 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Training-Free Guess What Vision Language Model from Snippets to Open-Vocabulary Object Detection
Jan 21, 2026Open-Vocabulary Object Detection (OVOD) aims to develop the capability to detect anything. Although myriads of large-scale pre-training efforts have built versatile foundation models that exhibit impressive zero-shot capabilities to facilitate OVOD, the necessity of creating a universal understanding for any object cognition according to already pretrained foundation models is usually overlooked. Therefore, in this paper, a training-free Guess What Vision Language Model, called GW-VLM, is proposed to form a universal understanding paradigm based on our carefully designed Multi-Scale Visual Language Searching (MS-VLS) coupled with Contextual Concept Prompt (CCP) for OVOD. This approach can engage a pre-trained Vision Language Model (VLM) and a Large Language Model (LLM) in the game of "guess what". Wherein, MS-VLS leverages multi-scale visual-language soft-alignment for VLM to generate snippets from the results of class-agnostic object detection, while CCP can form the concept of flow referring to MS-VLS and then make LLM understand snippets for OVOD. Finally, the extensive experiments are carried out on natural and remote sensing datasets, including COCO val, Pascal VOC, DIOR, and NWPU-10, and the results indicate that our proposed GW-VLM can achieve superior OVOD performance compared to the-state-of-the-art methods without any training step.
EarthGPT-X: Enabling MLLMs to Flexibly and Comprehensively Understand Multi-Source Remote Sensing Imagery
Apr 17, 2025Recent advances in the visual-language area have developed natural multi-modal large language models (MLLMs) for spatial reasoning through visual prompting. However, due to remote sensing (RS) imagery containing abundant geospatial information that differs from natural images, it is challenging to effectively adapt natural spatial models to the RS domain. Moreover, current RS MLLMs are limited in overly narrow interpretation levels and interaction manner, hindering their applicability in real-world scenarios. To address those challenges, a spatial MLLM named EarthGPT-X is proposed, enabling a comprehensive understanding of multi-source RS imagery, such as optical, synthetic aperture radar (SAR), and infrared. EarthGPT-X offers zoom-in and zoom-out insight, and possesses flexible multi-grained interactive abilities. Moreover, EarthGPT-X unifies two types of critical spatial tasks (i.e., referring and grounding) into a visual prompting framework. To achieve these versatile capabilities, several key strategies are developed. The first is the multi-modal content integration method, which enhances the interplay between images, visual prompts, and text instructions. Subsequently, a cross-domain one-stage fusion training strategy is proposed, utilizing the large language model (LLM) as a unified interface for multi-source multi-task learning. Furthermore, by incorporating a pixel perception module, the referring and grounding tasks are seamlessly unified within a single framework. In addition, the experiments conducted demonstrate the superiority of the proposed EarthGPT-X in multi-grained tasks and its impressive flexibility in multi-modal interaction, revealing significant advancements of MLLM in the RS field.
EarthMarker: Visual Prompt Learning for Region-level and Point-level Remote Sensing Imagery Comprehension
Jul 20, 2024



Recent advances in visual prompting in the natural image area have allowed users to interact with artificial intelligence (AI) tools through various visual marks such as box, point, and free-form shapes. However, due to the significant difference between the natural and remote sensing (RS) images, existing visual prompting models face challenges in RS scenarios. Moreover, RS MLLMs mainly focus on interpreting image-level RS data and only support interaction with language instruction, restricting flexibility applications in the real world. To address those limitations, the first visual prompting model named EarthMarker is proposed, which excels in image-level, region-level, and point-level RS imagery interpretation. Specifically, the visual prompts alongside images and text instruction input into the large language model (LLM), adapt models toward specific predictions and tasks. Subsequently, a sharing visual encoding method is introduced to refine multi-scale image features and visual prompt information uniformly. Furthermore, to endow the EarthMarker with versatile multi-granularity visual perception abilities, the cross-domain phased learning strategy is developed, and the disjoint parameters are optimized in a lightweight manner by leveraging both the natural and RS domain-specific knowledge. In addition, to tackle the lack of RS visual prompting data, a dataset named RSVP featuring multi-modal fine-grained visual prompting instruction is constructed. Extensive experiments are conducted to demonstrate the proposed EarthMarker's competitive performance, representing a significant advance in multi-granularity RS imagery interpretation under the visual prompting learning framework.
