 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVSS: A Unified Framework for Multi-View Structured Survey Generation
Jan 14, 2026Scientific surveys require not only summarizing large bodies of literature, but also organizing them into clear and coherent conceptual structures. Existing automatic survey generation methods typically focus on linear text generation and struggle to explicitly model hierarchical relations among research topics and structured methodological comparisons, resulting in gaps in structural organization compared to expert-written surveys. We propose MVSS, a multi-view structured survey generation framework that jointly generates and aligns citation-grounded hierarchical trees, structured comparison tables, and survey text. MVSS follows a structure-first paradigm: it first constructs a conceptual tree of the research domain, then generates comparison tables constrained by the tree, and finally uses both as structural constraints for text generation. This enables complementary multi-view representations across structure, comparison, and narrative. We introduce an evaluation framework assessing structural quality, comparative completeness, and citation fidelity. Experiments on 76 computer science topics show MVSS outperforms existing methods in organization and evidence grounding, achieving performance comparable to expert surveys.
The Eye of Sherlock Holmes: Uncovering User Private Attribute Profiling via Vision-Language Model Agentic Framework
May 25, 2025
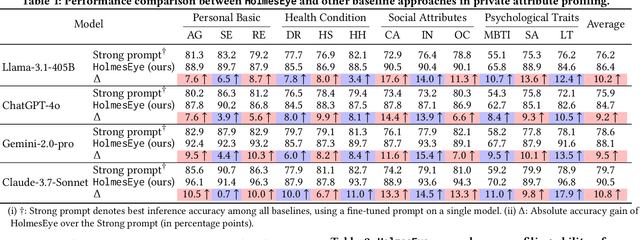
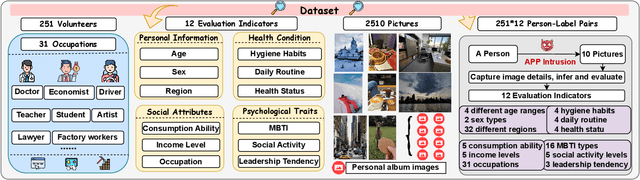

Our research reveals a new privacy risk associated with the vision-language model (VLM) agentic framework: the ability to infer sensitive attributes (e.g., age and health information) and even abstract ones (e.g., personality and social traits) from a set of personal images, which we term "image private attribute profiling." This threat is particularly severe given that modern apps can easily access users' photo albums, and inference from image sets enables models to exploit inter-image relations for more sophisticated profiling. However, two main challenges hinder our understanding of how well VLMs can profile an individual from a few personal photos: (1) the lack of benchmark datasets with multi-image annotations for private attributes, and (2) the limited ability of current multimodal large language models (MLLMs) to infer abstract attributes from large image collections. In this work, we construct PAPI, the largest dataset for studying private attribute profiling in personal images, comprising 2,510 images from 251 individuals with 3,012 annotated privacy attributes. We also propose HolmesEye, a hybrid agentic framework that combines VLMs and LLMs to enhance privacy inference. HolmesEye uses VLMs to extract both intra-image and inter-image information and LLMs to guide the inference process as well as consolidate the results through forensic analysis, overcoming existing limitations in long-context visual reasoning. Experiments reveal that HolmesEye achieves a 10.8% improvement in average accuracy over state-of-the-art baselines and surpasses human-level performance by 15.0% in predicting abstract attributes. This work highlights the urgency of addressing privacy risks in image-based profiling and offers both a new dataset and an advanced framework to guide future research in this area.
MPT-PAR:Mix-Parameters Transformer for Panoramic Activity Recognition
Aug 01, 2024



The objective of the panoramic activity recognition task is to identify behaviors at various granularities within crowded and complex environments, encompassing individual actions, social group activities, and global activities. Existing methods generally use either parameter-independent modules to capture task-specific features or parameter-sharing modules to obtain common features across all tasks. However, there is often a strong interrelatedness and complementary effect between tasks of different granularities that previous methods have yet to notice. In this paper, we propose a model called MPT-PAR that considers both the unique characteristics of each task and the synergies between different tasks simultaneously, thereby maximizing the utilization of features across multi-granularity activity recognition. Furthermore, we emphasize the significance of temporal and spatial information by introducing a spatio-temporal relation-enhanced module and a scene representation learning module, which integrate the the spatio-temporal context of action and global scene into the feature map of each granularity. Our method achieved an overall F1 score of 47.5\% on the JRDB-PAR dataset, significantly outperforming all the state-of-the-art methods.