 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary Cues for 3D Object Shape Recovery
Dec 24, 2019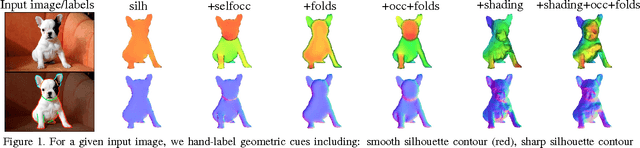
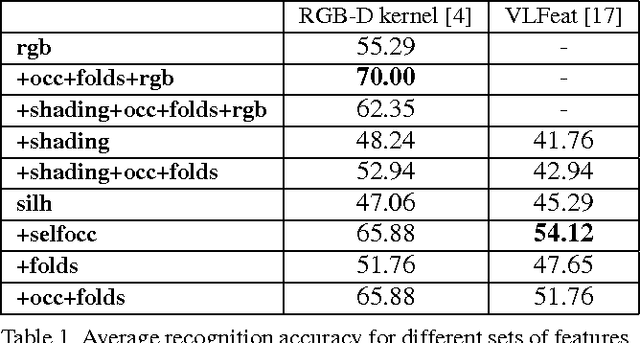


Early work in computer vision considered a host of geometric cues for both shape reconstruction and recognition. However, since then, the vision community has focused heavily on shading cues for reconstruction, and moved towards data-driven approaches for recognition. In this paper, we reconsider these perhaps overlooked "boundary" cues (such as self occlusions and folds in a surface), as well as many other established constraints for shape reconstruction. In a variety of user studies and quantitative tasks, we evaluate how well these cues inform shape reconstruction (relative to each other) in terms of both shape quality and shape recognition. Our findings suggest many new directions for future research in shape reconstruction, such as automatic boundary cue detection and relaxing assumptions in shape from shading (e.g. orthographic projection, Lambertian surfaces).
Detecting Anomalous Faces with 'No Peeking' Autoencoders
Feb 15, 2018
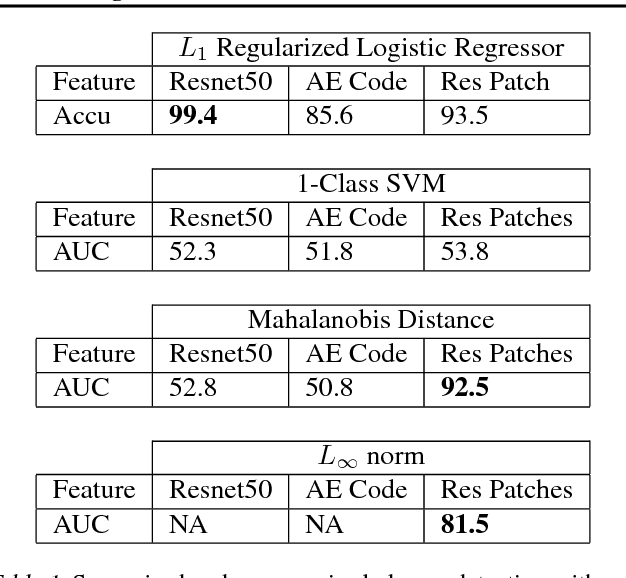

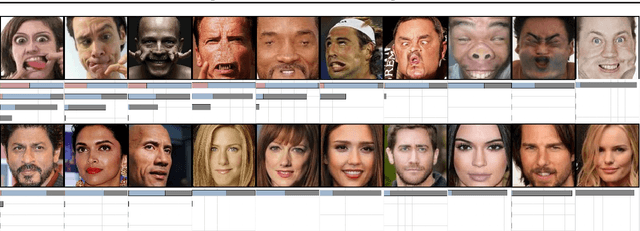
Detecting anomalous faces has important applications. For example, a system might tell when a train driver is incapacitated by a medical event, and assist in adopting a safe recovery strategy. These applications are demanding, because they require accurate detection of rare anomalies that may be seen only at runtime. Such a setting causes supervised methods to perform poorly. We describe a method for detecting an anomalous face image that meets these requirements. We construct a feature vector that reliably has large entries for anomalous images, then use various simple unsupervised methods to score the image based on the feature. Obvious constructions (autoencoder codes; autoencoder residuals) are defeated by a 'peeking' behavior in autoencoders. Our feature construction removes rectangular patches from the image, predicts the likely content of the patch conditioned on the rest of the image using a specially trained autoencoder, then compares the result to the image. High scores suggest that the patch was difficult for an autoencoder to predict, and so is likely anomalous. We demonstrate that our method can identify real anomalous face images in pools of typical images, taken from celeb-A, that is much larger than usual in state-of-the-art experiments. A control experiment based on our method with another set of normal celebrity images - a 'typical set', but nonceleb-A are not identified as anomalous; confirms this is not due to special properties of celeb-A.
