 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Learn Faster with Semantic Focus
Jun 18, 2025Various forms of sparse attention have been explored to mitigate the quadratic computational and memory cost of the attention mechanism in transformers. We study sparse transformers not through a lens of efficiency but rather in terms of learnability and generalization. Empirically studying a range of attention mechanisms, we find that input-dependent sparse attention models appear to converge faster and generalize better than standard attention models, while input-agnostic sparse attention models show no such benefits -- a phenomenon that is robust across architectural and optimization hyperparameter choices. This can be interpreted as demonstrating that concentrating a model's "semantic focus" with respect to the tokens currently being considered (in the form of input-dependent sparse attention) accelerates learning. We develop a theoretical characterization of the conditions that explain this behavior. We establish a connection between the stability of the standard softmax and the loss function's Lipschitz properties, then show how sparsity affects the stability of the softmax and the subsequent convergence and generalization guarantees resulting from the attention mechanism. This allows us to theoretically establish that input-agnostic sparse attention does not provide any benefits. We also characterize conditions when semantic focus (input-dependent sparse attention) can provide improved guarantees, and we validate that these conditions are in fact met in our empirical evaluations.
LogiCity: Advancing Neuro-Symbolic AI with Abstract Urban Simulation
Nov 01, 2024



Recent years have witnessed the rapid development of Neuro-Symbolic (NeSy) AI systems, which integrate symbolic reasoning into deep neural networks. However, most of the existing benchmarks for NeSy AI fail to provide long-horizon reasoning tasks with complex multi-agent interactions. Furthermore, they are usually constrained by fixed and simplistic logical rules over limited entities, making them far from real-world complexities. To address these crucial gaps, we introduce LogiCity, the first simulator based on customizable first-order logic (FOL) for an urban-like environment with multiple dynamic agents. LogiCity models diverse urban elements using semantic and spatial concepts, such as IsAmbulance(X) and IsClose(X, Y). These concepts are used to define FOL rules that govern the behavior of various agents. Since the concepts and rules are abstractions, they can be universally applied to cities with any agent compositions, facilitating the instantiation of diverse scenarios. Besides, a key feature of LogiCity is its support for user-configurable abstractions, enabling customizable simulation complexities for logical reasoning. To explore various aspects of NeSy AI, LogiCity introduces two tasks, one features long-horizon sequential decision-making, and the other focuses on one-step visual reasoning, varying in difficulty and agent behaviors. Our extensive evaluation reveals the advantage of NeSy frameworks in abstract reasoning. Moreover, we highlight the significant challenges of handling more complex abstractions in long-horizon multi-agent scenarios or under high-dimensional, imbalanced data. With its flexible design, various features, and newly raised challenges, we believe LogiCity represents a pivotal step forward in advancing the next generation of NeSy AI. All the code and data are open-sourced at our website.
What makes Models Compositional? A Theoretical View: With Supplement
May 02, 2024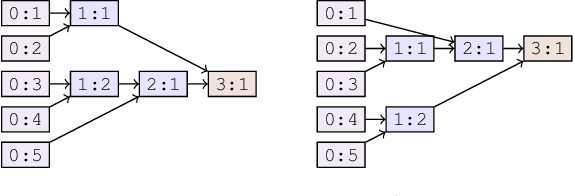
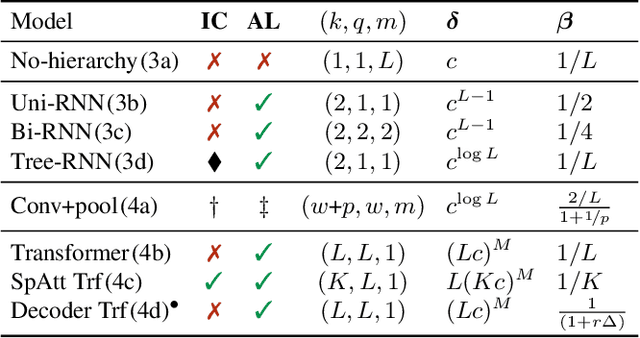


Compositionality is thought to be a key component of language, and various compositional benchmarks have been developed to empirically probe the compositional generalization of existing sequence processing models. These benchmarks often highlight failures of existing models, but it is not clear why these models fail in this way. In this paper, we seek to theoretically understand the role the compositional structure of the models plays in these failures and how this structure relates to their expressivity and sample complexity. We propose a general neuro-symbolic definition of compositional functions and their compositional complexity. We then show how various existing general and special purpose sequence processing models (such as recurrent, convolution and attention-based ones) fit this definition and use it to analyze their compositional complexity. Finally, we provide theoretical guarantees for the expressivity and systematic generalization of compositional models that explicitly depend on our proposed definition and highlighting factors which drive poor empirical performance.
