 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRFL: Simplifying Chemical Structure Recognition with Ring-Free Language
Dec 10, 2024



The primary objective of Optical Chemical Structure Recognition is to identify chemical structure images into corresponding markup sequences. However, the complex two-dimensional structures of molecules, particularly those with rings and multiple branches, present significant challenges for current end-to-end methods to learn one-dimensional markup directly. To overcome this limitation, we propose a novel Ring-Free Language (RFL), which utilizes a divide-and-conquer strategy to describe chemical structures in a hierarchical form. RFL allows complex molecular structures to be decomposed into multiple parts, ensuring both uniqueness and conciseness while enhancing readability. This approach significantly reduces the learning difficulty for recognition models. Leveraging RFL, we propose a universal Molecular Skeleton Decoder (MSD), which comprises a skeleton generation module that progressively predicts the molecular skeleton and individual rings, along with a branch classification module for predicting branch information. Experimental results demonstrate that the proposed RFL and MSD can be applied to various mainstream methods, achieving superior performance compared to state-of-the-art approaches in both printed and handwritten scenarios. The code is available at https://github.com/JingMog/RFL-MSD.
NAMER: Non-Autoregressive Modeling for Handwritten Mathematical Expression Recognition
Jul 16, 2024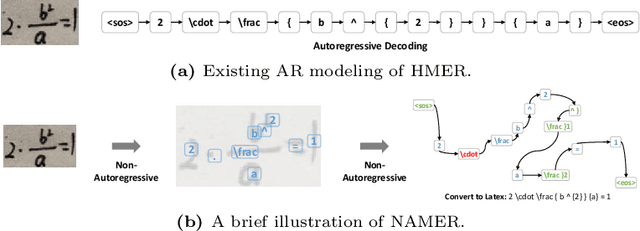
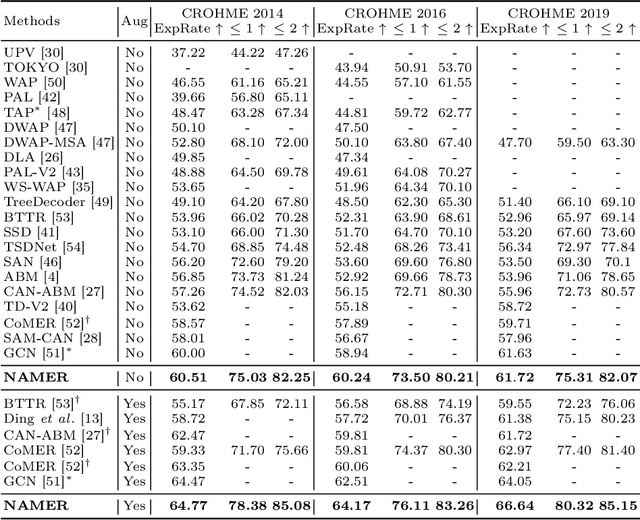
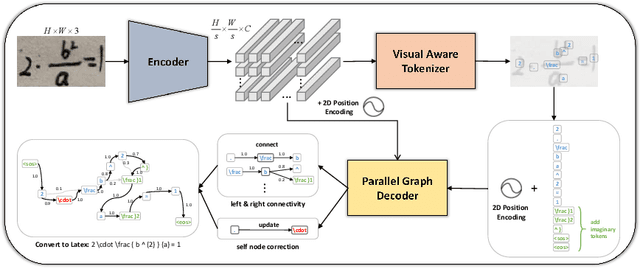
Recently, Handwritten Mathematical Expression Recognition (HMER) has gained considerable attention in pattern recognition for its diverse applications in document understanding. Current methods typically approach HMER as an image-to-sequence generation task within an autoregressive (AR) encoder-decoder framework. However, these approaches suffer from several drawbacks: 1) a lack of overall language context, limiting information utilization beyond the current decoding step; 2) error accumulation during AR decoding; and 3) slow decoding speed. To tackle these problems, this paper makes the first attempt to build a novel bottom-up Non-AutoRegressive Modeling approach for HMER, called NAMER. NAMER comprises a Visual Aware Tokenizer (VAT) and a Parallel Graph Decoder (PGD). Initially, the VAT tokenizes visible symbols and local relations at a coarse level. Subsequently, the PGD refines all tokens and establishes connectivities in parallel, leveraging comprehensive visual and linguistic contexts. Experiments on CROHME 2014/2016/2019 and HME100K datasets demonstrate that NAMER not only outperforms the current state-of-the-art (SOTA) methods on ExpRate by 1.93%/2.35%/1.49%/0.62%, but also achieves significant speedups of 13.7x and 6.7x faster in decoding time and overall FPS, proving the effectiveness and efficiency of NAMER.