 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAG-X: Systematic Diagnosis of Retrieval-Augmented Generation for Medical Question Answering
Mar 03, 2026Automated question-answering (QA) systems increasingly rely on retrieval-augmented generation (RAG) to ground large language models (LLMs) in authoritative medical knowledge, ensuring clinical accuracy and patient safety in Artificial Intelligence (AI) applications for healthcare. Despite progress in RAG evaluation, current benchmarks focus only on simple multiple-choice QA tasks and employ metrics that poorly capture the semantic precision required for complex QA tasks. These approaches fail to diagnose whether an error stems from faulty retrieval or flawed generation, limiting developers from performing targeted improvement. To address this gap, we propose RAG-X, a diagnostic framework that evaluates the retriever and generator independently across a triad of QA tasks: information extraction, short-answer generation, and multiple-choice question (MCQ) answering. RAG-X introduces Context Utilization Efficiency (CUE) metrics to disaggregate system success into interpretable quadrants, isolating verified grounding from deceptive accuracy. Our experiments reveal an ``Accuracy Fallacy", where a 14\% gap separates perceived system success from evidence-based grounding. By surfacing hidden failure modes, RAG-X offers the diagnostic transparency needed for safe and verifiable clinical RAG systems.
Emotion Correlation Mining Through Deep Learning Models on Natural Language Text
Jul 28, 2020


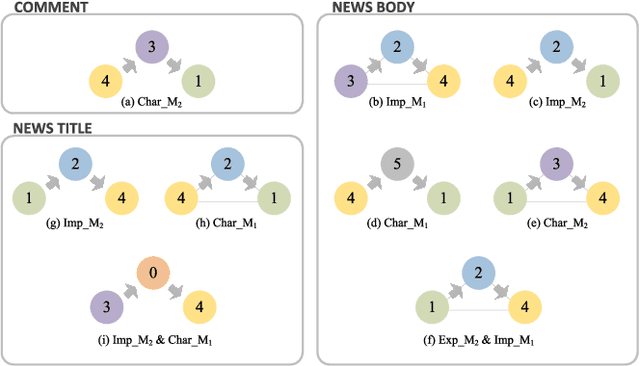
Emotion analysis has been attracting researchers' attention. Most previous works in the artificial intelligence field focus on recognizing emotion rather than mining the reason why emotions are not or wrongly recognized. Correlation among emotions contributes to the failure of emotion recognition. In this paper, we try to fill the gap between emotion recognition and emotion correlation mining through natural language text from web news. Correlation among emotions, expressed as the confusion and evolution of emotion, is primarily caused by human emotion cognitive bias. To mine emotion correlation from emotion recognition through text, three kinds of features and two deep neural network models are presented. The emotion confusion law is extracted through orthogonal basis. The emotion evolution law is evaluated from three perspectives, one-step shift, limited-step shifts, and shortest path transfer. The method is validated using three datasets-the titles, the bodies, and the comments of news articles, covering both objective and subjective texts in varying lengths (long and short). The experimental results show that, in subjective comments, emotions are easily mistaken as anger. Comments tend to arouse emotion circulations of love-anger and sadness-anger. In objective news, it is easy to recognize text emotion as love and cause fear-joy circulation. That means, journalists may try to attract attention using fear and joy words but arouse the emotion love instead; After news release, netizens generate emotional comments to express their intense emotions, i.e., anger, sadness, and love. These findings could provide insights for applications regarding affective interaction such as network public sentiment, social media communication, and human-computer interaction.
Exploring the Suitability of Semantic Spaces as Word Association Models for the Extraction of Semantic Relationships
Apr 29, 2020
Given the recent advances and progress in Natural Language Processing (NLP), extraction of semantic relationships has been at the top of the research agenda in the last few years. This work has been mainly motivated by the fact that building knowledge graphs (KG) and bases (KB), as a key ingredient of intelligent applications, is a never-ending challenge, since new knowledge needs to be harvested while old knowledge needs to be revised. Currently, approaches towards relation extraction from text are dominated by neural models practicing some sort of distant (weak) supervision in machine learning from large corpora, with or without consulting external knowledge sources. In this paper, we empirically study and explore the potential of a novel idea of using classical semantic spaces and models, e.g., Word Embedding, generated for extracting word association, in conjunction with relation extraction approaches. The goal is to use these word association models to reinforce current relation extraction approaches. We believe that this is a first attempt of this kind and the results of the study should shed some light on the extent to which these word association models can be used as well as the most promising types of relationships to be considered for extraction.