 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Control Center for Data Product Optimization
Mar 10, 2026Data products enable end users to gain greater insights about their data by providing supporting assets, such as example question-SQL pairs which can be answered using the data or views over the database tables. However, producing useful data products is challenging, and typically requires domain experts to hand-craft supporting assets. We propose a system that automates data product improvement through specialized AI agents operating in a continuous optimization loop. By surfacing questions, monitoring multi-dimensional quality metrics, and supporting human-in-the-loop controls, it transforms data into observable and refinable assets that balance automation with trust and oversight.
Toward Theoretical Guidance for Two Common Questions in Practical Cross-Validation based Hyperparameter Selection
Jan 12, 2023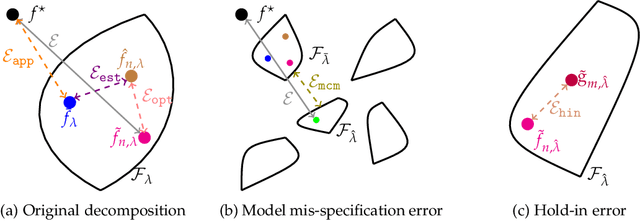

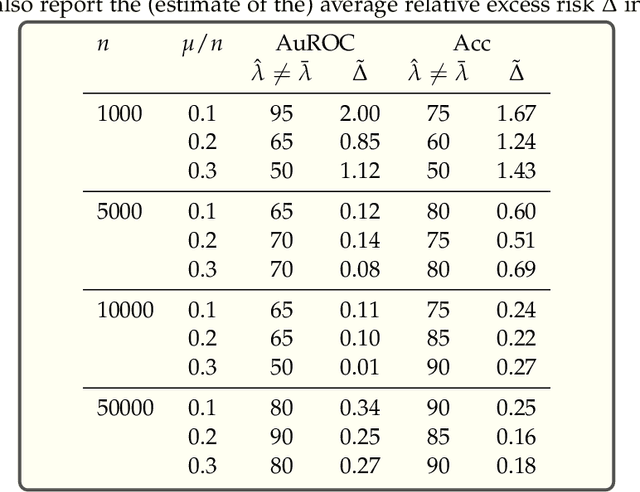
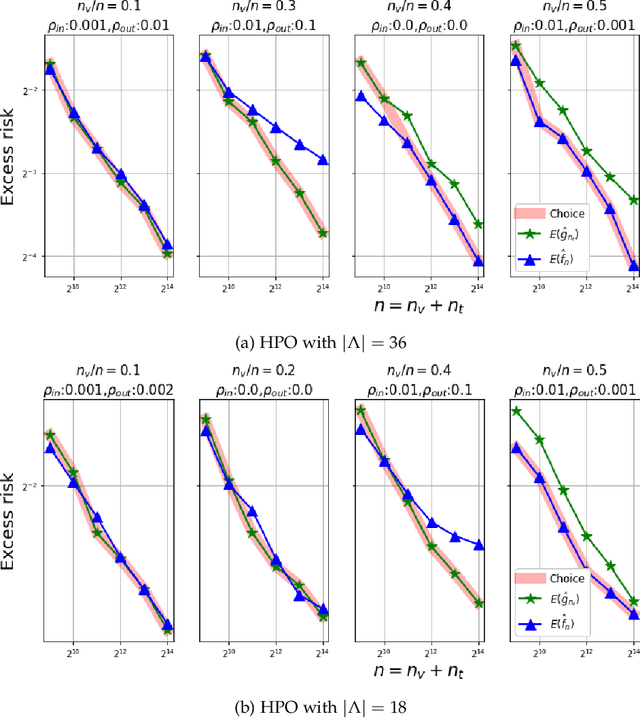
We show, to our knowledge, the first theoretical treatments of two common questions in cross-validation based hyperparameter selection: (1) After selecting the best hyperparameter using a held-out set, we train the final model using {\em all} of the training data -- since this may or may not improve future generalization error, should one do this? (2) During optimization such as via SGD (stochastic gradient descent), we must set the optimization tolerance $\rho$ -- since it trades off predictive accuracy with computation cost, how should one set it? Toward these problems, we introduce the {\em hold-in risk} (the error due to not using the whole training data), and the {\em model class mis-specification risk} (the error due to having chosen the wrong model class) in a theoretical view which is simple, general, and suggests heuristics that can be used when faced with a dataset instance. In proof-of-concept studies in synthetic data where theoretical quantities can be controlled, we show that these heuristics can, respectively, (1) always perform at least as well as always performing retraining or never performing retraining, (2) either improve performance or reduce computational overhead by $2\times$ with no loss in predictive performance.
