 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Dense Encoding for Zero-Example Video Retrieval
Paper and Code

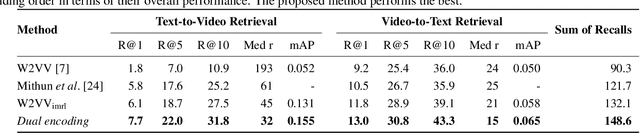
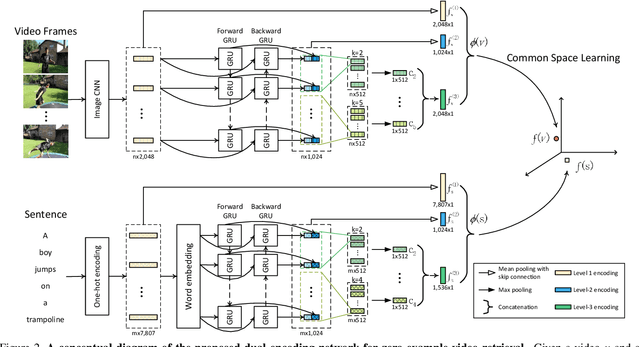
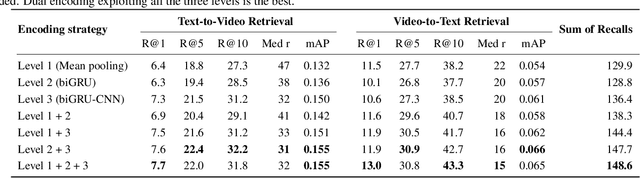
This paper attacks the challenging problem of zero-example video retrieval. In such a retrieval paradigm, an end user searches for unlabeled videos by ad-hoc queries described in natural language text with no visual example provided. The majority of existing methods are concept based, extracting relevant concepts from queries and videos and accordingly establishing associations between the two modalities. In contrast, this paper follows a novel trend of concept-free, deep learning based encoding. To that end, we propose a dual deep encoding network that works on both video and query sides. The network can be flexibly coupled with an existing common space learning module for video-text similarity computation. As experiments on three benchmarks, i.e., MSR-VTT, TRECVID 2016 and 2017 Ad-hoc Video Search show, the proposed method establishes a new state-of-the-art for zero-example video retrieval.