 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPrune-LLM: Generalization-Aware Structured Pruning for Large Language Models
Mar 12, 2026Structured pruning is widely used to compress large language models (LLMs), yet its effectiveness depends heavily on neuron importance estimation. Most existing methods estimate neuron importance from activation statistics on a single calibration dataset, which introduces calibration bias and degrades downstream cross-task generalization. We observe that neurons exhibit heterogeneous distribution sensitivity, with distribution-robust neurons maintaining consistent rankings across datasets and distribution-sensitive neurons showing high cross-dataset ranking variance. Based on this, we identify two structural limitations in existing methods. First, ranking all neurons within a shared space causes distribution-sensitive neurons that strongly activate on calibration inputs to dominate, crowding out distribution-robust neurons critical for out-of-distribution tasks. Second, applying activation-based importance metrics uniformly can be unreliable. Distribution-sensitive neurons that infrequently activate on calibration data receive insufficient activation signal for accurate local ranking. To address these limitations, we propose GPrune-LLM, a generalization-aware structured pruning framework that explicitly accounts for neuron differences in cross-distribution behavior. We first partition neurons into behavior-consistent modules to localize ranking competition, then evaluate activation-based metric reliability per module according to distribution sensitivity and score magnitude. For modules where activation-based scoring is unreliable, we switch to an activation-independent metric. Finally, we adaptively learn module-wise sparsity. Extensive experiments across multiple downstream tasks demonstrate GPrune-LLM's consistent improvements in post-compression generalization, particularly at high sparsity, and reduced dependence on importance metric choice.
Enhancing Motion in Text-to-Video Generation with Decomposed Encoding and Conditioning
Oct 31, 2024



Despite advancements in Text-to-Video (T2V) generation, producing videos with realistic motion remains challenging. Current models often yield static or minimally dynamic outputs, failing to capture complex motions described by text. This issue stems from the internal biases in text encoding, which overlooks motions, and inadequate conditioning mechanisms in T2V generation models. To address this, we propose a novel framework called DEcomposed MOtion (DEMO), which enhances motion synthesis in T2V generation by decomposing both text encoding and conditioning into content and motion components. Our method includes a content encoder for static elements and a motion encoder for temporal dynamics, alongside separate content and motion conditioning mechanisms. Crucially, we introduce text-motion and video-motion supervision to improve the model's understanding and generation of motion. Evaluations on benchmarks such as MSR-VTT, UCF-101, WebVid-10M, EvalCrafter, and VBench demonstrate DEMO's superior ability to produce videos with enhanced motion dynamics while maintaining high visual quality. Our approach significantly advances T2V generation by integrating comprehensive motion understanding directly from textual descriptions. Project page: https://PR-Ryan.github.io/DEMO-project/
SparseGrow: Addressing Growth-Induced Forgetting in Task-Agnostic Continual Learning
Aug 20, 2024



