 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIRAL: Symbolic LLM Planning via Grounded and Reflective Search
Dec 29, 2025Large Language Models (LLMs) often falter at complex planning tasks that require exploration and self-correction, as their linear reasoning process struggles to recover from early mistakes. While search algorithms like Monte Carlo Tree Search (MCTS) can explore alternatives, they are often ineffective when guided by sparse rewards and fail to leverage the rich semantic capabilities of LLMs. We introduce SPIRAL (Symbolic LLM Planning via Grounded and Reflective Search), a novel framework that embeds a cognitive architecture of three specialized LLM agents into an MCTS loop. SPIRAL's key contribution is its integrated planning pipeline where a Planner proposes creative next steps, a Simulator grounds the search by predicting realistic outcomes, and a Critic provides dense reward signals through reflection. This synergy transforms MCTS from a brute-force search into a guided, self-correcting reasoning process. On the DailyLifeAPIs and HuggingFace datasets, SPIRAL consistently outperforms the default Chain-of-Thought planning method and other state-of-the-art agents. More importantly, it substantially surpasses other state-of-the-art agents; for example, SPIRAL achieves 83.6% overall accuracy on DailyLifeAPIs, an improvement of over 16 percentage points against the next-best search framework, while also demonstrating superior token efficiency. Our work demonstrates that structuring LLM reasoning as a guided, reflective, and grounded search process yields more robust and efficient autonomous planners. The source code, full appendices, and all experimental data are available for reproducibility at the official project repository.
Fine-Tuned Thoughts: Leveraging Chain-of-Thought Reasoning for Industrial Asset Health Monitoring
Oct 21, 2025Small Language Models (SLMs) are becoming increasingly popular in specialized fields, such as industrial applications, due to their efficiency, lower computational requirements, and ability to be fine-tuned for domain-specific tasks, enabling accurate and cost-effective solutions. However, performing complex reasoning using SLMs in specialized fields such as Industry 4.0 remains challenging. In this paper, we propose a knowledge distillation framework for industrial asset health, which transfers reasoning capabilities via Chain-of-Thought (CoT) distillation from Large Language Models (LLMs) to smaller, more efficient models (SLMs). We discuss the advantages and the process of distilling LLMs using multi-choice question answering (MCQA) prompts to enhance reasoning and refine decision-making. We also perform in-context learning to verify the quality of the generated knowledge and benchmark the performance of fine-tuned SLMs with generated knowledge against widely used LLMs. The results show that the fine-tuned SLMs with CoT reasoning outperform the base models by a significant margin, narrowing the gap to their LLM counterparts. Our code is open-sourced at: https://github.com/IBM/FailureSensorIQ.
Towards Building General Purpose Embedding Models for Industry 4.0 Agents
Jun 14, 2025In this work we focus on improving language models' understanding for asset maintenance to guide the engineer's decisions and minimize asset downtime. Given a set of tasks expressed in natural language for Industry 4.0 domain, each associated with queries related to a specific asset, we want to recommend relevant items and generalize to queries of similar assets. A task may involve identifying relevant sensors given a query about an asset's failure mode. Our approach begins with gathering a qualitative, expert-vetted knowledge base to construct nine asset-specific task datasets. To create more contextually informed embeddings, we augment the input tasks using Large Language Models (LLMs), providing concise descriptions of the entities involved in the queries. This embedding model is then integrated with a Reasoning and Acting agent (ReAct), which serves as a powerful tool for answering complex user queries that require multi-step reasoning, planning, and knowledge inference. Through ablation studies, we demonstrate that: (a) LLM query augmentation improves the quality of embeddings, (b) Contrastive loss and other methods that avoid in-batch negatives are superior for datasets with queries related to many items, and (c) It is crucial to balance positive and negative in-batch samples. After training and testing on our dataset, we observe a substantial improvement: HIT@1 increases by +54.2%, MAP@100 by +50.1%, and NDCG@10 by +54.7%, averaged across all tasks and models. Additionally, we empirically demonstrate the model's planning and tool invocation capabilities when answering complex questions related to industrial asset maintenance, showcasing its effectiveness in supporting Subject Matter Experts (SMEs) in their day-to-day operations.
Chat-of-Thought: Collaborative Multi-Agent System for Generating Domain Specific Information
Jun 11, 2025This paper presents a novel multi-agent system called Chat-of-Thought, designed to facilitate the generation of Failure Modes and Effects Analysis (FMEA) documents for industrial assets. Chat-of-Thought employs multiple collaborative Large Language Model (LLM)-based agents with specific roles, leveraging advanced AI techniques and dynamic task routing to optimize the generation and validation of FMEA tables. A key innovation in this system is the introduction of a Chat of Thought, where dynamic, multi-persona-driven discussions enable iterative refinement of content. This research explores the application domain of industrial equipment monitoring, highlights key challenges, and demonstrates the potential of Chat-of-Thought in addressing these challenges through interactive, template-driven workflows and context-aware agent collaboration.