AutoAI-TS: AutoAI for Time Series Forecasting
Mar 08, 2021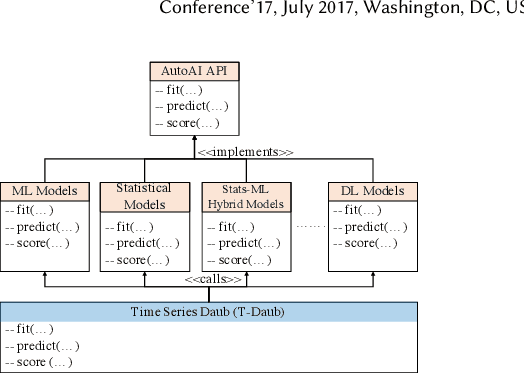
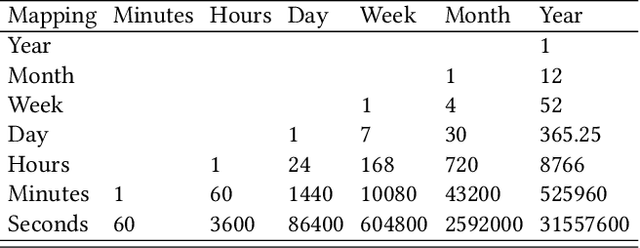
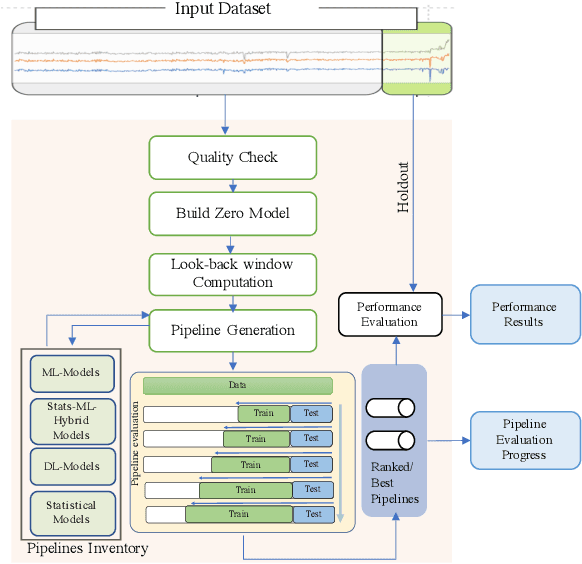
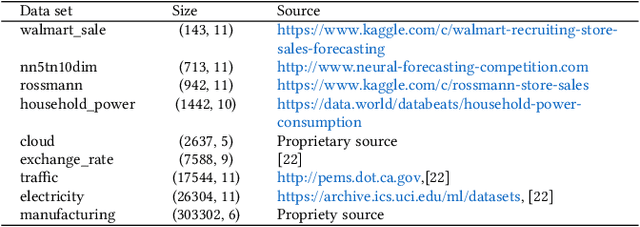
A large number of time series forecasting models including traditional statistical models, machine learning models and more recently deep learning have been proposed in the literature. However, choosing the right model along with good parameter values that performs well on a given data is still challenging. Automatically providing a good set of models to users for a given dataset saves both time and effort from using trial-and-error approaches with a wide variety of available models along with parameter optimization. We present AutoAI for Time Series Forecasting (AutoAI-TS) that provides users with a zero configuration (zero-conf ) system to efficiently train, optimize and choose best forecasting model among various classes of models for the given dataset. With its flexible zero-conf design, AutoAI-TS automatically performs all the data preparation, model creation, parameter optimization, training and model selection for users and provides a trained model that is ready to use. For given data, AutoAI-TS utilizes a wide variety of models including classical statistical models, Machine Learning (ML) models, statistical-ML hybrid models and deep learning models along with various transformations to create forecasting pipelines. It then evaluates and ranks pipelines using the proposed T-Daub mechanism to choose the best pipeline. The paper describe in detail all the technical aspects of AutoAI-TS along with extensive benchmarking on a variety of real world data sets for various use-cases. Benchmark results show that AutoAI-TS, with no manual configuration from the user, automatically trains and selects pipelines that on average outperform existing state-of-the-art time series forecasting toolkits.
