 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinite Author Topic Model based on Mixed Gamma-Negative Binomial Process
Paper and Code
Mar 30, 2015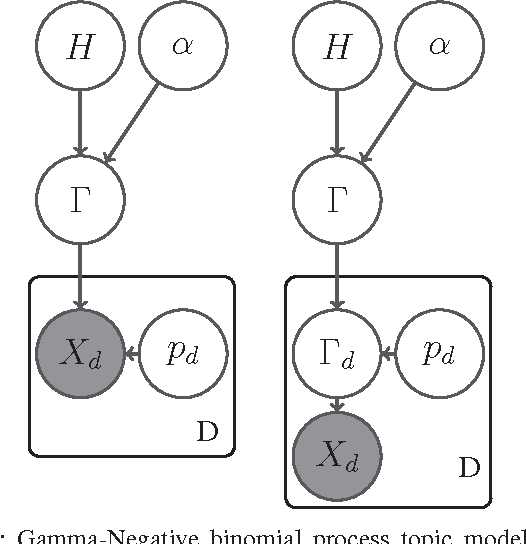


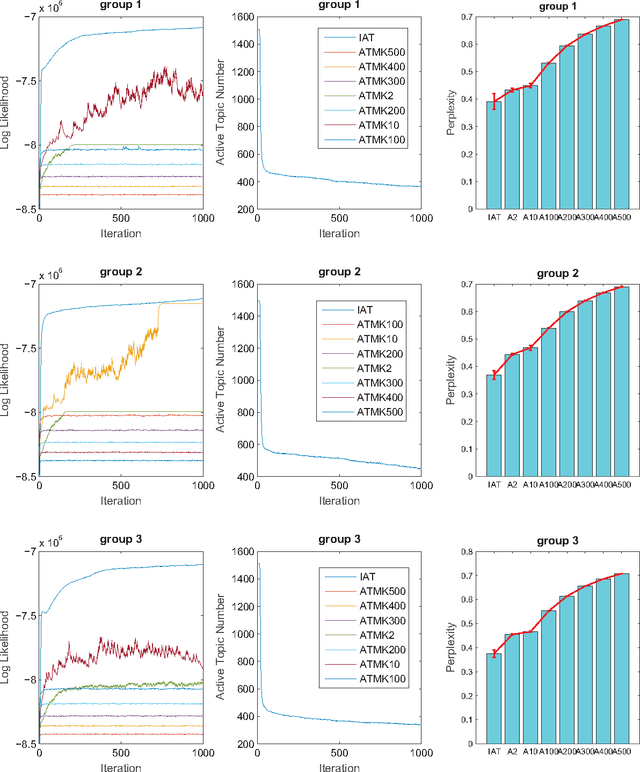
Incorporating the side information of text corpus, i.e., authors, time stamps, and emotional tags, into the traditional text mining models has gained significant interests in the area of information retrieval, statistical natural language processing, and machine learning. One branch of these works is the so-called Author Topic Model (ATM), which incorporates the authors's interests as side information into the classical topic model. However, the existing ATM needs to predefine the number of topics, which is difficult and inappropriate in many real-world settings. In this paper, we propose an Infinite Author Topic (IAT) model to resolve this issue. Instead of assigning a discrete probability on fixed number of topics, we use a stochastic process to determine the number of topics from the data itself. To be specific, we extend a gamma-negative binomial process to three levels in order to capture the author-document-keyword hierarchical structure. Furthermore, each document is assigned a mixed gamma process that accounts for the multi-author's contribution towards this document. An efficient Gibbs sampling inference algorithm with each conditional distribution being closed-form is developed for the IAT model. Experiments on several real-world datasets show the capabilities of our IAT model to learn the hidden topics, authors' interests on these topics and the number of topics simultaneously.