AssetOpsBench: Benchmarking AI Agents for Task Automation in Industrial Asset Operations and Maintenance
Jun 04, 2025AI for Industrial Asset Lifecycle Management aims to automate complex operational workflows -- such as condition monitoring, maintenance planning, and intervention scheduling -- to reduce human workload and minimize system downtime. Traditional AI/ML approaches have primarily tackled these problems in isolation, solving narrow tasks within the broader operational pipeline. In contrast, the emergence of AI agents and large language models (LLMs) introduces a next-generation opportunity: enabling end-to-end automation across the entire asset lifecycle. This paper envisions a future where AI agents autonomously manage tasks that previously required distinct expertise and manual coordination. To this end, we introduce AssetOpsBench -- a unified framework and environment designed to guide the development, orchestration, and evaluation of domain-specific agents tailored for Industry 4.0 applications. We outline the key requirements for such holistic systems and provide actionable insights into building agents that integrate perception, reasoning, and control for real-world industrial operations. The software is available at https://github.com/IBM/AssetOpsBench.
LLM Assisted Anomaly Detection Service for Site Reliability Engineers: Enhancing Cloud Infrastructure Resilience
Jan 28, 2025This paper introduces a scalable Anomaly Detection Service with a generalizable API tailored for industrial time-series data, designed to assist Site Reliability Engineers (SREs) in managing cloud infrastructure. The service enables efficient anomaly detection in complex data streams, supporting proactive identification and resolution of issues. Furthermore, it presents an innovative approach to anomaly modeling in cloud infrastructure by utilizing Large Language Models (LLMs) to understand key components, their failure modes, and behaviors. A suite of algorithms for detecting anomalies is offered in univariate and multivariate time series data, including regression-based, mixture-model-based, and semi-supervised approaches. We provide insights into the usage patterns of the service, with over 500 users and 200,000 API calls in a year. The service has been successfully applied in various industrial settings, including IoT-based AI applications. We have also evaluated our system on public anomaly benchmarks to show its effectiveness. By leveraging it, SREs can proactively identify potential issues before they escalate, reducing downtime and improving response times to incidents, ultimately enhancing the overall customer experience. We plan to extend the system to include time series foundation models, enabling zero-shot anomaly detection capabilities.
Towards Automated Solution Recipe Generation for Industrial Asset Management with LLM
Jul 26, 2024



This study introduces a novel approach to Industrial Asset Management (IAM) by incorporating Conditional-Based Management (CBM) principles with the latest advancements in Large Language Models (LLMs). Our research introduces an automated model-building process, traditionally reliant on intensive collaboration between data scientists and domain experts. We present two primary innovations: a taxonomy-guided prompting generation that facilitates the automatic creation of AI solution recipes and a set of LLM pipelines designed to produce a solution recipe containing a set of artifacts composed of documents, sample data, and models for IAM. These pipelines, guided by standardized principles, enable the generation of initial solution templates for heterogeneous asset classes without direct human input, reducing reliance on extensive domain knowledge and enhancing automation. We evaluate our methodology by assessing asset health and sustainability across a spectrum of ten asset classes. Our findings illustrate the potential of LLMs and taxonomy-based LLM prompting pipelines in transforming asset management, offering a blueprint for subsequent research and development initiatives to be integrated into a rapid client solution.
