 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Tampering Detection Based on Shallow and Deep Feature Representation Learning
Oct 19, 2022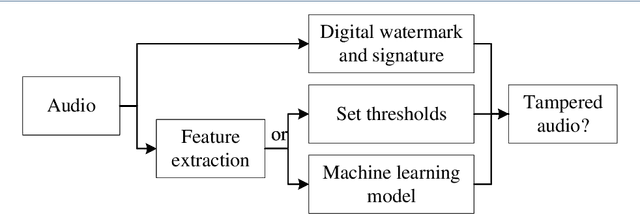

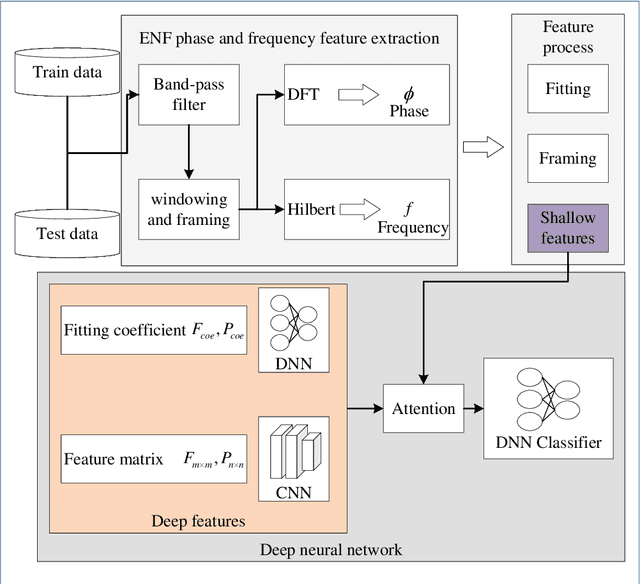

Digital audio tampering detection can be used to verify the authenticity of digital audio. However, most current methods use standard electronic network frequency (ENF) databases for visual comparison analysis of ENF continuity of digital audio or perform feature extraction for classification by machine learning methods. ENF databases are usually tricky to obtain, visual methods have weak feature representation, and machine learning methods have more information loss in features, resulting in low detection accuracy. This paper proposes a fusion method of shallow and deep features to fully use ENF information by exploiting the complementary nature of features at different levels to more accurately describe the changes in inconsistency produced by tampering operations to raw digital audio. The method achieves 97.03% accuracy on three classic databases: Carioca 1, Carioca 2, and New Spanish. In addition, we have achieved an accuracy of 88.31% on the newly constructed database GAUDI-DI. Experimental results show that the proposed method is superior to the state-of-the-art method.
Digital Audio Tampering Detection Based on ENF Spatio-temporal Features Representation Learning
Aug 25, 2022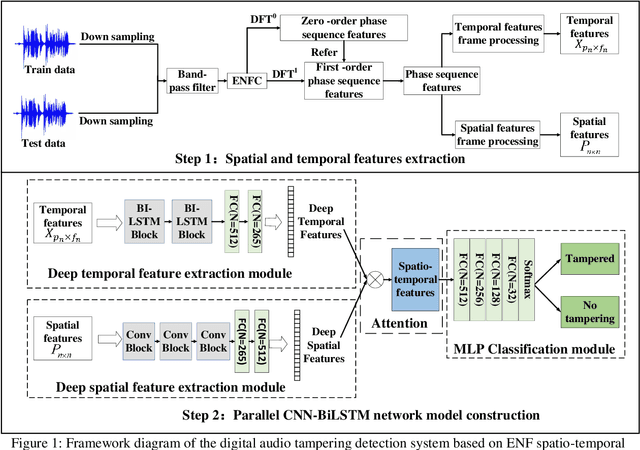
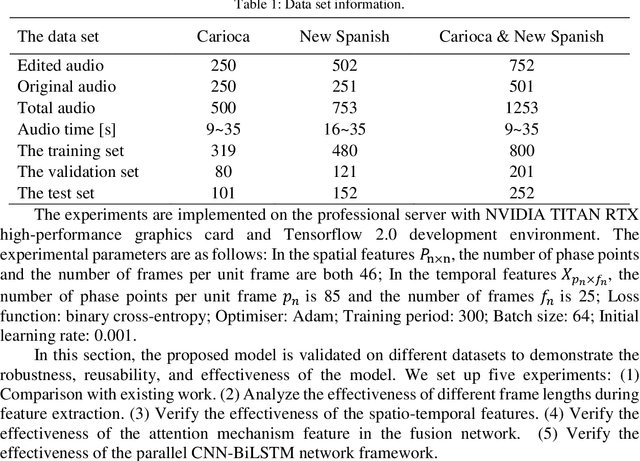
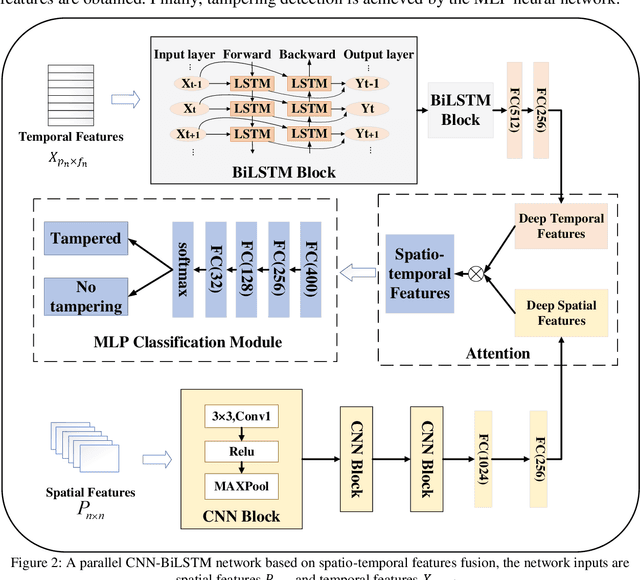
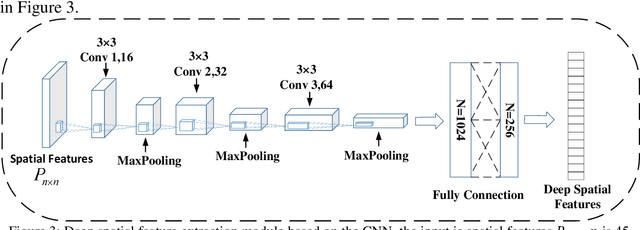
