble-based data assimilation framework to handle simulator imperfection. In the course of our investigations, we also develop a strategy to tackle the issue of multi-modality in supervised-learning problems, and transfer this strategy to data assimilation problems to help improve assimilation performance. For demonstration, we apply the ensemble-based learning framework and the integrated, ensemble-based data assimilation framework to a supervised learning problem and a data assimilation problem with an imperfect forward simulator, respectively. The experiment results indicate that both frameworks achieve good performance in relevant case studies, and that functional approximation through machine learning may serve as a viable way to account for simulator imperfection in data assimilation problems.