Event-centric Query Suggestion for Online News
Jan 12, 2022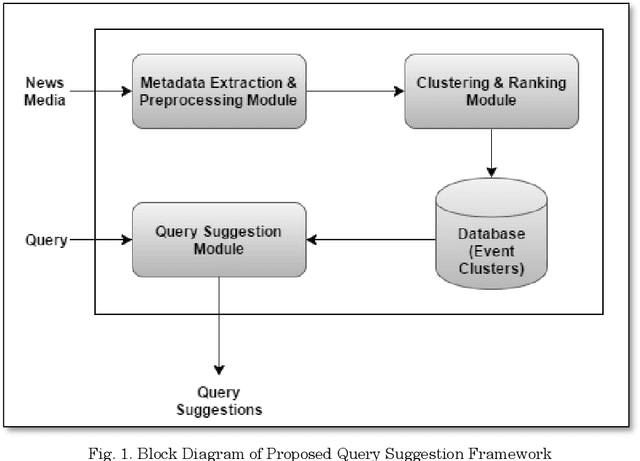
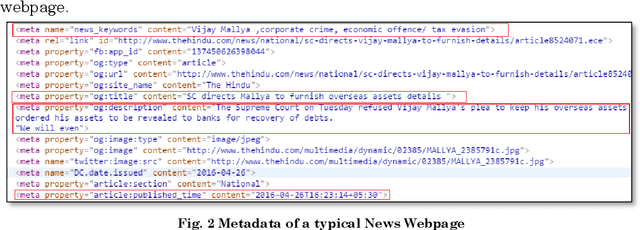
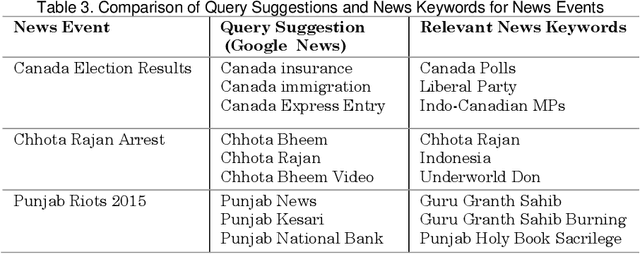
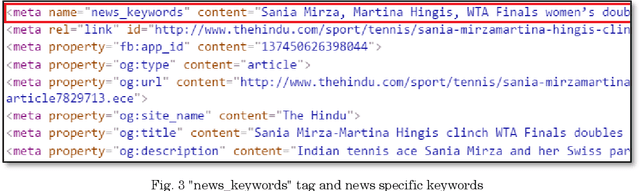
Query suggestion refers to the task of suggesting relevant and related queries to a search engine user to help in query formulation process and to expedite information retrieval with minimum amount of effort. It is highly useful in situations where the search requirements are not well understood and hence it has been widely adopted by search engines to guide users' search activity. For news websites, user queries have a time sensitive nature inherent in them. When some new event happens, there is a sudden burst in queries related to that event and such queries are sustained over a period of time before fading away with that event. In addition to this temporal aspect of search queries fired at news websites, they have an addition distinct quality, i.e., they are intended to get event related information majority of the times. Existing work on generating query suggestions involves analyzing query logs to suggest queries which are relevant and related to the search intent of the user. But in case of news websites, when there is a sudden burst in information related to a particular event, there are not enough search queries fired by other users which leads to lack of click data, and hence giving query suggestions related to some old event or even some irrelevant suggestions altogether. Another problem with query logs in the context of online news is that, they mostly contain queries related to popular events and hence fail to capture less popular events or events which got overshadowed by some other more sensational event. We propose a novel approach to generate event-centric query suggestions using metadata of news articles published by news media. We compared our proposed framework with existing state of the art query suggestion mechanisms provided by Google News, Bing News, Google Search and Bing Search on various parameters.
Time Series Clustering for Human Behavior Pattern Mining
Oct 25, 2021

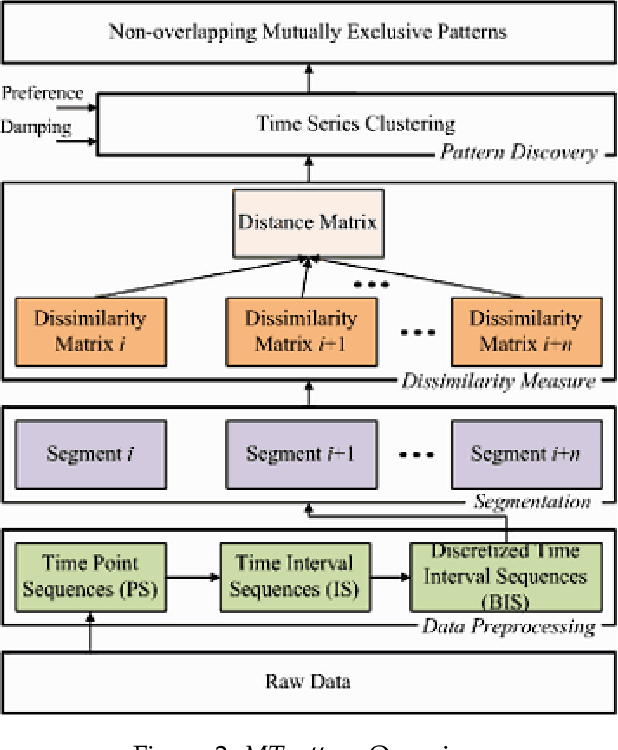

Human behavior modeling deals with learning and understanding behavior patterns inherent in humans' daily routines. Existing pattern mining techniques either assume human dynamics is strictly periodic, or require the number of modes as input, or do not consider uncertainty in the sensor data. To handle these issues, in this paper, we propose a novel clustering approach for modeling human behavior (named, MTpattern) from time-series data. For mining frequent human behavior patterns effectively, we utilize a three-stage pipeline: (1) represent time series data into a sequence of regularly sampled equal-sized unit time intervals for better analysis, (2) a new distance measure scheme is proposed to cluster similar sequences which can handle temporal variation and uncertainty in the data, and (3) exploit an exemplar-based clustering mechanism and fine-tune its parameters to output minimum number of clusters with given permissible distance constraints and without knowing the number of modes present in the data. Then, the average of all sequences in a cluster is considered as a human behavior pattern. Empirical studies on two real-world datasets and a simulated dataset demonstrate the effectiveness of MTpattern with respect to internal and external measures of clustering.
