 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Re-Learning with Data Augmentation for Video Relevance Prediction
Paper and Code


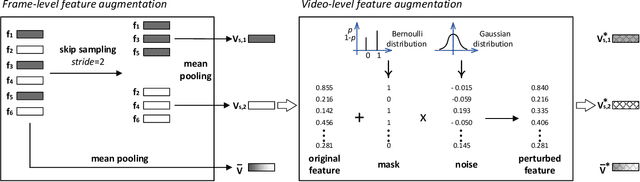
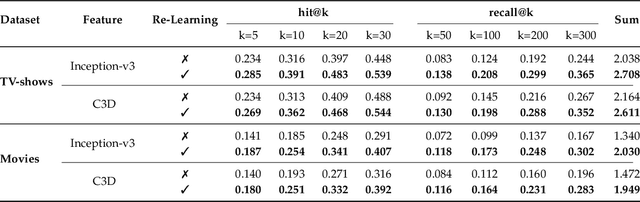
Predicting the relevance between two given videos with respect to their visual content is a key component for content-based video recommendation and retrieval. Thanks to the increasing availability of pre-trained image and video convolutional neural network models, deep visual features are widely used for video content representation. However, as how two videos are relevant is task-dependent, such off-the-shelf features are not always optimal for all tasks. Moreover, due to varied concerns including copyright, privacy and security, one might have access to only pre-computed video features rather than original videos. We propose in this paper feature re-learning for improving video relevance prediction, with no need of revisiting the original video content. In particular, re-learning is realized by projecting a given deep feature into a new space by an affine transformation. We optimize the re-learning process by a novel negative-enhanced triplet ranking loss. In order to generate more training data, we propose a new data augmentation strategy which works directly on frame-level and video-level features. Extensive experiments in the context of the Hulu Content-based Video Relevance Prediction Challenge 2018 justify the effectiveness of the proposed method and its state-of-the-art performance for content-based video relevance prediction.