 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Relational Topic Models through Dependent Gamma Processes
Paper and Code
Mar 30, 2015
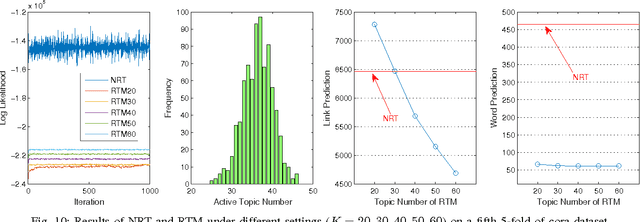

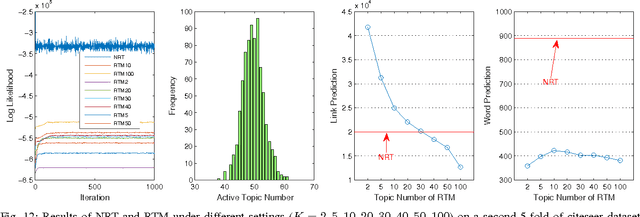
Traditional Relational Topic Models provide a way to discover the hidden topics from a document network. Many theoretical and practical tasks, such as dimensional reduction, document clustering, link prediction, benefit from this revealed knowledge. However, existing relational topic models are based on an assumption that the number of hidden topics is known in advance, and this is impractical in many real-world applications. Therefore, in order to relax this assumption, we propose a nonparametric relational topic model in this paper. Instead of using fixed-dimensional probability distributions in its generative model, we use stochastic processes. Specifically, a gamma process is assigned to each document, which represents the topic interest of this document. Although this method provides an elegant solution, it brings additional challenges when mathematically modeling the inherent network structure of typical document network, i.e., two spatially closer documents tend to have more similar topics. Furthermore, we require that the topics are shared by all the documents. In order to resolve these challenges, we use a subsampling strategy to assign each document a different gamma process from the global gamma process, and the subsampling probabilities of documents are assigned with a Markov Random Field constraint that inherits the document network structure. Through the designed posterior inference algorithm, we can discover the hidden topics and its number simultaneously. Experimental results on both synthetic and real-world network datasets demonstrate the capabilities of learning the hidden topics and, more importantly, the number of topics.