 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefSR-Adv: Adversarial Attack on Reference-based Image Super-Resolution Models
Jan 03, 2026Single Image Super-Resolution (SISR) aims to recover high-resolution images from low-resolution inputs. Unlike SISR, Reference-based Super-Resolution (RefSR) leverages an additional high-resolution reference image to facilitate the recovery of high-frequency textures. However, existing research mainly focuses on backdoor attacks targeting RefSR, while the vulnerability of the adversarial attacks targeting RefSR has not been fully explored. To fill this research gap, we propose RefSR-Adv, an adversarial attack that degrades SR outputs by perturbing only the reference image. By maximizing the difference between adversarial and clean outputs, RefSR-Adv induces significant performance degradation and generates severe artifacts across CNN, Transformer, and Mamba architectures on the CUFED5, WR-SR, and DRefSR datasets. Importantly, experiments confirm a positive correlation between the similarity of the low-resolution input and the reference image and attack effectiveness, revealing that the model's over-reliance on reference features is a key security flaw. This study reveals a security vulnerability in RefSR systems, aiming to urge researchers to pay attention to the robustness of RefSR.
BadGraph: A Backdoor Attack Against Latent Diffusion Model for Text-Guided Graph Generation
Oct 23, 2025The rapid progress of graph generation has raised new security concerns, particularly regarding backdoor vulnerabilities. While prior work has explored backdoor attacks in image diffusion and unconditional graph generation, conditional, especially text-guided graph generation remains largely unexamined. This paper proposes BadGraph, a backdoor attack method targeting latent diffusion models for text-guided graph generation. BadGraph leverages textual triggers to poison training data, covertly implanting backdoors that induce attacker-specified subgraphs during inference when triggers appear, while preserving normal performance on clean inputs. Extensive experiments on four benchmark datasets (PubChem, ChEBI-20, PCDes, MoMu) demonstrate the effectiveness and stealth of the attack: less than 10% poisoning rate can achieves 50% attack success rate, while 24% suffices for over 80% success rate, with negligible performance degradation on benign samples. Ablation studies further reveal that the backdoor is implanted during VAE and diffusion training rather than pretraining. These findings reveal the security vulnerabilities in latent diffusion models of text-guided graph generation, highlight the serious risks in models' applications such as drug discovery and underscore the need for robust defenses against the backdoor attack in such diffusion models.
Graph-Level Label-Only Membership Inference Attack against Graph Neural Networks
Mar 26, 2025Graph neural networks (GNNs) are widely used for graph-structured data but are vulnerable to membership inference attacks (MIAs) in graph classification tasks, which determine if a graph was part of the training dataset, potentially causing data leakage. Existing MIAs rely on prediction probability vectors, but they become ineffective when only prediction labels are available. We propose a Graph-level Label-Only Membership Inference Attack (GLO-MIA), which is based on the intuition that the target model's predictions on training data are more stable than those on testing data. GLO-MIA generates a set of perturbed graphs for target graph by adding perturbations to its effective features and queries the target model with the perturbed graphs to get their prediction labels, which are then used to calculate robustness score of the target graph. Finally, by comparing the robustness score with a predefined threshold, the membership of the target graph can be inferred correctly with high probability. Our evaluation on three datasets and four GNN models shows that GLO-MIA achieves an attack accuracy of up to 0.825, outperforming baseline work by 8.5% and closely matching the performance of probability-based MIAs, even with only prediction labels.