EarthMarker: A Visual Prompt Learning Framework for Region-level and Point-level Remote Sensing Imagery Comprehension
Jul 18, 2024Recent advances in visual prompting in the natural image area have allowed users to interact with artificial intelligence (AI) tools through various visual marks such as box, point, and free-form shapes. However, due to the significant difference between the natural and remote sensing (RS) images, existing visual prompting models face challenges in RS scenarios. Moreover, RS MLLMs mainly focus on interpreting image-level RS data and only support interaction with language instruction, restricting flexibility applications in the real world. To address those limitations, a novel visual prompting model named EarthMarker is proposed, which excels in image-level, region-level, and point-level RS imagery interpretation. Specifically, the visual prompts alongside images and text instruction input into the large language model (LLM), adapt models toward specific predictions and tasks. Subsequently, a sharing visual encoding method is introduced to refine multi-scale image features and visual prompt information uniformly. Furthermore, to endow the EarthMarker with versatile multi-granularity visual perception abilities, the cross-domain phased learning strategy is developed, and the disjoint parameters are optimized in a lightweight manner by leveraging both the natural and RS domain-specific knowledge. In addition, to tackle the lack of RS visual prompting data, a dataset named RSVP featuring multi-modal fine-grained visual prompting instruction is constructed. Extensive experiments are conducted to demonstrate the proposed EarthMarker's competitive performance, representing a significant advance in multi-granularity RS imagery interpretation under the visual prompting learning framework.
Popeye: A Unified Visual-Language Model for Multi-Source Ship Detection from Remote Sensing Imagery
Mar 06, 2024



Ship detection needs to identify ship locations from remote sensing (RS) scenes. However, due to different imaging payloads, various appearances of ships, and complicated background interference from the bird's eye view, it is difficult to set up a unified paradigm for achieving multi-source ship detection. Therefore, in this article, considering that the large language models (LLMs) emerge the powerful generalization ability, a novel unified visual-language model called Popeye is proposed for multi-source ship detection from RS imagery. First, to bridge the interpretation gap between multi-source images for ship detection, a novel image-instruction-answer way is designed to integrate the various ship detection ways (e.g., horizontal bounding box (HBB), oriented bounding box (OBB)) into a unified labeling paradigm. Then, in view of this, a cross-modal image interpretation method is developed for the proposed Popeye to enhance interactive comprehension ability between visual and language content, which can be easily migrated into any multi-source ship detection task. Subsequently, owing to objective domain differences, a knowledge adaption mechanism is designed to adapt the pre-trained visual-language knowledge from the nature scene into the RS domain for multi-source ship detection. In addition, the segment anything model (SAM) is also seamlessly integrated into the proposed Popeye to achieve pixel-level ship segmentation without additional training costs. Finally, extensive experiments are conducted on the newly constructed instruction dataset named MMShip, and the results indicate that the proposed Popeye outperforms current specialist, open-vocabulary, and other visual-language models for zero-shot multi-source ship detection.
EarthGPT: A Universal Multi-modal Large Language Model for Multi-sensor Image Comprehension in Remote Sensing Domain
Feb 05, 2024



Multi-modal large language models (MLLMs) have demonstrated remarkable success in vision and visual-language tasks within the natural image domain. Owing to the significant diversities between the natural and remote sensing (RS) images, the development of MLLMs in the RS domain is still in the infant stage. To fill the gap, a pioneer MLLM named EarthGPT integrating various multi-sensor RS interpretation tasks uniformly is proposed in this paper for universal RS image comprehension. In EarthGPT, three key techniques are developed including a visual-enhanced perception mechanism, a cross-modal mutual comprehension approach, and a unified instruction tuning method for multi-sensor multi-task in the RS domain. More importantly, a dataset named MMRS-1M featuring large-scale multi-sensor multi-modal RS instruction-following is constructed, comprising over 1M image-text pairs based on 34 existing diverse RS datasets and including multi-sensor images such as optical, synthetic aperture radar (SAR), and infrared. The MMRS-1M dataset addresses the drawback of MLLMs on RS expert knowledge and stimulates the development of MLLMs in the RS domain. Extensive experiments are conducted, demonstrating the EarthGPT's superior performance in various RS visual interpretation tasks compared with the other specialist models and MLLMs, proving the effectiveness of the proposed EarthGPT and offering a versatile paradigm for open-set reasoning tasks.