In continual learning (CL), model growth enhances adaptability over new data, improving knowledge retention for more tasks. However, improper model growth can lead to severe degradation of previously learned knowledge, an issue we name as growth-induced forgetting (GIFt), especially in task-agnostic CL using entire grown model for inference. Existing works, despite adopting model growth and random initialization for better adaptability, often fail to recognize the presence of GIFt caused by improper model growth. This oversight limits comprehensive control of forgetting and hinders full utilization of model growth. We are the first in CL to identify this issue and conduct an in-depth study on root cause of GIFt, where layer expansion stands out among model growth strategies, widening layers without affecting model functionality. Yet, direct adoption of layer expansion presents challenges. It lacks data-driven control and initialization of expanded parameters to balance adaptability and knowledge retention. This paper presents a novel SparseGrow approach to overcome the issue of GIFt while enhancing adaptability over new data. SparseGrow employs data-driven sparse layer expansion to control efficient parameter usage during growth, reducing GIFt from excessive growth and functionality changes. It also combines sparse growth with on-data initialization at training late-stage to create partially 0-valued expansions that fit learned distribution, enhancing retention and adaptability. To further minimize forgetting, freezing is applied by calculating the sparse mask, allowing data-driven preservation of important parameters. Through experiments across datasets with various settings, cases and task numbers, we demonstrate the necessity of layer expansion and showcase the effectiveness of SparseGrow in overcoming GIFt, highlighting its adaptability and knowledge retention for incremental tasks.
FedDistill: Global Model Distillation for Local Model De-Biasing in Non-IID Federated Learning
Apr 14, 2024Federated Learning (FL) is a novel approach that allows for collaborative machine learning while preserving data privacy by leveraging models trained on decentralized devices. However, FL faces challenges due to non-uniformly distributed (non-iid) data across clients, which impacts model performance and its generalization capabilities. To tackle the non-iid issue, recent efforts have utilized the global model as a teaching mechanism for local models. However, our pilot study shows that their effectiveness is constrained by imbalanced data distribution, which induces biases in local models and leads to a 'local forgetting' phenomenon, where the ability of models to generalize degrades over time, particularly for underrepresented classes. This paper introduces FedDistill, a framework enhancing the knowledge transfer from the global model to local models, focusing on the issue of imbalanced class distribution. Specifically, FedDistill employs group distillation, segmenting classes based on their frequency in local datasets to facilitate a focused distillation process to classes with fewer samples. Additionally, FedDistill dissects the global model into a feature extractor and a classifier. This separation empowers local models with more generalized data representation capabilities and ensures more accurate classification across all classes. FedDistill mitigates the adverse effects of data imbalance, ensuring that local models do not forget underrepresented classes but instead become more adept at recognizing and classifying them accurately. Our comprehensive experiments demonstrate FedDistill's effectiveness, surpassing existing baselines in accuracy and convergence speed across several benchmark datasets.
MGAS: Multi-Granularity Architecture Search for Effective and Efficient Neural Networks
Oct 25, 2023



Differentiable architecture search (DAS) revolutionizes neural architecture search (NAS) with time-efficient automation, transitioning from discrete candidate sampling and evaluation to differentiable super-net optimization and discretization. However, existing DAS methods either only conduct coarse-grained operation-level search or manually define the remaining ratios for fine-grained kernel-level and weight-level units, which fail to simultaneously optimize model size and model performance. Furthermore, these methods compromise search quality to reduce memory consumption. To tackle these issues, we introduce multi-granularity architecture search (MGAS), a unified framework which aims to comprehensively and memory-efficiently explore the multi-granularity search space to discover both effective and efficient neural networks. Specifically, we learn discretization functions specific to each granularity level to adaptively determine the remaining ratios according to the evolving architecture. This ensures an optimal balance among units of different granularity levels for different target model sizes. Considering the memory demands, we break down the super-net optimization and discretization into multiple sub-net stages. Nevertheless, the greedy nature of this approach may introduce bias in the early stages. To compensate for the bias, we propose progressive re-evaluation to allow for re-pruning and regrowing of previous units during subsequent stages. Extensive experiments on CIFAR-10, CIFAR-100 and ImageNet demonstrate that MGAS outperforms other state-of-the-art methods in achieving a better trade-off between model performance and model size.
Revisiting Parameter Reuse to Overcome Catastrophic Forgetting in Neural Networks
Jul 29, 2022



Neural networks tend to forget previously learned knowledge when continuously learning on datasets with varying distributions, a phenomenon known as catastrophic forgetting. More significant distribution shifts among datasets lead to more forgetting. Recently, parameter-isolation-based approaches have shown great potential in overcoming forgetting with significant distribution shifts. However, they suffer from poor generalization as they fix the neural path for each dataset during training and require dataset labels during inference. In addition, they do not support backward knowledge transfer as they prioritize past data over future ones. In this paper, we propose a new adaptive learning method, named AdaptCL, that fully reuses and grows on learned parameters to overcome catastrophic forgetting and allows the positive backward transfer without requiring dataset labels. Our proposed technique adaptively grows on the same neural path by allowing optimal reuse of frozen parameters. Besides, it uses parameter-level data-driven pruning to assign equal priority to the data. We conduct extensive experiments on MNIST Variants, DomainNet, and Food Freshness Detection datasets under different intensities of distribution shifts without requiring dataset labels. Results demonstrate that our proposed method is superior to alternative baselines in minimizing forgetting and enabling positive backward knowledge transfer.
Hierarchical Reinforcement Learning with Opponent Modeling for Distributed Multi-agent Cooperation
Jun 25, 2022
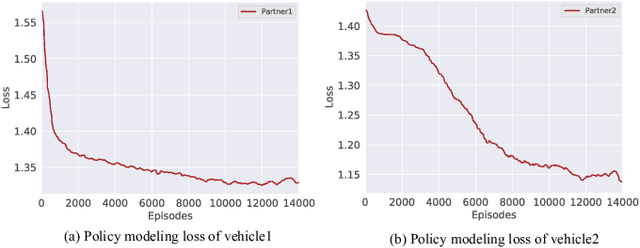
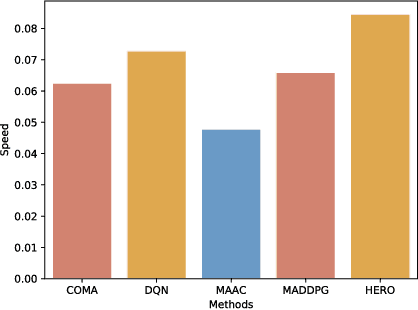