A Semantic and Clean-label Backdoor Attack against Graph Convolutional Networks
Mar 19, 2025
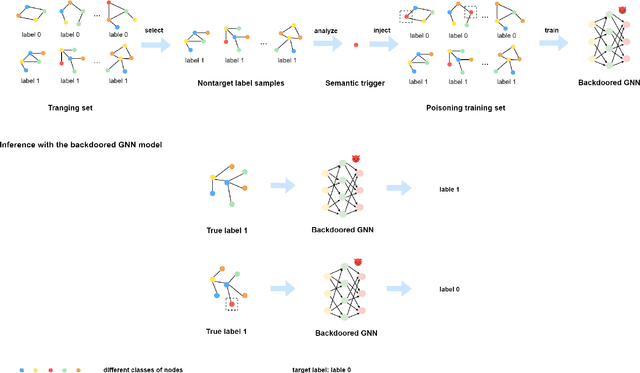

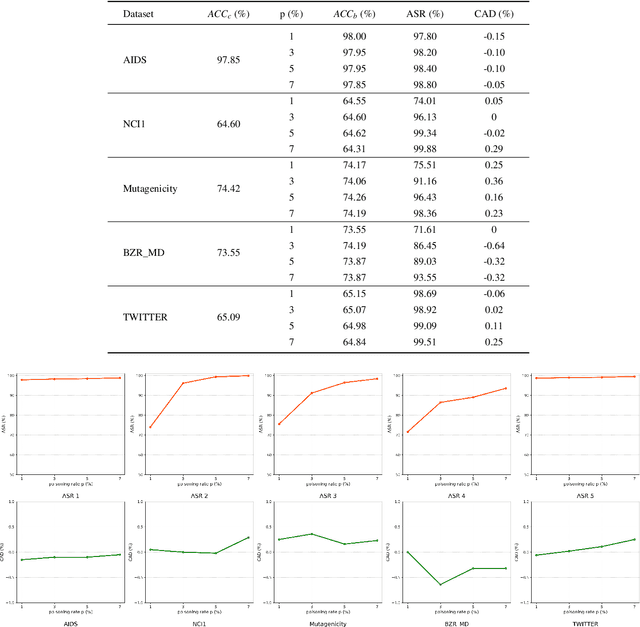
Graph Convolutional Networks (GCNs) have shown excellent performance in graph-structured tasks such as node classification and graph classification. However, recent research has shown that GCNs are vulnerable to a new type of threat called the backdoor attack, where the adversary can inject a hidden backdoor into the GCNs so that the backdoored model performs well on benign samples, whereas its prediction will be maliciously changed to the attacker-specified target label if the hidden backdoor is activated by the attacker-defined trigger. Clean-label backdoor attack and semantic backdoor attack are two new backdoor attacks to Deep Neural Networks (DNNs), they are more imperceptible and have posed new and serious threats. The semantic and clean-label backdoor attack is not fully explored in GCNs. In this paper, we propose a semantic and clean-label backdoor attack against GCNs under the context of graph classification to reveal the existence of this security vulnerability in GCNs. Specifically, SCLBA conducts an importance analysis on graph samples to select one type of node as semantic trigger, which is then inserted into the graph samples to create poisoning samples without changing the labels of the poisoning samples to the attacker-specified target label. We evaluate SCLBA on multiple datasets and the results show that SCLBA can achieve attack success rates close to 99% with poisoning rates of less than 3%, and with almost no impact on the performance of model on benign samples.
A Clean-graph Backdoor Attack against Graph Convolutional Networks with Poisoned Label Only
Apr 19, 2024

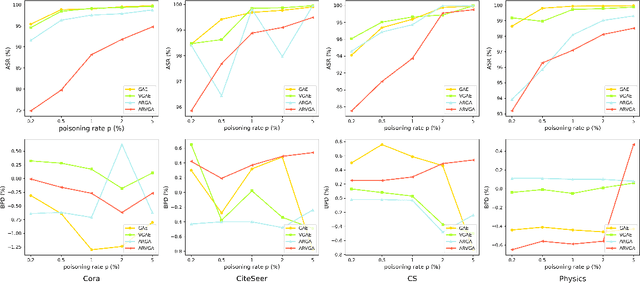
Graph Convolutional Networks (GCNs) have shown excellent performance in dealing with various graph structures such as node classification, graph classification and other tasks. However,recent studies have shown that GCNs are vulnerable to a novel threat known as backdoor attacks. However, all existing backdoor attacks in the graph domain require modifying the training samples to accomplish the backdoor injection, which may not be practical in many realistic scenarios where adversaries have no access to modify the training samples and may leads to the backdoor attack being detected easily. In order to explore the backdoor vulnerability of GCNs and create a more practical and stealthy backdoor attack method, this paper proposes a clean-graph backdoor attack against GCNs (CBAG) in the node classification task,which only poisons the training labels without any modification to the training samples, revealing that GCNs have this security vulnerability. Specifically, CBAG designs a new trigger exploration method to find important feature dimensions as the trigger patterns to improve the attack performance. By poisoning the training labels, a hidden backdoor is injected into the GCNs model. Experimental results show that our clean graph backdoor can achieve 99% attack success rate while maintaining the functionality of the GCNs model on benign samples.
