 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-layer Attention Sharing for Large Language Models
Paper and Code
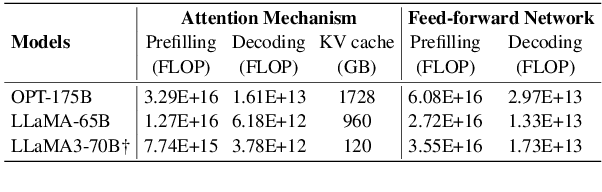
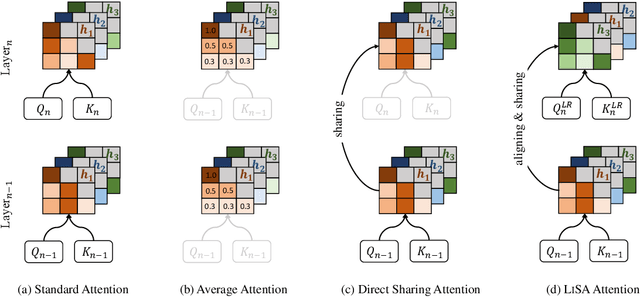
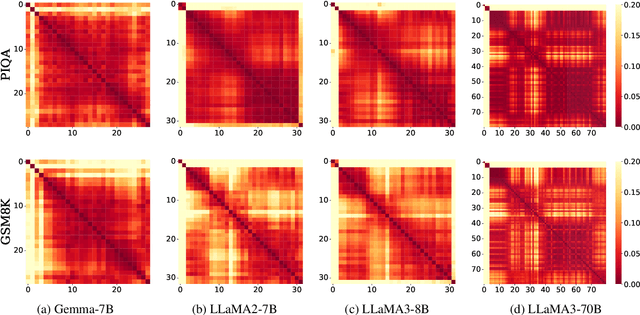
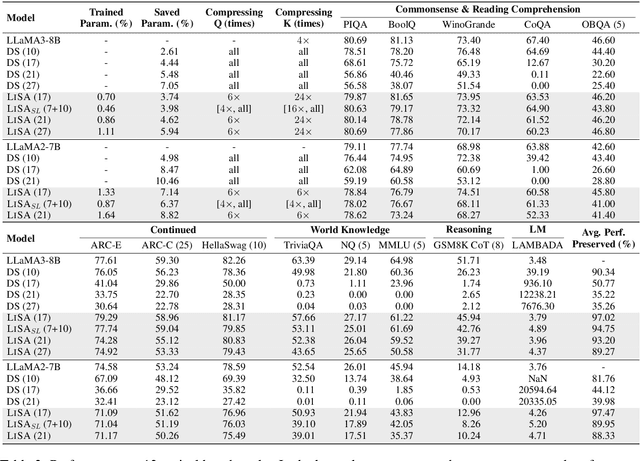
As large language models (LLMs) evolve, the increase in model depth and parameter number leads to substantial redundancy. To enhance the efficiency of the attention mechanism, previous works primarily compress the KV cache or group attention heads, while largely overlooking redundancy between layers. Our comprehensive analyses across various LLMs show that highly similar attention patterns persist within most layers. It's intuitive to save the computation by sharing attention weights across layers. However, further analysis reveals two challenges: (1) Directly sharing the weight matrix without carefully rearranging the attention heads proves to be ineffective; (2) Shallow layers are vulnerable to small deviations in attention weights. Driven by these insights, we introduce LiSA, a lightweight substitute for self-attention in well-trained LLMs. LiSA employs tiny feed-forward networks to align attention heads between adjacent layers and low-rank matrices to approximate differences in layer-wise attention weights. Evaluations encompassing 13 typical benchmarks demonstrate that LiSA maintains high response quality in terms of accuracy and perplexity while reducing redundant attention calculations within 53-84% of the total layers. Our implementations of LiSA achieve a 6X compression of Q and K, with maximum throughput improvements of 19.5% for LLaMA3-8B and 32.3% for LLaMA2-7B.