 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe state-of-the-art in Cardiac MRI Reconstruction: Results of the CMRxRecon Challenge in MICCAI 2023
Apr 01, 2024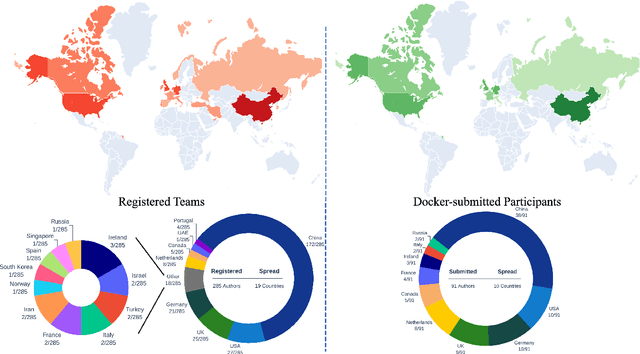
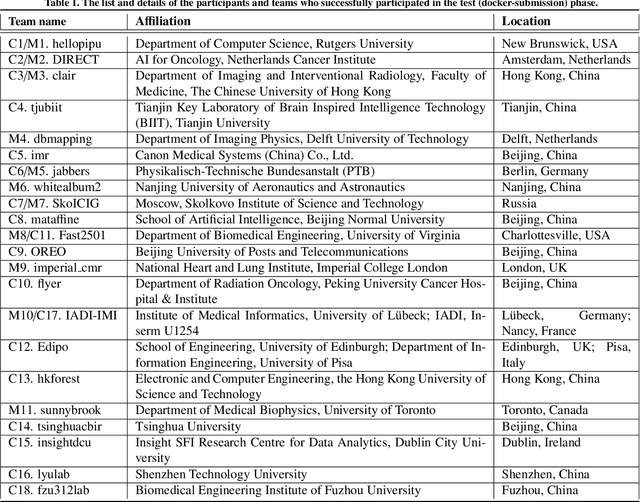
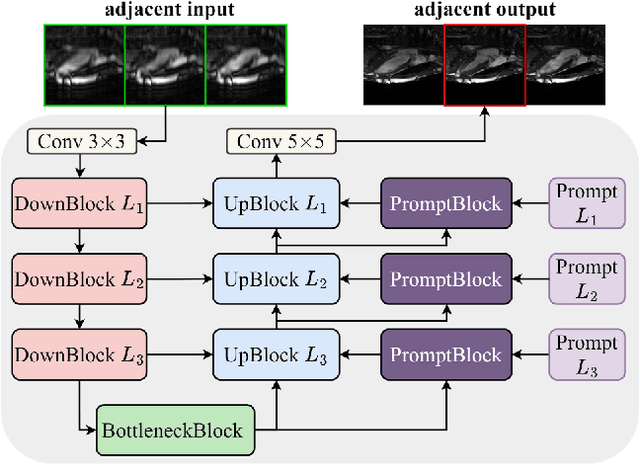
Cardiac MRI, crucial for evaluating heart structure and function, faces limitations like slow imaging and motion artifacts. Undersampling reconstruction, especially data-driven algorithms, has emerged as a promising solution to accelerate scans and enhance imaging performance using highly under-sampled data. Nevertheless, the scarcity of publicly available cardiac k-space datasets and evaluation platform hinder the development of data-driven reconstruction algorithms. To address this issue, we organized the Cardiac MRI Reconstruction Challenge (CMRxRecon) in 2023, in collaboration with the 26th International Conference on MICCAI. CMRxRecon presented an extensive k-space dataset comprising cine and mapping raw data, accompanied by detailed annotations of cardiac anatomical structures. With overwhelming participation, the challenge attracted more than 285 teams and over 600 participants. Among them, 22 teams successfully submitted Docker containers for the testing phase, with 7 teams submitted for both cine and mapping tasks. All teams use deep learning based approaches, indicating that deep learning has predominately become a promising solution for the problem. The first-place winner of both tasks utilizes the E2E-VarNet architecture as backbones. In contrast, U-Net is still the most popular backbone for both multi-coil and single-coil reconstructions. This paper provides a comprehensive overview of the challenge design, presents a summary of the submitted results, reviews the employed methods, and offers an in-depth discussion that aims to inspire future advancements in cardiac MRI reconstruction models. The summary emphasizes the effective strategies observed in Cardiac MRI reconstruction, including backbone architecture, loss function, pre-processing techniques, physical modeling, and model complexity, thereby providing valuable insights for further developments in this field.