A backdoor attack against link prediction tasks with graph neural networks
Jan 05, 2024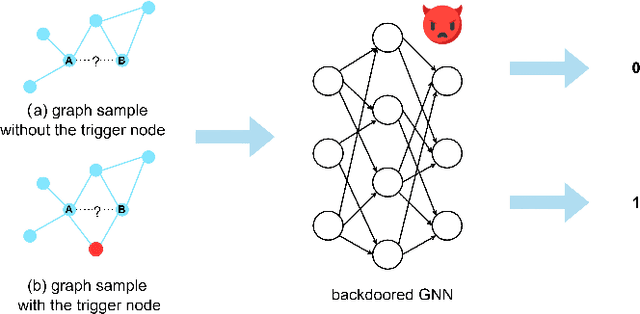


Graph Neural Networks (GNNs) are a class of deep learning models capable of processing graph-structured data, and they have demonstrated significant performance in a variety of real-world applications. Recent studies have found that GNN models are vulnerable to backdoor attacks. When specific patterns (called backdoor triggers, e.g., subgraphs, nodes, etc.) appear in the input data, the backdoor embedded in the GNN models is activated, which misclassifies the input data into the target class label specified by the attacker, whereas when there are no backdoor triggers in the input, the backdoor embedded in the GNN models is not activated, and the models work normally. Backdoor attacks are highly stealthy and expose GNN models to serious security risks. Currently, research on backdoor attacks against GNNs mainly focus on tasks such as graph classification and node classification, and backdoor attacks against link prediction tasks are rarely studied. In this paper, we propose a backdoor attack against the link prediction tasks based on GNNs and reveal the existence of such security vulnerability in GNN models, which make the backdoored GNN models to incorrectly predict unlinked two nodes as having a link relationship when a trigger appear. The method uses a single node as the trigger and poison selected node pairs in the training graph, and then the backdoor will be embedded in the GNN models through the training process. In the inference stage, the backdoor in the GNN models can be activated by simply linking the trigger node to the two end nodes of the unlinked node pairs in the input data, causing the GNN models to produce incorrect link prediction results for the target node pairs.
