 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Reinforcement Learning with Opponent Modeling for Distributed Multi-agent Cooperation
Jun 25, 2022
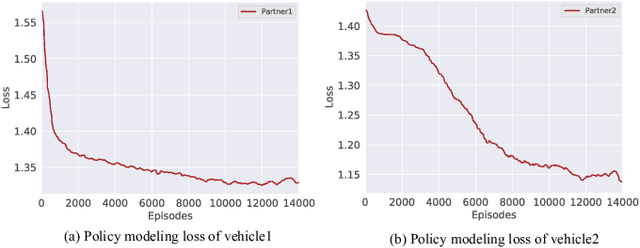
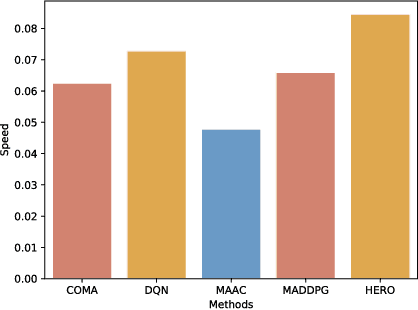

Many real-world applications can be formulated as multi-agent cooperation problems, such as network packet routing and coordination of autonomous vehicles. The emergence of deep reinforcement learning (DRL) provides a promising approach for multi-agent cooperation through the interaction of the agents and environments. However, traditional DRL solutions suffer from the high dimensions of multiple agents with continuous action space during policy search. Besides, the dynamicity of agents' policies makes the training non-stationary. To tackle the issues, we propose a hierarchical reinforcement learning approach with high-level decision-making and low-level individual control for efficient policy search. In particular, the cooperation of multiple agents can be learned in high-level discrete action space efficiently. At the same time, the low-level individual control can be reduced to single-agent reinforcement learning. In addition to hierarchical reinforcement learning, we propose an opponent modeling network to model other agents' policies during the learning process. In contrast to end-to-end DRL approaches, our approach reduces the learning complexity by decomposing the overall task into sub-tasks in a hierarchical way. To evaluate the efficiency of our approach, we conduct a real-world case study in the cooperative lane change scenario. Both simulation and real-world experiments show the superiority of our approach in the collision rate and convergence speed.
From Multi-agent to Multi-robot: A Scalable Training and Evaluation Platform for Multi-robot Reinforcement Learning
Jun 20, 2022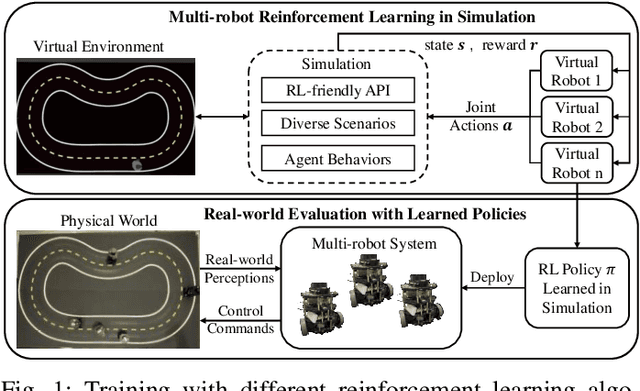

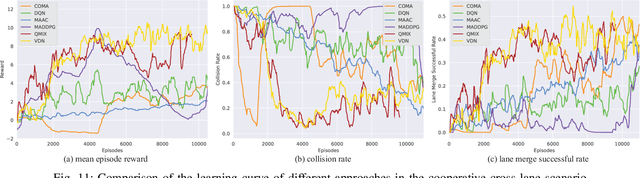

Multi-agent reinforcement learning (MARL) has been gaining extensive attention from academia and industries in the past few decades. One of the fundamental problems in MARL is how to evaluate different approaches comprehensively. Most existing MARL methods are evaluated in either video games or simplistic simulated scenarios. It remains unknown how these methods perform in real-world scenarios, especially multi-robot systems. This paper introduces a scalable emulation platform for multi-robot reinforcement learning (MRRL) called SMART to meet this need. Precisely, SMART consists of two components: 1) a simulation environment that provides a variety of complex interaction scenarios for training and 2) a real-world multi-robot system for realistic performance evaluation. Besides, SMART offers agent-environment APIs that are plug-and-play for algorithm implementation. To illustrate the practicality of our platform, we conduct a case study on the cooperative driving lane change scenario. Building off the case study, we summarize several unique challenges of MRRL, which are rarely considered previously. Finally, we open-source the simulation environments, associated benchmark tasks, and state-of-the-art baselines to encourage and empower MRRL research.