 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleGAN of All Trades: Image Manipulation with Only Pretrained StyleGAN
Paper and Code

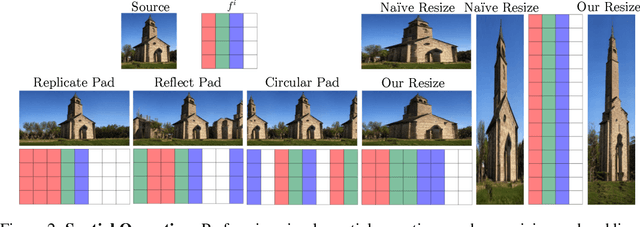


Recently, StyleGAN has enabled various image manipulation and editing tasks thanks to the high-quality generation and the disentangled latent space. However, additional architectures or task-specific training paradigms are usually required for different tasks. In this work, we take a deeper look at the spatial properties of StyleGAN. We show that with a pretrained StyleGAN along with some operations, without any additional architecture, we can perform comparably to the state-of-the-art methods on various tasks, including image blending, panorama generation, generation from a single image, controllable and local multimodal image to image translation, and attributes transfer. The proposed method is simple, effective, efficient, and applicable to any existing pretrained StyleGAN model.