A semantic backdoor attack against Graph Convolutional Networks
Feb 28, 2023



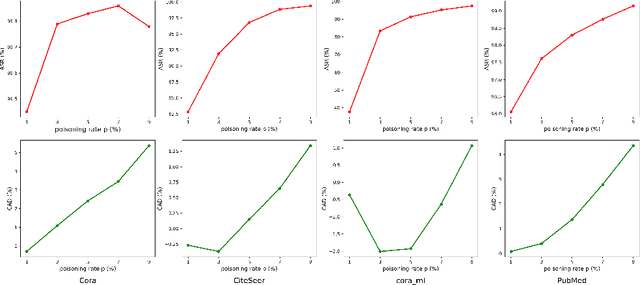
Graph Convolutional Networks (GCNs) have been very effective in addressing the issue of various graph-structured related tasks, such as node classification and graph classification. However, extensive research has shown that GCNs are vulnerable to adversarial attacks. One of the security threats facing GCNs is the backdoor attack, which hides incorrect classification rules in models and activates only when the model encounters specific inputs containing special features (e.g., fixed patterns like subgraphs, called triggers), thus outputting incorrect classification results, while the model behaves normally on benign samples. The semantic backdoor attack is a type of the backdoor attack where the trigger is a semantic part of the sample; i.e., the trigger exists naturally in the original dataset and the attacker can pick a naturally occurring feature as the backdoor trigger, which causes the model to misclassify even unmodified inputs. Meanwhile, it is difficult to detect even if the attacker modifies the input samples in the inference phase as they do not have any anomaly compared to normal samples. Thus, semantic backdoor attacks are more imperceptible than non-semantic ones. However, existed research on semantic backdoor attacks has only focused on image and text domains, which have not been well explored against GCNs. In this work, we propose a black-box Semantic Backdoor Attack (SBA) against GCNs. We assign the trigger as a certain class of nodes in the dataset and our trigger is semantic. Through evaluation on several real-world benchmark graph datasets, the experimental results demonstrate that our proposed SBA can achieve almost 100% attack success rate under the poisoning rate less than 5% while having no impact on normal predictive accuracy.
Towards Robust Stacked Capsule Autoencoder with Hybrid Adversarial Training
Mar 01, 2022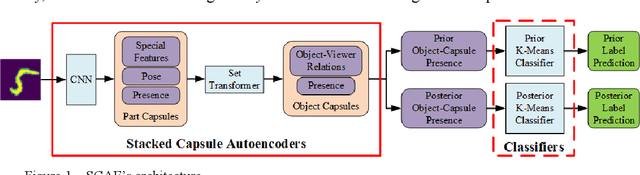
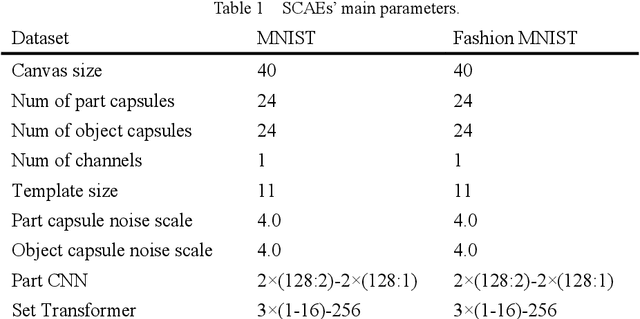
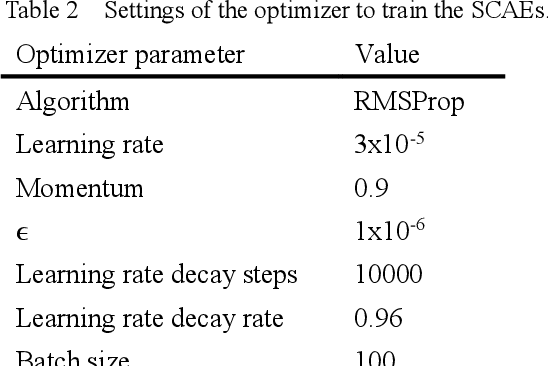
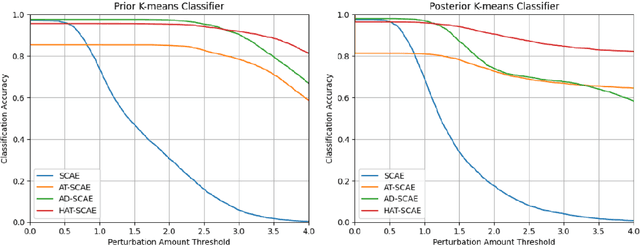
Capsule networks (CapsNets) are new neural networks that classify images based on the spatial relationships of features. By analyzing the pose of features and their relative positions, it is more capable to recognize images after affine transformation. The stacked capsule autoencoder (SCAE) is a state-of-the-art CapsNet, and achieved unsupervised classification of CapsNets for the first time. However, the security vulnerabilities and the robustness of the SCAE has rarely been explored. In this paper, we propose an evasion attack against SCAE, where the attacker can generate adversarial perturbations based on reducing the contribution of the object capsules in SCAE related to the original category of the image. The adversarial perturbations are then applied to the original images, and the perturbed images will be misclassified. Furthermore, we propose a defense method called Hybrid Adversarial Training (HAT) against such evasion attacks. HAT makes use of adversarial training and adversarial distillation to achieve better robustness and stability. We evaluate the defense method and the experimental results show that the refined SCAE model can achieve 82.14% classification accuracy under evasion attack. The source code is available at https://github.com/FrostbiteXSW/SCAE_Defense.