Authoring image decompositions with generative models
Dec 05, 2016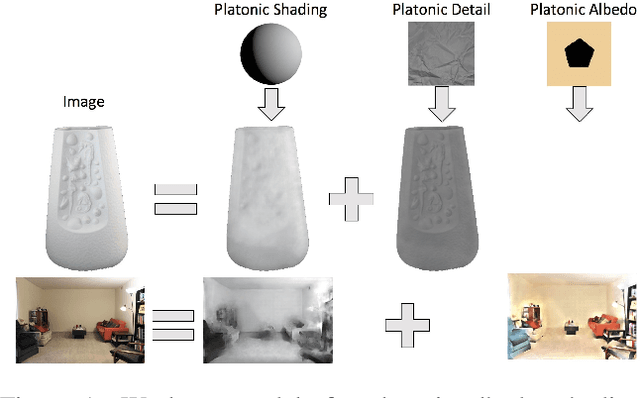
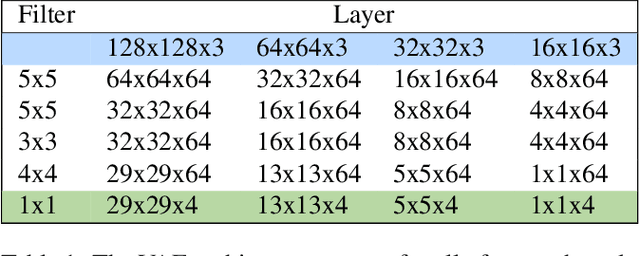
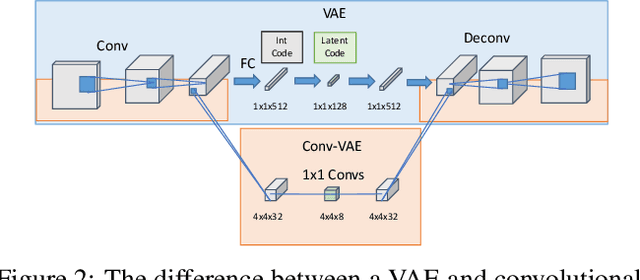
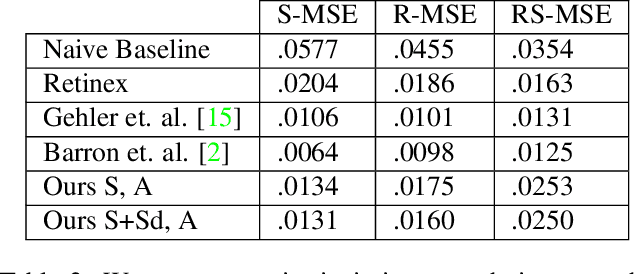
We show how to extend traditional intrinsic image decompositions to incorporate further layers above albedo and shading. It is hard to obtain data to learn a multi-layer decomposition. Instead, we can learn to decompose an image into layers that are "like this" by authoring generative models for each layer using proxy examples that capture the Platonic ideal (Mondrian images for albedo; rendered 3D primitives for shading; material swatches for shading detail). Our method then generates image layers, one from each model, that explain the image. Our approach rests on innovation in generative models for images. We introduce a Convolutional Variational Auto Encoder (conv-VAE), a novel VAE architecture that can reconstruct high fidelity images. The approach is general, and does not require that layers admit a physical interpretation.