Consecutive Pretraining: A Knowledge Transfer Learning Strategy with Relevant Unlabeled Data for Remote Sensing Domain
Jul 08, 2022


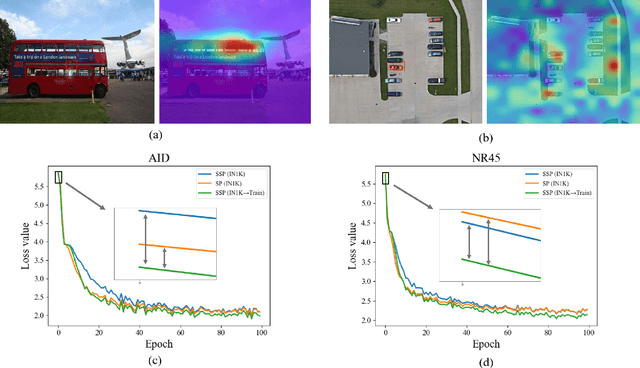
Currently, under supervised learning, a model pretrained by a large-scale nature scene dataset and then fine-tuned on a few specific task labeling data is the paradigm that has dominated the knowledge transfer learning. It has reached the status of consensus solution for task-aware model training in remote sensing domain (RSD). Unfortunately, due to different categories of imaging data and stiff challenges of data annotation, there is not a large enough and uniform remote sensing dataset to support large-scale pretraining in RSD. Moreover, pretraining models on large-scale nature scene datasets by supervised learning and then directly fine-tuning on diverse downstream tasks seems to be a crude method, which is easily affected by inevitable labeling noise, severe domain gaps and task-aware discrepancies. Thus, in this paper, considering the self-supervised pretraining and powerful vision transformer (ViT) architecture, a concise and effective knowledge transfer learning strategy called ConSecutive PreTraining (CSPT) is proposed based on the idea of not stopping pretraining in natural language processing (NLP), which can gradually bridge the domain gap and transfer knowledge from the nature scene domain to the RSD. The proposed CSPT also can release the huge potential of unlabeled data for task-aware model training. Finally, extensive experiments are carried out on twelve datasets in RSD involving three types of downstream tasks (e.g., scene classification, object detection and land cover classification) and two types of imaging data (e.g., optical and SAR). The results show that by utilizing the proposed CSPT for task-aware model training, almost all downstream tasks in RSD can outperform the previous method of supervised pretraining-then-fine-tuning and even surpass the state-of-the-art (SOTA) performance without any expensive labeling consumption and careful model design.
Linear Array Network for Low-light Image Enhancement
Jan 22, 2022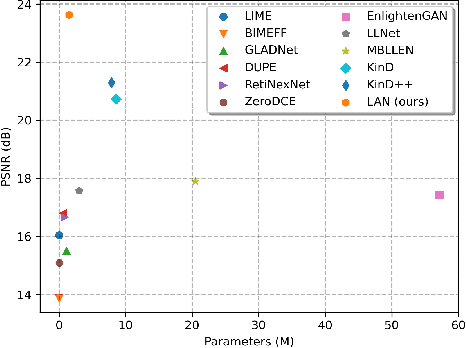
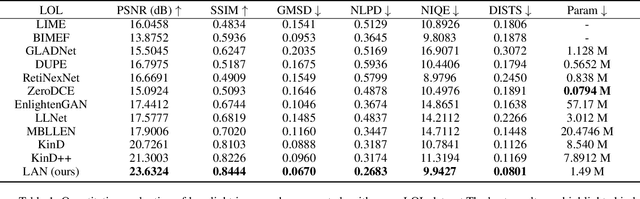
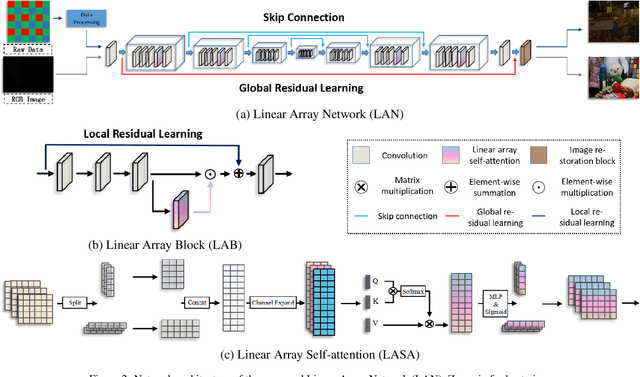
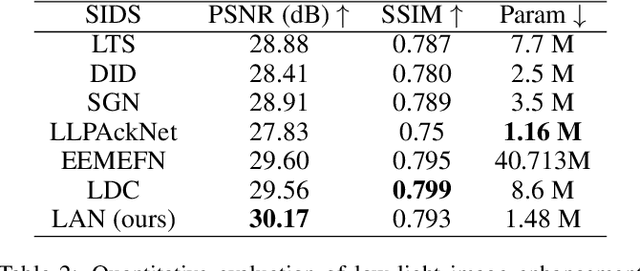
Convolution neural networks (CNNs) based methods have dominated the low-light image enhancement tasks due to their outstanding performance. However, the convolution operation is based on a local sliding window mechanism, which is difficult to construct the long-range dependencies of the feature maps. Meanwhile, the self-attention based global relationship aggregation methods have been widely used in computer vision, but these methods are difficult to handle high-resolution images because of the high computational complexity. To solve this problem, this paper proposes a Linear Array Self-attention (LASA) mechanism, which uses only two 2-D feature encodings to construct 3-D global weights and then refines feature maps generated by convolution layers. Based on LASA, Linear Array Network (LAN) is proposed, which is superior to the existing state-of-the-art (SOTA) methods in both RGB and RAW based low-light enhancement tasks with a smaller amount of parameters. The code is released in \url{https://github.com/cuiziteng/LASA_enhancement}.