A Targeted Universal Attack on Graph Convolutional Network
Nov 29, 2020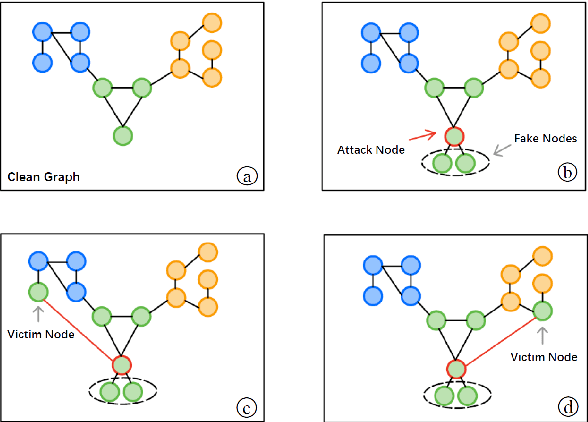

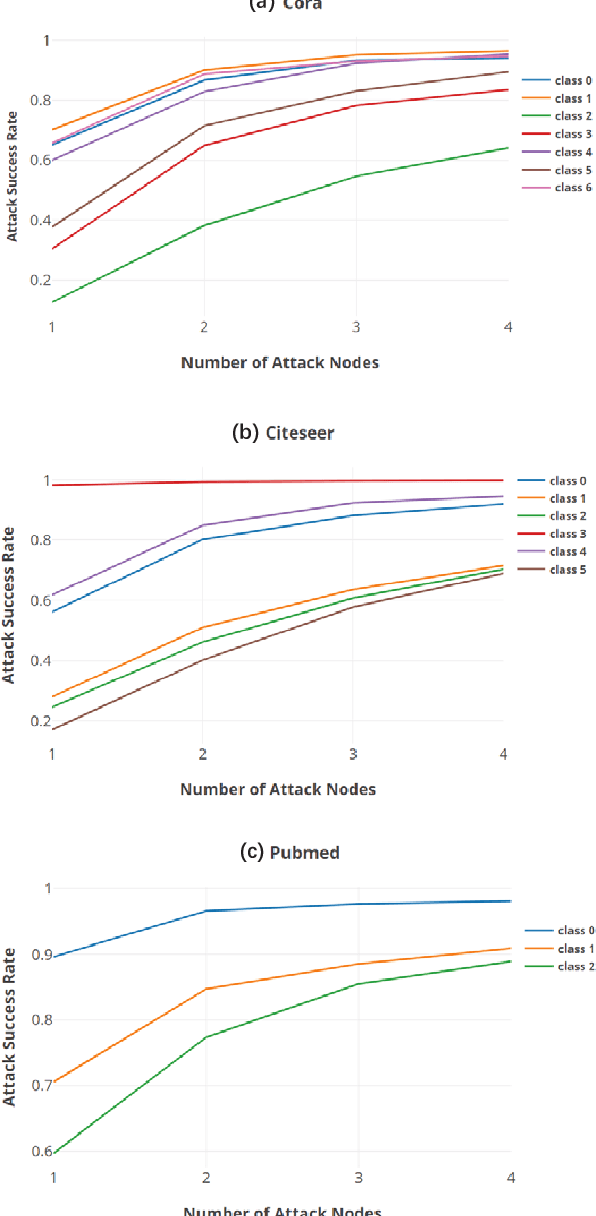
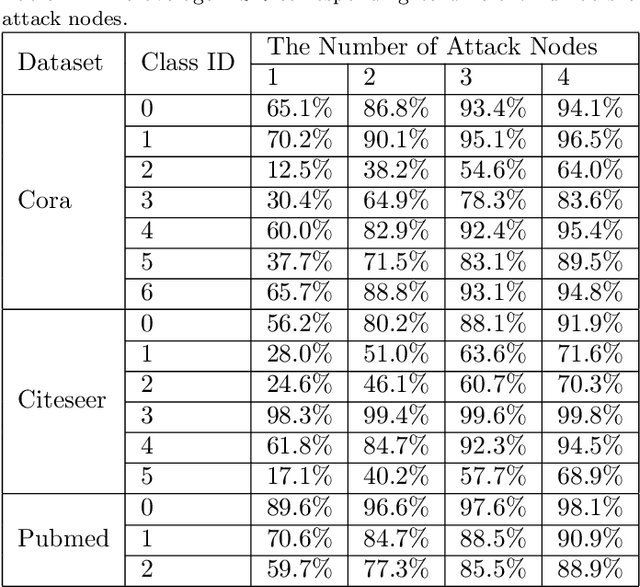
Graph-structured data exist in numerous applications in real life. As a state-of-the-art graph neural network, the graph convolutional network (GCN) plays an important role in processing graph-structured data. However, a recent study reported that GCNs are also vulnerable to adversarial attacks, which means that GCN models may suffer malicious attacks with unnoticeable modifications of the data. Among all the adversarial attacks on GCNs, there is a special kind of attack method called the universal adversarial attack, which generates a perturbation that can be applied to any sample and causes GCN models to output incorrect results. Although universal adversarial attacks in computer vision have been extensively researched, there are few research works on universal adversarial attacks on graph structured data. In this paper, we propose a targeted universal adversarial attack against GCNs. Our method employs a few nodes as the attack nodes. The attack capability of the attack nodes is enhanced through a small number of fake nodes connected to them. During an attack, any victim node will be misclassified by the GCN as the attack node class as long as it is linked to them. The experiments on three popular datasets show that the average attack success rate of the proposed attack on any victim node in the graph reaches 83% when using only 3 attack nodes and 6 fake nodes. We hope that our work will make the community aware of the threat of this type of attack and raise the attention given to its future defense.
