 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFTGAN: A Fully-trained Generative Adversarial Networks for Text to Face Generation
Paper and Code

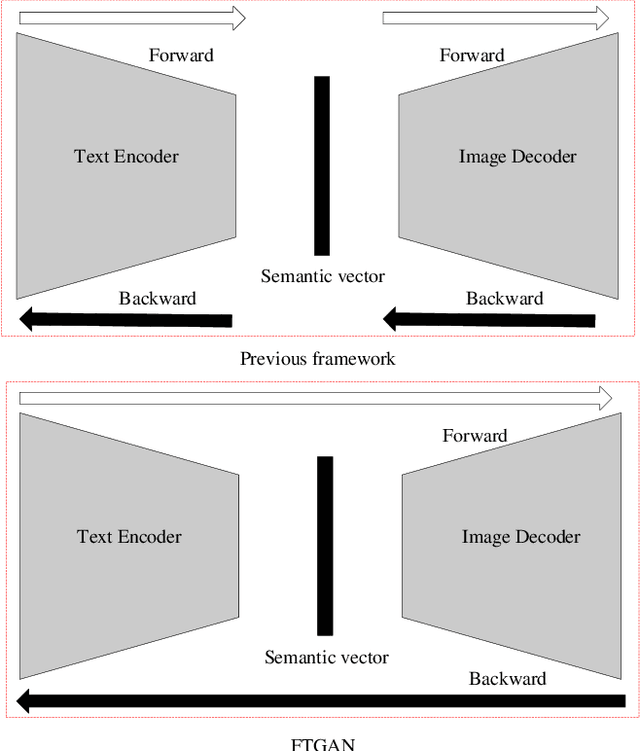
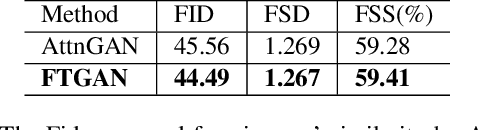
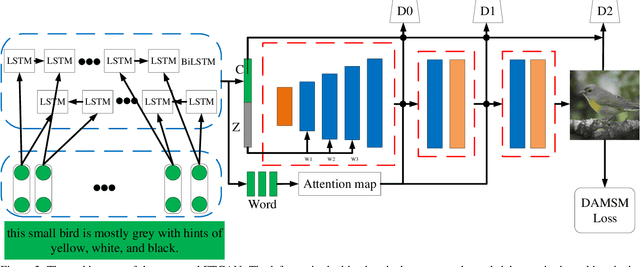
As a sub-domain of text-to-image synthesis, text-to-face generation has huge potentials in public safety domain. With lack of dataset, there are almost no related research focusing on text-to-face synthesis. In this paper, we propose a fully-trained Generative Adversarial Network (FTGAN) that trains the text encoder and image decoder at the same time for fine-grained text-to-face generation. With a novel fully-trained generative network, FTGAN can synthesize higher-quality images and urge the outputs of the FTGAN are more relevant to the input sentences. In addition, we build a dataset called SCU-Text2face for text-to-face synthesis. Through extensive experiments, the FTGAN shows its superiority in boosting both generated images' quality and similarity to the input descriptions. The proposed FTGAN outperforms the previous state of the art, boosting the best reported Inception Score to 4.63 on the CUB dataset. On SCU-text2face, the face images generated by our proposed FTGAN just based on the input descriptions is of average 59% similarity to the ground-truth, which set a baseline for text-to-face synthesis.