Toward Theoretical Guidance for Two Common Questions in Practical Cross-Validation based Hyperparameter Selection
Jan 12, 2023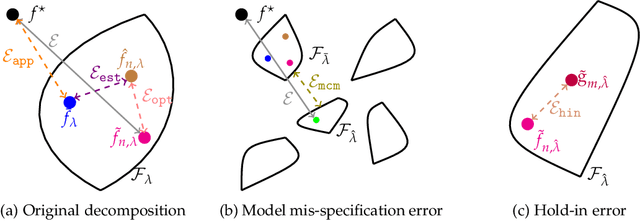

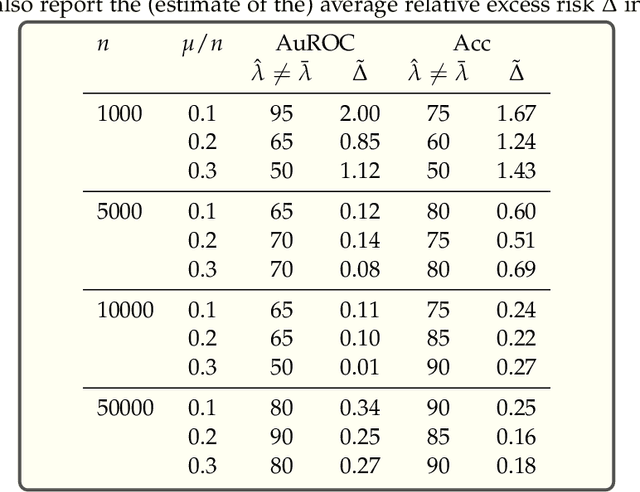
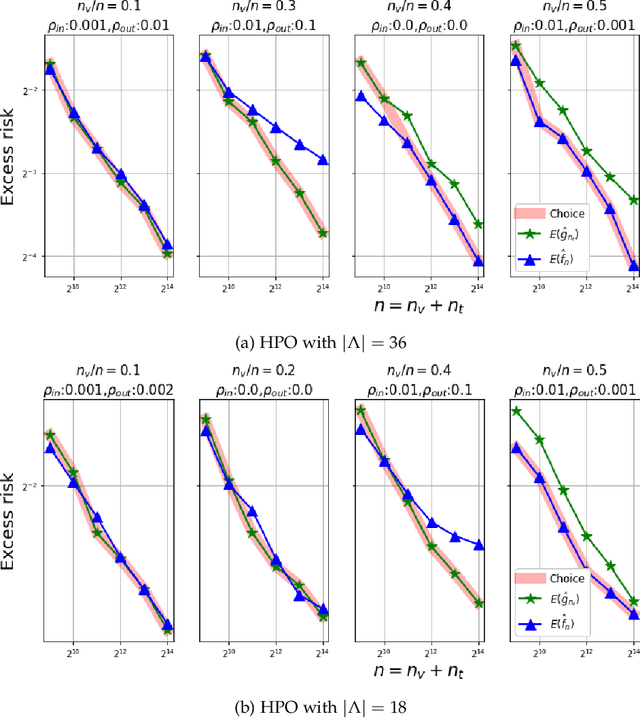
We show, to our knowledge, the first theoretical treatments of two common questions in cross-validation based hyperparameter selection: (1) After selecting the best hyperparameter using a held-out set, we train the final model using {\em all} of the training data -- since this may or may not improve future generalization error, should one do this? (2) During optimization such as via SGD (stochastic gradient descent), we must set the optimization tolerance $\rho$ -- since it trades off predictive accuracy with computation cost, how should one set it? Toward these problems, we introduce the {\em hold-in risk} (the error due to not using the whole training data), and the {\em model class mis-specification risk} (the error due to having chosen the wrong model class) in a theoretical view which is simple, general, and suggests heuristics that can be used when faced with a dataset instance. In proof-of-concept studies in synthetic data where theoretical quantities can be controlled, we show that these heuristics can, respectively, (1) always perform at least as well as always performing retraining or never performing retraining, (2) either improve performance or reduce computational overhead by $2\times$ with no loss in predictive performance.