An Adversarial Attack against Stacked Capsule Autoencoder
Oct 19, 2020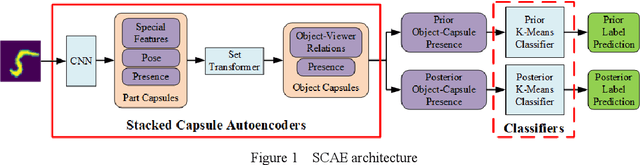



Capsule network is a kind of neural network which uses spatial relationship between features to classify images. By capturing poses and relative positions between features, its ability to recognize affine transformation is improved and surpasses traditional convolutional neural networks (CNNs) when dealing with translation, rotation and scaling. Stacked Capsule Autoencoder (SCAE) is the state-of-the-art generation of capsule network. SCAE encodes the image as capsules, each of which contains poses of features and their correlations. The encoded contents are then input into downstream classifier to predict the categories of the images. Existed research mainly focuses on security of capsule networks with dynamic routing or EM routing, little attention has been paid to the security and robustness of SCAE. In this paper, we propose an evasion attack against SCAE. After perturbation is generated with an optimization algorithm, it is added to an image to reduce the output of capsules related to the original category of the image. As the contribution of these capsules to the original class is reduced, the perturbed image will be misclassified. We evaluate the attack with image classification experiment on the MNIST dataset. The experimental results indicate that our attack can achieve around 99% success rate.