 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHC-LLM: Historical-Constrained Large Language Models for Radiology Report Generation
Dec 15, 2024



Radiology report generation (RRG) models typically focus on individual exams, often overlooking the integration of historical visual or textual data, which is crucial for patient follow-ups. Traditional methods usually struggle with long sequence dependencies when incorporating historical information, but large language models (LLMs) excel at in-context learning, making them well-suited for analyzing longitudinal medical data. In light of this, we propose a novel Historical-Constrained Large Language Models (HC-LLM) framework for RRG, empowering LLMs with longitudinal report generation capabilities by constraining the consistency and differences between longitudinal images and their corresponding reports. Specifically, our approach extracts both time-shared and time-specific features from longitudinal chest X-rays and diagnostic reports to capture disease progression. Then, we ensure consistent representation by applying intra-modality similarity constraints and aligning various features across modalities with multimodal contrastive and structural constraints. These combined constraints effectively guide the LLMs in generating diagnostic reports that accurately reflect the progression of the disease, achieving state-of-the-art results on the Longitudinal-MIMIC dataset. Notably, our approach performs well even without historical data during testing and can be easily adapted to other multimodal large models, enhancing its versatility.
CVPT: Cross-Attention help Visual Prompt Tuning adapt visual task
Aug 27, 2024In recent years, the rapid expansion of model sizes has led to large-scale pre-trained models demonstrating remarkable capabilities. Consequently, there has been a trend towards increasing the scale of models. However, this trend introduces significant challenges, including substantial computational costs of training and transfer to downstream tasks. To address these issues, Parameter-Efficient Fine-Tuning (PEFT) methods have been introduced. These methods optimize large-scale pre-trained models for specific tasks by fine-tuning a select group of parameters. Among these PEFT methods, adapter-based and prompt-based methods are the primary techniques. Specifically, in the field of visual fine-tuning, adapters gain prominence over prompts because of the latter's relatively weaker performance and efficiency. Under the circumstances, we refine the widely-used Visual Prompt Tuning (VPT) method, proposing Cross Visual Prompt Tuning (CVPT). CVPT calculates cross-attention between the prompt tokens and the embedded tokens, which allows us to compute the semantic relationship between them and conduct the fine-tuning of models exactly to adapt visual tasks better. Furthermore, we introduce the weight-sharing mechanism to initialize the parameters of cross-attention, which avoids massive learnable parameters from cross-attention and enhances the representative capability of cross-attention. We conduct comprehensive testing across 25 datasets and the result indicates that CVPT significantly improves VPT's performance and efficiency in visual tasks. For example, on the VTAB-1K benchmark, CVPT outperforms VPT over 4% in average accuracy, rivaling the advanced adapter-based methods in performance and efficiency. Our experiments confirm that prompt-based methods can achieve exceptional results in visual fine-tuning.
Teaching with Uncertainty: Unleashing the Potential of Knowledge Distillation in Object Detection
Jun 11, 2024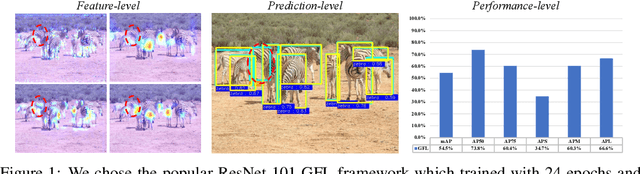
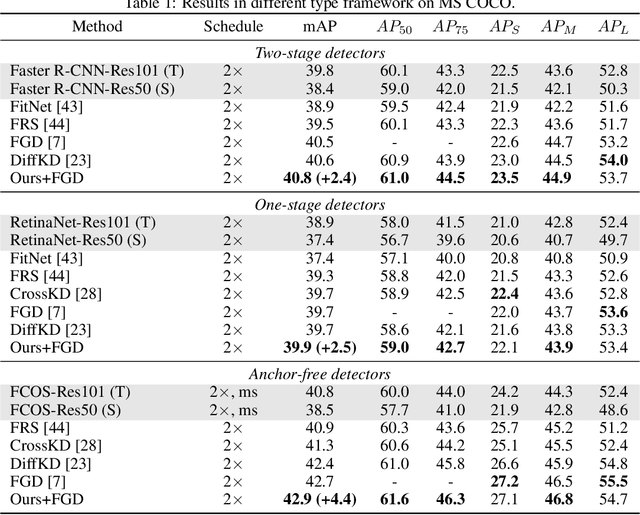
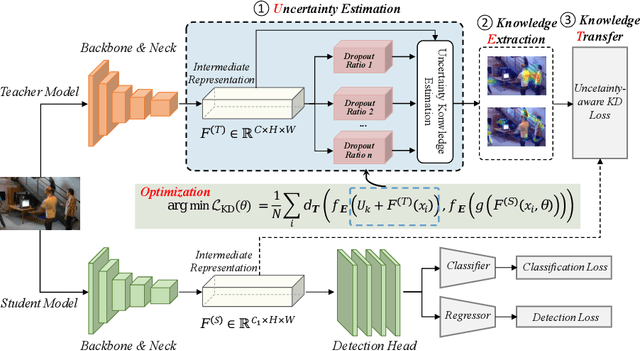
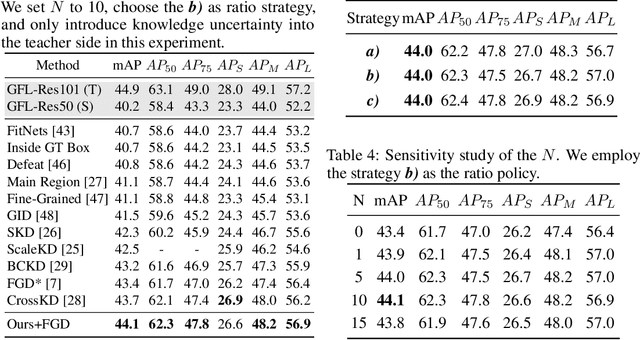
Knowledge distillation (KD) is a widely adopted and effective method for compressing models in object detection tasks. Particularly, feature-based distillation methods have shown remarkable performance. Existing approaches often ignore the uncertainty in the teacher model's knowledge, which stems from data noise and imperfect training. This limits the student model's ability to learn latent knowledge, as it may overly rely on the teacher's imperfect guidance. In this paper, we propose a novel feature-based distillation paradigm with knowledge uncertainty for object detection, termed "Uncertainty Estimation-Discriminative Knowledge Extraction-Knowledge Transfer (UET)", which can seamlessly integrate with existing distillation methods. By leveraging the Monte Carlo dropout technique, we introduce knowledge uncertainty into the training process of the student model, facilitating deeper exploration of latent knowledge. Our method performs effectively during the KD process without requiring intricate structures or extensive computational resources. Extensive experiments validate the effectiveness of our proposed approach across various distillation strategies, detectors, and backbone architectures. Specifically, following our proposed paradigm, the existing FGD method achieves state-of-the-art (SoTA) performance, with ResNet50-based GFL achieving 44.1% mAP on the COCO dataset, surpassing the baselines by 3.9%.