Many real-world applications can be formulated as multi-agent cooperation problems, such as network packet routing and coordination of autonomous vehicles. The emergence of deep reinforcement learning (DRL) provides a promising approach for multi-agent cooperation through the interaction of the agents and environments. However, traditional DRL solutions suffer from the high dimensions of multiple agents with continuous action space during policy search. Besides, the dynamicity of agents' policies makes the training non-stationary. To tackle the issues, we propose a hierarchical reinforcement learning approach with high-level decision-making and low-level individual control for efficient policy search. In particular, the cooperation of multiple agents can be learned in high-level discrete action space efficiently. At the same time, the low-level individual control can be reduced to single-agent reinforcement learning. In addition to hierarchical reinforcement learning, we propose an opponent modeling network to model other agents' policies during the learning process. In contrast to end-to-end DRL approaches, our approach reduces the learning complexity by decomposing the overall task into sub-tasks in a hierarchical way. To evaluate the efficiency of our approach, we conduct a real-world case study in the cooperative lane change scenario. Both simulation and real-world experiments show the superiority of our approach in the collision rate and convergence speed.
From Multi-agent to Multi-robot: A Scalable Training and Evaluation Platform for Multi-robot Reinforcement Learning
Jun 20, 2022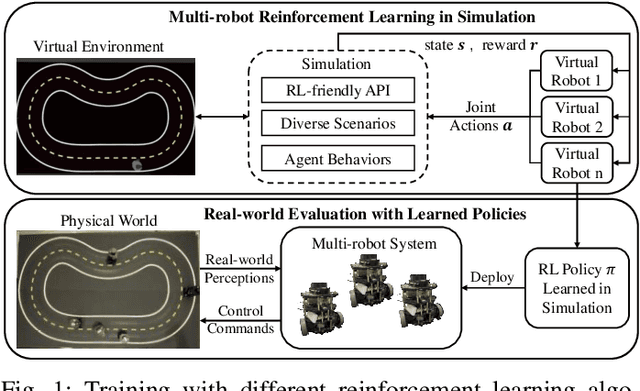

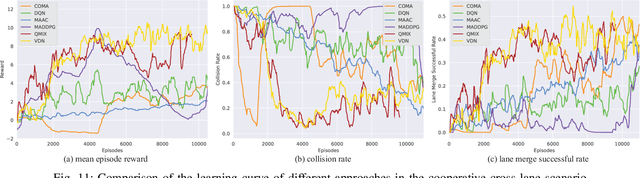

Multi-agent reinforcement learning (MARL) has been gaining extensive attention from academia and industries in the past few decades. One of the fundamental problems in MARL is how to evaluate different approaches comprehensively. Most existing MARL methods are evaluated in either video games or simplistic simulated scenarios. It remains unknown how these methods perform in real-world scenarios, especially multi-robot systems. This paper introduces a scalable emulation platform for multi-robot reinforcement learning (MRRL) called SMART to meet this need. Precisely, SMART consists of two components: 1) a simulation environment that provides a variety of complex interaction scenarios for training and 2) a real-world multi-robot system for realistic performance evaluation. Besides, SMART offers agent-environment APIs that are plug-and-play for algorithm implementation. To illustrate the practicality of our platform, we conduct a case study on the cooperative driving lane change scenario. Building off the case study, we summarize several unique challenges of MRRL, which are rarely considered previously. Finally, we open-source the simulation environments, associated benchmark tasks, and state-of-the-art baselines to encourage and empower MRRL research.
Time Series Clustering for Human Behavior Pattern Mining
Oct 25, 2021