Solving Constrained CASH Problems with ADMM
Jul 11, 2020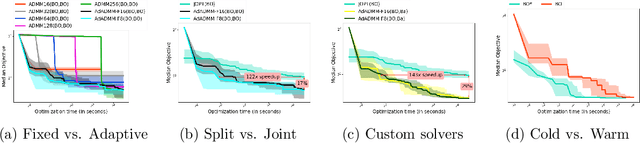
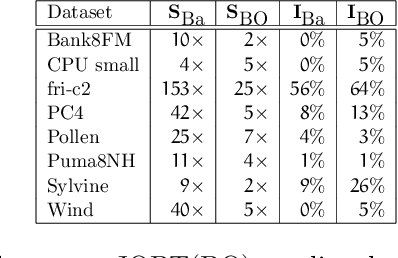
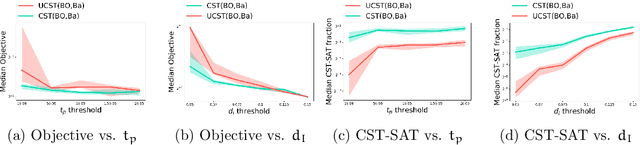
The CASH problem has been widely studied in the context of automated configurations of machine learning (ML) pipelines and various solvers and toolkits are available. However, CASH solvers do not directly handle black-box constraints such as fairness, robustness or other domain-specific custom constraints. We present our recent approach [Liu, et al., 2020] that leverages the ADMM optimization framework to decompose CASH into multiple small problems and demonstrate how ADMM facilitates incorporation of black-box constraints.
Building Bridges: Viewing Active Learning from the Multi-Armed Bandit Lens
Sep 26, 2013


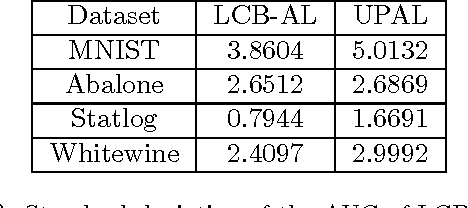
In this paper we propose a multi-armed bandit inspired, pool based active learning algorithm for the problem of binary classification. By carefully constructing an analogy between active learning and multi-armed bandits, we utilize ideas such as lower confidence bounds, and self-concordant regularization from the multi-armed bandit literature to design our proposed algorithm. Our algorithm is a sequential algorithm, which in each round assigns a sampling distribution on the pool, samples one point from this distribution, and queries the oracle for the label of this sampled point. The design of this sampling distribution is also inspired by the analogy between active learning and multi-armed bandits. We show how to derive lower confidence bounds required by our algorithm. Experimental comparisons to previously proposed active learning algorithms show superior performance on some standard UCI datasets.