AutoAI-TS: AutoAI for Time Series Forecasting
Mar 08, 2021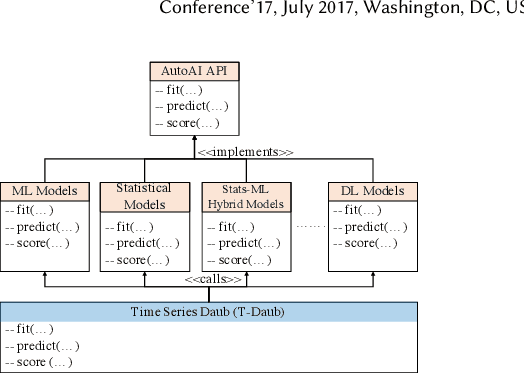
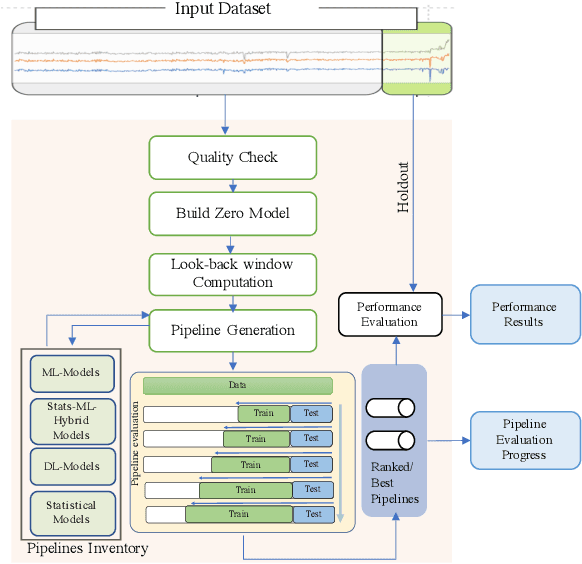
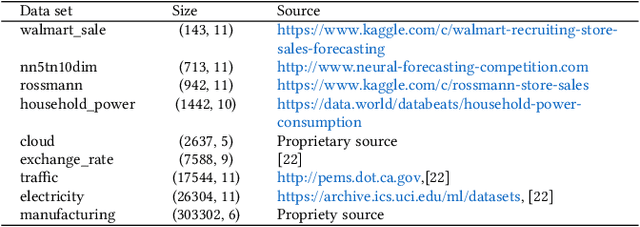
A large number of time series forecasting models including traditional statistical models, machine learning models and more recently deep learning have been proposed in the literature. However, choosing the right model along with good parameter values that performs well on a given data is still challenging. Automatically providing a good set of models to users for a given dataset saves both time and effort from using trial-and-error approaches with a wide variety of available models along with parameter optimization. We present AutoAI for Time Series Forecasting (AutoAI-TS) that provides users with a zero configuration (zero-conf ) system to efficiently train, optimize and choose best forecasting model among various classes of models for the given dataset. With its flexible zero-conf design, AutoAI-TS automatically performs all the data preparation, model creation, parameter optimization, training and model selection for users and provides a trained model that is ready to use. For given data, AutoAI-TS utilizes a wide variety of models including classical statistical models, Machine Learning (ML) models, statistical-ML hybrid models and deep learning models along with various transformations to create forecasting pipelines. It then evaluates and ranks pipelines using the proposed T-Daub mechanism to choose the best pipeline. The paper describe in detail all the technical aspects of AutoAI-TS along with extensive benchmarking on a variety of real world data sets for various use-cases. Benchmark results show that AutoAI-TS, with no manual configuration from the user, automatically trains and selects pipelines that on average outperform existing state-of-the-art time series forecasting toolkits.