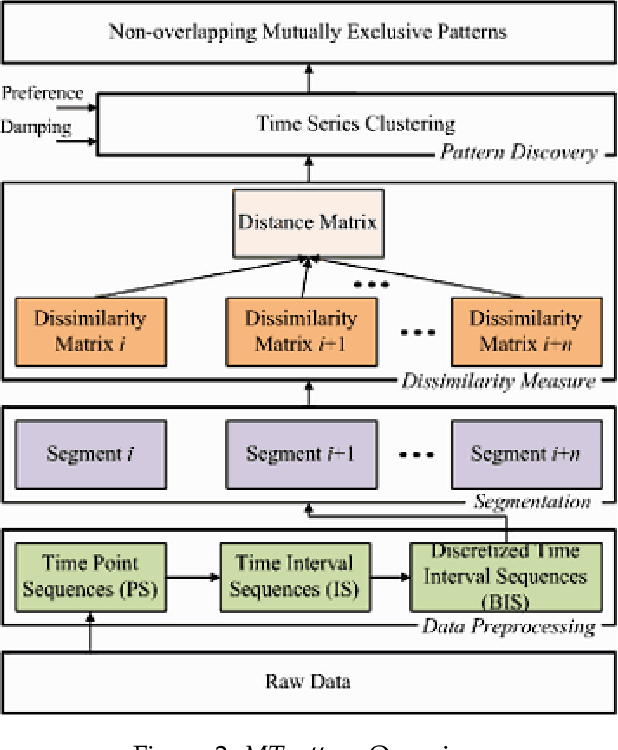

Human behavior modeling deals with learning and understanding behavior patterns inherent in humans' daily routines. Existing pattern mining techniques either assume human dynamics is strictly periodic, or require the number of modes as input, or do not consider uncertainty in the sensor data. To handle these issues, in this paper, we propose a novel clustering approach for modeling human behavior (named, MTpattern) from time-series data. For mining frequent human behavior patterns effectively, we utilize a three-stage pipeline: (1) represent time series data into a sequence of regularly sampled equal-sized unit time intervals for better analysis, (2) a new distance measure scheme is proposed to cluster similar sequences which can handle temporal variation and uncertainty in the data, and (3) exploit an exemplar-based clustering mechanism and fine-tune its parameters to output minimum number of clusters with given permissible distance constraints and without knowing the number of modes present in the data. Then, the average of all sequences in a cluster is considered as a human behavior pattern. Empirical studies on two real-world datasets and a simulated dataset demonstrate the effectiveness of MTpattern with respect to internal and external measures of clustering.
Generative Adversarial Networks (GANs): Challenges, Solutions, and Future Directions
May 07, 2020

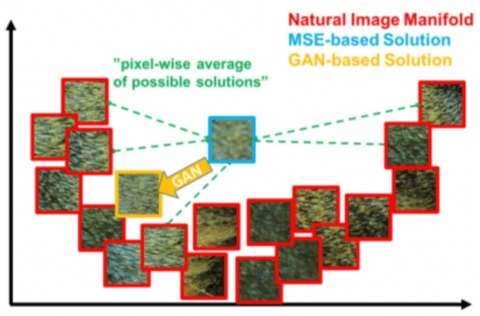

Generative Adversarial Networks (GANs) is a novel class of deep generative models which has recently gained significant attention. GANs learns complex and high-dimensional distributions implicitly over images, audio, and data. However, there exists major challenges in training of GANs, i.e., mode collapse, non-convergence and instability, due to inappropriate design of network architecture, use of objective function and selection of optimization algorithm. Recently, to address these challenges, several solutions for better design and optimization of GANs have been investigated based on techniques of re-engineered network architectures, new objective functions and alternative optimization algorithms. To the best of our knowledge, there is no existing survey that has particularly focused on broad and systematic developments of these solutions. In this study, we perform a comprehensive survey of the advancements in GANs design and optimization solutions proposed to handle GANs challenges. We first identify key research issues within each design and optimization technique and then propose a new taxonomy to structure solutions by key research issues. In accordance with the taxonomy, we provide a detailed discussion on different GANs variants proposed within each solution and their relationships. Finally, based on the insights gained, we present the promising research directions in this rapidly growing field.