Fast Exact Max-Kernel Search
Oct 26, 2012
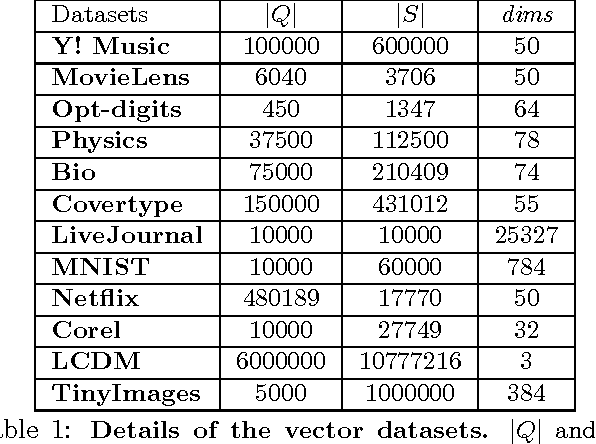
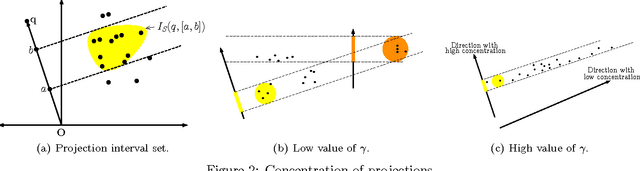
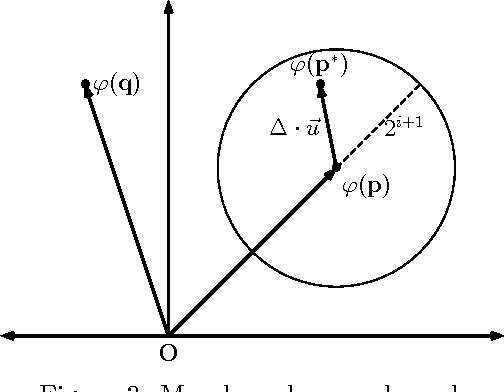
The wide applicability of kernels makes the problem of max-kernel search ubiquitous and more general than the usual similarity search in metric spaces. We focus on solving this problem efficiently. We begin by characterizing the inherent hardness of the max-kernel search problem with a novel notion of directional concentration. Following that, we present a method to use an $O(n \log n)$ algorithm to index any set of objects (points in $\Real^\dims$ or abstract objects) directly in the Hilbert space without any explicit feature representations of the objects in this space. We present the first provably $O(\log n)$ algorithm for exact max-kernel search using this index. Empirical results for a variety of data sets as well as abstract objects demonstrate up to 4 orders of magnitude speedup in some cases. Extensions for approximate max-kernel search are also presented.
MLPACK: A Scalable C++ Machine Learning Library
Oct 23, 2012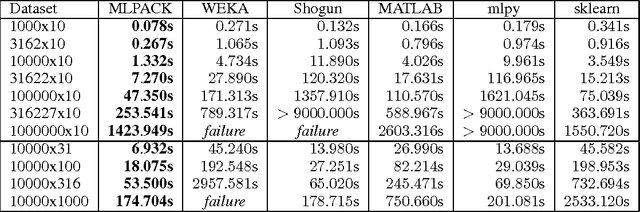
MLPACK is a state-of-the-art, scalable, multi-platform C++ machine learning library released in late 2011 offering both a simple, consistent API accessible to novice users and high performance and flexibility to expert users by leveraging modern features of C++. MLPACK provides cutting-edge algorithms whose benchmarks exhibit far better performance than other leading machine learning libraries. MLPACK version 1.0.3, licensed under the LGPL, is available at http://www.mlpack.org.