LKFormer: Large Kernel Transformer for Infrared Image Super-Resolution
Jan 24, 2024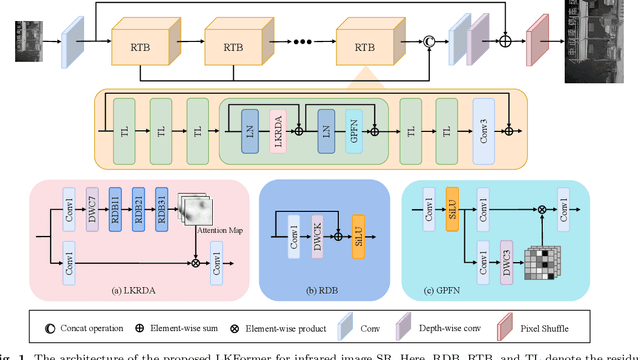
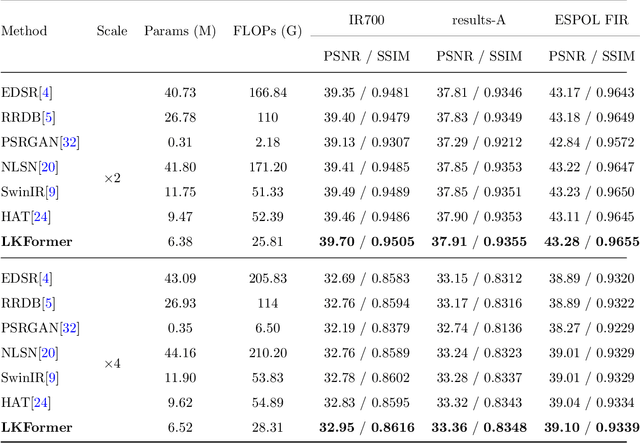


Given the broad application of infrared technology across diverse fields, there is an increasing emphasis on investigating super-resolution techniques for infrared images within the realm of deep learning. Despite the impressive results of current Transformer-based methods in image super-resolution tasks, their reliance on the self-attentive mechanism intrinsic to the Transformer architecture results in images being treated as one-dimensional sequences, thereby neglecting their inherent two-dimensional structure. Moreover, infrared images exhibit a uniform pixel distribution and a limited gradient range, posing challenges for the model to capture effective feature information. Consequently, we suggest a potent Transformer model, termed Large Kernel Transformer (LKFormer), to address this issue. Specifically, we have designed a Large Kernel Residual Attention (LKRA) module with linear complexity. This mainly employs depth-wise convolution with large kernels to execute non-local feature modeling, thereby substituting the standard self-attentive layer. Additionally, we have devised a novel feed-forward network structure called Gated-Pixel Feed-Forward Network (GPFN) to augment the LKFormer's capacity to manage the information flow within the network. Comprehensive experimental results reveal that our method surpasses the most advanced techniques available, using fewer parameters and yielding considerably superior performance.The source code will be available at https://github.com/sad192/large-kernel-Transformer.
Abs-CAM: A Gradient Optimization Interpretable Approach for Explanation of Convolutional Neural Networks
Jul 08, 2022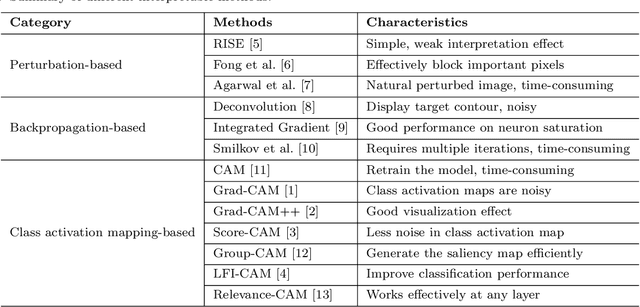
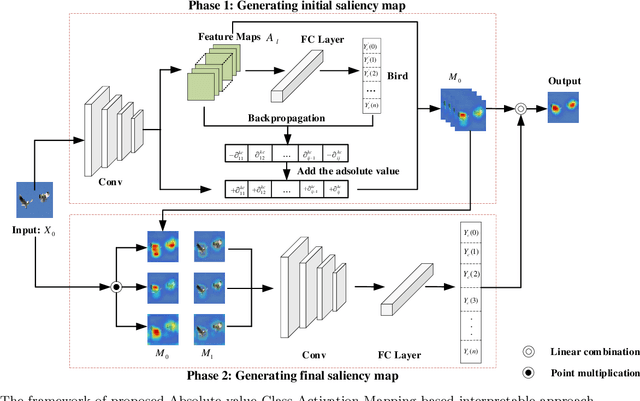

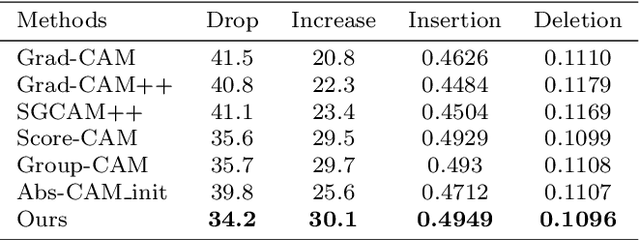
The black-box nature of Deep Neural Networks (DNNs) severely hinders its performance improvement and application in specific scenes. In recent years, class activation mapping-based method has been widely used to interpret the internal decisions of models in computer vision tasks. However, when this method uses backpropagation to obtain gradients, it will cause noise in the saliency map, and even locate features that are irrelevant to decisions. In this paper, we propose an Absolute value Class Activation Mapping-based (Abs-CAM) method, which optimizes the gradients derived from the backpropagation and turns all of them into positive gradients to enhance the visual features of output neurons' activation, and improve the localization ability of the saliency map. The framework of Abs-CAM is divided into two phases: generating initial saliency map and generating final saliency map. The first phase improves the localization ability of the saliency map by optimizing the gradient, and the second phase linearly combines the initial saliency map with the original image to enhance the semantic information of the saliency map. We conduct qualitative and quantitative evaluation of the proposed method, including Deletion, Insertion, and Pointing Game. The experimental results show that the Abs-CAM can obviously eliminate the noise in the saliency map, and can better locate the features related to decisions, and is superior to the previous methods in recognition and localization tasks.