Automated Machine Learning via ADMM
May 01, 2019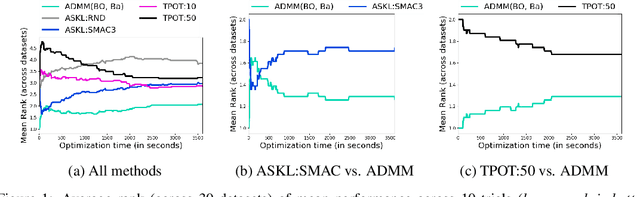
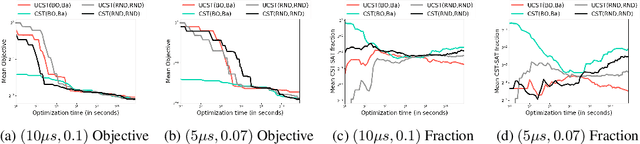
We study the automated machine learning (AutoML) problem of jointly selecting appropriate algorithms from an algorithm portfolio as well as optimizing their hyper-parameters for certain learning tasks. The main challenges include a) the coupling between algorithm selection and hyper-parameter optimization (HPO), and b) the black-box optimization nature of the problem where the optimizer cannot access the gradients of the loss function but may query function values. To circumvent these difficulties, we propose a new AutoML framework by leveraging the alternating direction method of multipliers (ADMM) scheme. Due to the splitting properties of ADMM, algorithm selection and HPO can be decomposed through the augmented Lagrangian function. As a result, HPO with mixed continuous and integer constraints are efficiently handled through a query-efficient Bayesian optimization approach and Euclidean projection operator that yields a closed-form solution. Algorithm selection in ADMM is naturally interpreted as a combinatorial bandit problem. The effectiveness of our proposed methodology is compared to state-of-the-art AutoML schemes such as TPOT and Auto-sklearn on numerous benchmark data sets.
Neurology-as-a-Service for the Developing World
Nov 22, 2017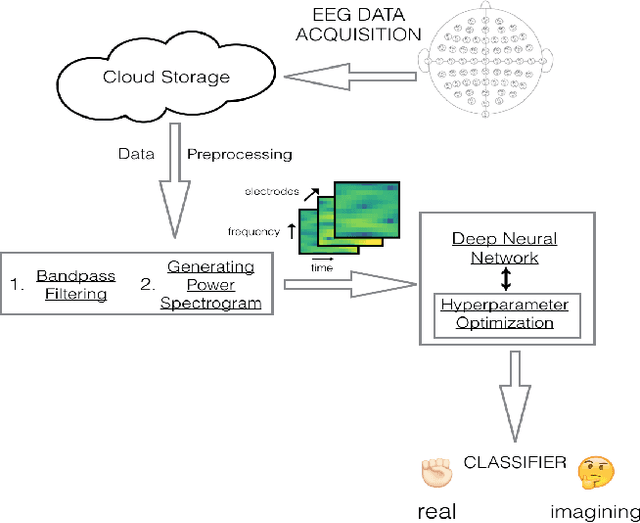

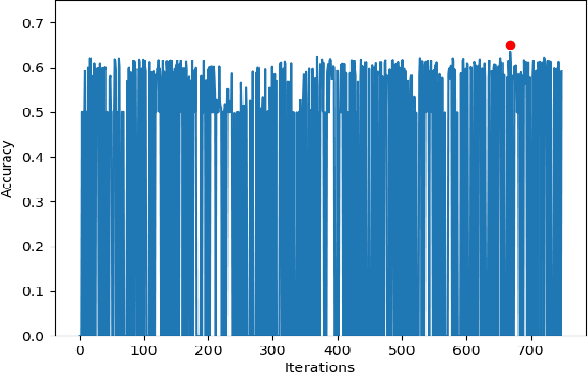
Electroencephalography (EEG) is an extensively-used and well-studied technique in the field of medical diagnostics and treatment for brain disorders, including epilepsy, migraines, and tumors. The analysis and interpretation of EEGs require physicians to have specialized training, which is not common even among most doctors in the developed world, let alone the developing world where physician shortages plague society. This problem can be addressed by teleEEG that uses remote EEG analysis by experts or by local computer processing of EEGs. However, both of these options are prohibitively expensive and the second option requires abundant computing resources and infrastructure, which is another concern in developing countries where there are resource constraints on capital and computing infrastructure. In this work, we present a cloud-based deep neural network approach to provide decision support for non-specialist physicians in EEG analysis and interpretation. Named `neurology-as-a-service,' the approach requires almost no manual intervention in feature engineering and in the selection of an optimal architecture and hyperparameters of the neural network. In this study, we deploy a pipeline that includes moving EEG data to the cloud and getting optimal models for various classification tasks. Our initial prototype has been tested only in developed world environments to-date, but our intention is to test it in developing world environments in future work. We demonstrate the performance of our proposed approach using the BCI2000 EEG MMI dataset, on which our service attains 63.4% accuracy for the task of classifying real vs. imaginary activity performed by the subject, which is significantly higher than what is obtained with a shallow approach such as support vector machines.