On the Sample Complexity of Predictive Sparse Coding
Oct 08, 2012The goal of predictive sparse coding is to learn a representation of examples as sparse linear combinations of elements from a dictionary, such that a learned hypothesis linear in the new representation performs well on a predictive task. Predictive sparse coding algorithms recently have demonstrated impressive performance on a variety of supervised tasks, but their generalization properties have not been studied. We establish the first generalization error bounds for predictive sparse coding, covering two settings: 1) the overcomplete setting, where the number of features k exceeds the original dimensionality d; and 2) the high or infinite-dimensional setting, where only dimension-free bounds are useful. Both learning bounds intimately depend on stability properties of the learned sparse encoder, as measured on the training sample. Consequently, we first present a fundamental stability result for the LASSO, a result characterizing the stability of the sparse codes with respect to perturbations to the dictionary. In the overcomplete setting, we present an estimation error bound that decays as \tilde{O}(sqrt(d k/m)) with respect to d and k. In the high or infinite-dimensional setting, we show a dimension-free bound that is \tilde{O}(sqrt(k^2 s / m)) with respect to k and s, where s is an upper bound on the number of non-zeros in the sparse code for any training data point.
Minimax Multi-Task Learning and a Generalized Loss-Compositional Paradigm for MTL
Sep 13, 2012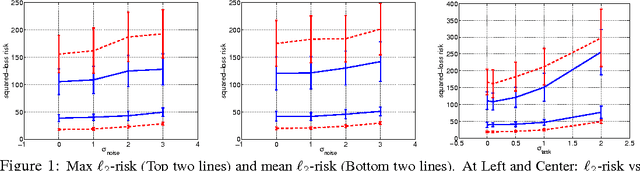

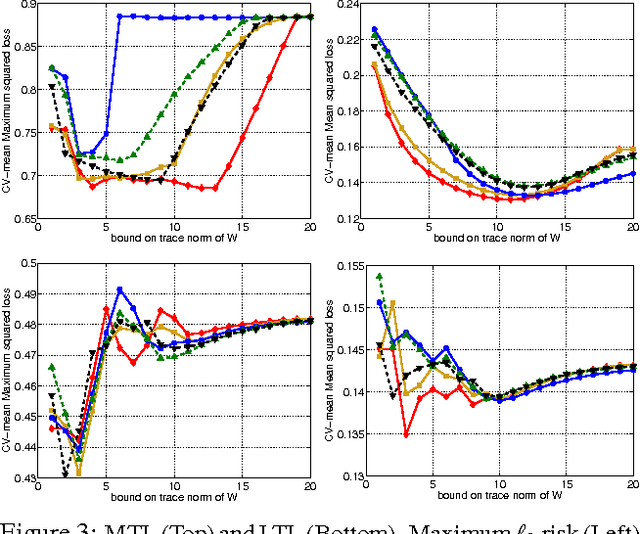
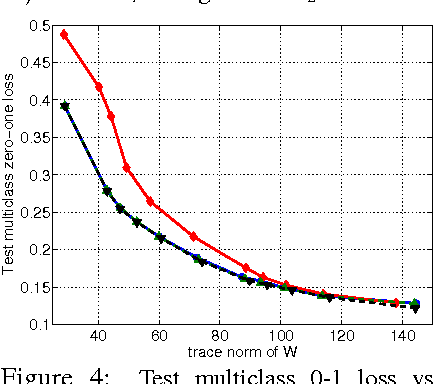
Since its inception, the modus operandi of multi-task learning (MTL) has been to minimize the task-wise mean of the empirical risks. We introduce a generalized loss-compositional paradigm for MTL that includes a spectrum of formulations as a subfamily. One endpoint of this spectrum is minimax MTL: a new MTL formulation that minimizes the maximum of the tasks' empirical risks. Via a certain relaxation of minimax MTL, we obtain a continuum of MTL formulations spanning minimax MTL and classical MTL. The full paradigm itself is loss-compositional, operating on the vector of empirical risks. It incorporates minimax MTL, its relaxations, and many new MTL formulations as special cases. We show theoretically that minimax MTL tends to avoid worst case outcomes on newly drawn test tasks in the learning to learn (LTL) test setting. The results of several MTL formulations on synthetic and real problems in the MTL and LTL test settings are encouraging.