Most digital audio tampering detection methods based on electrical network frequency (ENF) only utilize the static spatial information of ENF, ignoring the variation of ENF in time series, which limit the ability of ENF feature representation and reduce the accuracy of tampering detection. This paper proposes a new method for digital audio tampering detection based on ENF spatio-temporal features representation learning. A parallel spatio-temporal network model is constructed using CNN and BiLSTM, which deeply extracts ENF spatial feature information and ENF temporal feature information to enhance the feature representation capability to improve the tampering detection accuracy. In order to extract the spatial and temporal features of the ENF, this paper firstly uses digital audio high-precision Discrete Fourier Transform analysis to extract the phase sequences of the ENF. The unequal phase series is divided into frames by adaptive frame shifting to obtain feature matrices of the same size to represent the spatial features of the ENF. At the same time, the phase sequences are divided into frames based on ENF time changes information to represent the temporal features of the ENF. Then deep spatial and temporal features are further extracted using CNN and BiLSTM respectively, and an attention mechanism is used to adaptively assign weights to the deep spatial and temporal features to obtain spatio-temporal features with stronger representation capability. Finally, the deep neural network is used to determine whether the audio has been tampered with. The experimental results show that the proposed method improves the accuracy by 2.12%-7.12% compared with state-of-the-art methods under the public database Carioca, New Spanish.