 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Depth from a Single RGB Image
Sep 03, 2019



We describe a method that predicts, from a single RGB image, a depth map that describes the scene when a masked object is removed - we call this "counterfactual depth" that models hidden scene geometry together with the observations. Our method works for the same reason that scene completion works: the spatial structure of objects is simple. But we offer a much higher resolution representation of space than current scene completion methods, as we operate at pixel-level precision and do not rely on a voxel representation. Furthermore, we do not require RGBD inputs. Our method uses a standard encoder-decoder architecture, and with a decoder modified to accept an object mask. We describe a small evaluation dataset that we have collected, which allows inference about what factors affect reconstruction most strongly. Using this dataset, we show that our depth predictions for masked objects are better than other baselines.
SafetyNet: Detecting and Rejecting Adversarial Examples Robustly
Aug 15, 2017

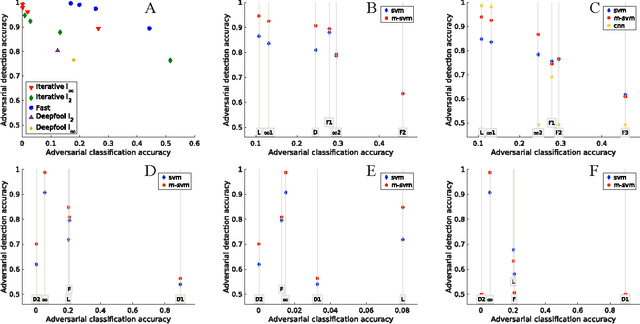
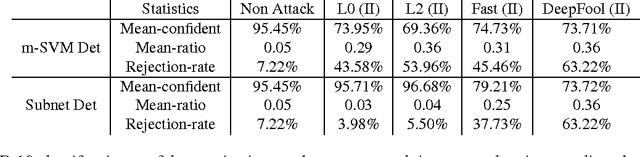
We describe a method to produce a network where current methods such as DeepFool have great difficulty producing adversarial samples. Our construction suggests some insights into how deep networks work. We provide a reasonable analyses that our construction is difficult to defeat, and show experimentally that our method is hard to defeat with both Type I and Type II attacks using several standard networks and datasets. This SafetyNet architecture is used to an important and novel application SceneProof, which can reliably detect whether an image is a picture of a real scene or not. SceneProof applies to images captured with depth maps (RGBD images) and checks if a pair of image and depth map is consistent. It relies on the relative difficulty of producing naturalistic depth maps for images in post processing. We demonstrate that our SafetyNet is robust to adversarial examples built from currently known attacking approaches.
Authoring image decompositions with generative models
Dec 05, 2016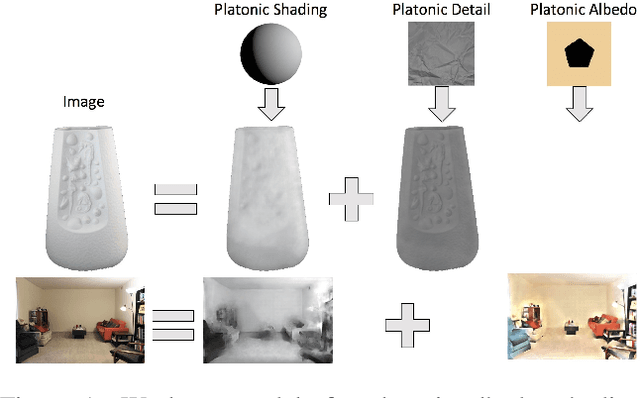
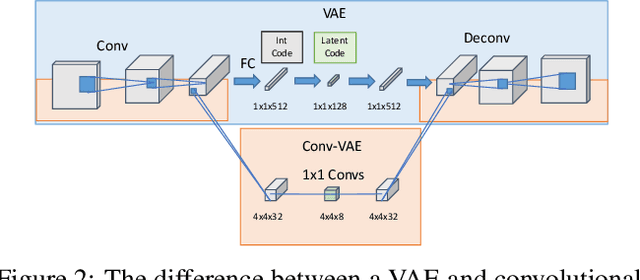
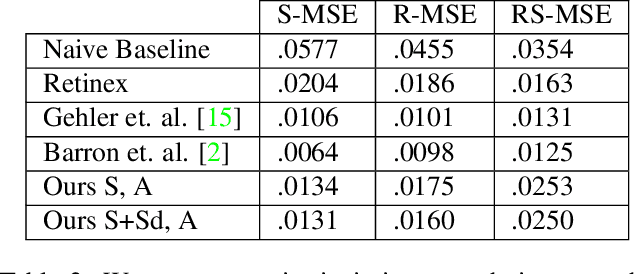
We show how to extend traditional intrinsic image decompositions to incorporate further layers above albedo and shading. It is hard to obtain data to learn a multi-layer decomposition. Instead, we can learn to decompose an image into layers that are "like this" by authoring generative models for each layer using proxy examples that capture the Platonic ideal (Mondrian images for albedo; rendered 3D primitives for shading; material swatches for shading detail). Our method then generates image layers, one from each model, that explain the image. Our approach rests on innovation in generative models for images. We introduce a Convolutional Variational Auto Encoder (conv-VAE), a novel VAE architecture that can reconstruct high fidelity images. The approach is general, and does not require that layers admit a physical interpretation.